
[AI 에이전트 2편] Tool use — LLM에게 첫 도구를 쥐여주다
AI 에이전트 5부작의 2편. 1편에서 '생각'만 하던 에이전트에 첫 도구(함수)를 쥐여줍니다. tool use가 'LLM의 함수 호출 의도 + 우리 코드의 실제 실행'이라는 원리(LLM은 Action 텍스트만 뱉고 실행은 코드가 함)를, claude 날것 출력으로 직접 보여줍니다. 도구를 이름·설명·입력 스키마로 정의하는 법과 설명을 잘 쓰는 실전 팁, tool_use/tool_result 왕복(Anthropic SDK 정식 코드 + API 키 없이 로컬 Claude CLI 재현)을 다룹니다. 도구 직접 정의·호출, 실제 호출(A 42g)·재사용(B·C)·없는 개체 에러 처리까지 터미널 캡처 6개로 담았고, 1편의 '판단 불가'가 실제 체중으로 채워지는 걸 보여줍니다. 예시 개체는 익명 A/B/C.
생각만 하던 에이전트, 이제 손을 준다
1편에서 에이전트는 "A개체 교배 돼?"라는 질문에 무엇을 알아내야 하는지까지 생각했지만, 정작 현재 체중을 몰라 "정보가 없어 판단 불가"로 끝났습니다.
생각은 하는데 손발이 없던 거죠. 이번 2편에서 그 손발 — 도구(함수)를 쥐여줍니다.
tool use(도구 사용, 함수 호출)는 에이전트의 핵심입니다. LLM이 필요할 때 함수를 불러 진짜 데이터를 가져오게 하는 거예요. 1편 ReAct 루프의 Action 자리에, 이번엔 진짜 함수를 꽂습니다.
2편에서 하는 것: tool use가 뭔지 → 도구를 어떻게 정의하나(이름·설명·입력 스키마) → tool_use/tool_result 왕복(Anthropic SDK 정식 + 로컬 CLI 재현) → 도구 하나(get_gecko_weight)를 붙여 실제 호출·재사용·에러 처리까지 캡처. 예시 개체는 익명 A/B/C(암컷 A 42g, 수컷 B 47g)로, 실제 사육 기록과는 무관합니다.

사람에게 공구를 쥐여주듯, 이번 편에선 LLM에게 첫 '도구'를 쥐여준다. (사진: Wikimedia Commons, CC0)
'LLM이 함수를 부른다'는 게 무슨 뜻인가요?
LLM은 함수를 직접 실행하지 못합니다. 대신 "이 함수를 이런 입력으로 불러줘"라는 의도를 구조화된 형식으로 내뱉을 뿐입니다. 실제 실행은 우리 코드가 합니다. 코드가 함수를 돌려 결과를 얻고, 그 결과를 다시 LLM에 돌려주면, LLM이 그걸 근거로 답을 만듭니다. 이 '의도 + 실행'의 합작이 tool use입니다.

처음엔 'LLM이 알아서 함수를 실행하나?' 했는데, 아니더라고요. LLM은 "get_gecko_weight를 'A'로 불러줘"라고 말만 합니다. 그 말을 받아 진짜 함수를 돌리는 건 우리 코드예요. 이 분담을 이해하면 나머지는 쉽습니다.
백 마디 설명보다, LLM이 실제로 뭘 뱉는지 보면 바로 와닿습니다. 같은 질문을 주고 날것 출력을 받아봤어요.

보면 LLM은 Action: get_gecko_weight / Action Input: {"individual_id":"A"}라는 텍스트만 내놓고 멈춥니다. 실제 함수 실행도, 결과도 아직 없어요. 저 텍스트를 받아 함수를 돌리고 결과를 다시 넣어주는 게 우리 코드의 몫입니다. 이게 tool use의 전부예요.
도구를 붙이는 이유는 세 가지로 정리되더라고요. ① 최신·내 데이터(LLM이 모르는 우리 개체 체중 같은 것) ② 여러 단계 작업(조회→비교→판단) ③ 실제 행동(DB 쓰기·API 호출). 그냥 답하면 환각하기 쉬운 것들을, 도구가 사실로 묶어줍니다.
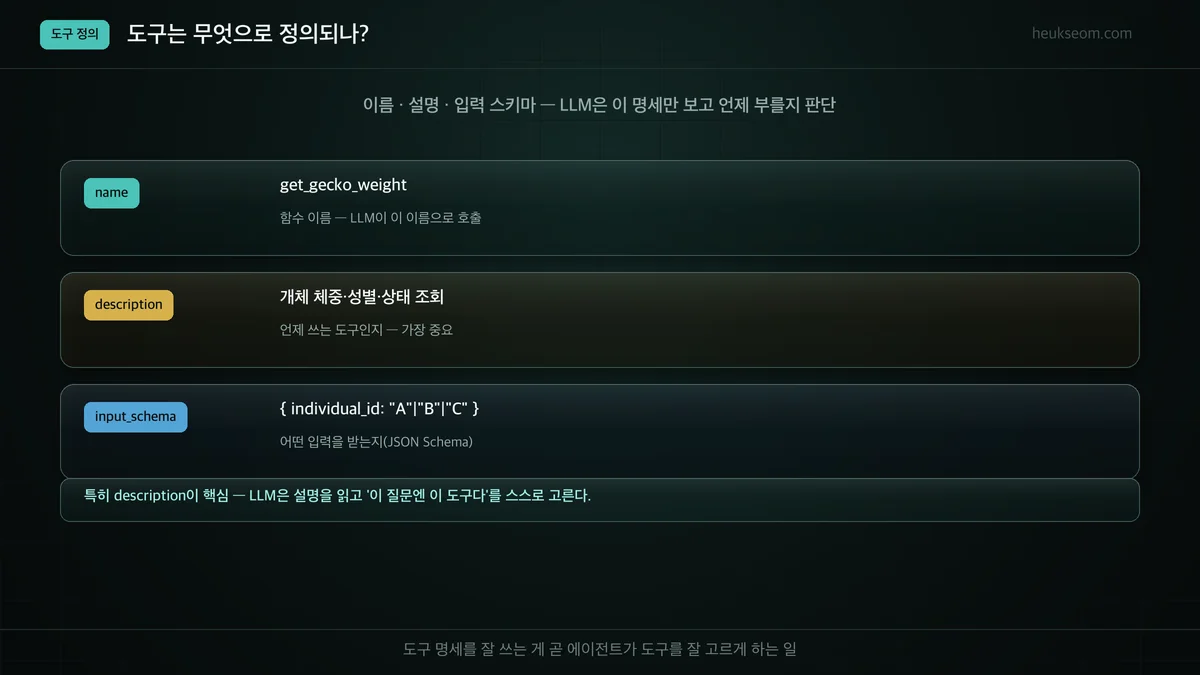
도구는 무엇으로 정의하나요?
도구 하나는 세 가지로 정의됩니다. 이름(name), 설명(description), 입력 스키마(input schema). LLM은 이 명세만 보고 '이 질문엔 이 도구를 이렇게 부르면 되겠다'를 스스로 판단합니다. 특히 설명이 중요합니다. 설명이 모호하면 LLM이 도구를 엉뚱하게 고르거나 아예 안 씁니다.
도구는 거창한 게 아니라 그냥 파이썬 함수입니다. 직접 정의하고 호출해봤어요. 정상 입력엔 데이터가, 없는 개체엔 에러가 그대로 나옵니다.

여기서 제가 신경 쓴 건 설명(description)이에요. "체중 조회"처럼 막연하게 쓰면 LLM이 언제 부를지 헷갈려 합니다. "개체(A/B/C)의 현재 체중·성별·상태를 조회한다"처럼 무엇을·어떤 입력으로가 분명해야, LLM이 질문을 보고 이 도구를 정확히 골라요. 도구가 안 불리면 십중팔구 설명이 모호한 거더라고요. ㅎㅎ
실습 — 도구 정의 + Anthropic SDK 정식 tool use (셀 1)
import anthropic
# 1) 도구 정의 — 이름·설명·입력 스키마
tools = [{
"name": "get_gecko_weight",
"description": "개체(A/B/C)의 현재 체중(g)·성별·상태를 조회한다.",
"input_schema": {
"type": "object",
"properties": {"individual_id": {"type": "string", "enum": ["A", "B", "C"]}},
"required": ["individual_id"],
},
}]
client = anthropic.Anthropic() # API 키 필요
msg = client.messages.create(
model="claude-haiku-4-5", max_tokens=512, tools=tools,
messages=[{"role": "user", "content": "A개체 지금 교배 가능한 체중이야?"}],
)
# msg.content 에 tool_use 블록이 옴 → name/input 확인
print(msg.stop_reason) # "tool_use"이게 Anthropic SDK의 정식 방식입니다(API 키 필요). LLM은 tool_use 블록으로 "get_gecko_weight를 individual_id='A'로 불러줘"를 돌려줍니다. 아직 실행은 안 됐어요 — 다음 셀에서 우리가 실행합니다.
호출하고 결과를 돌려주는 한 바퀴
tool use는 한 번의 왕복입니다. LLM이 tool_use 블록을 내면, 우리 코드가 그 함수를 실행해 결과를 얻고, tool_result 블록으로 다시 LLM에 돌려줍니다. 그러면 LLM이 결과를 근거로 최종 답을 만듭니다. SDK든 우리 CLI 루프든 이 왕복 구조는 똑같습니다.

이게 제가 지어낸 방식이 아니라, Anthropic 공식 문서에 나온 그대로예요. tool use 문서를 직접 열어보면 "Claude가 도구 호출이 필요하다고 판단하면 구조화된 호출을 돌려주고, 그 실행은 우리 앱이 한다"고 똑같이 설명합니다.
![Claude API 공식 문서 — Tool use with Claude 페이지(tools=[...] 예제)](/blog/agent-2-tool-use/capture_docs.webp)
Claude API 공식 문서 'Tool use with Claude' (출처: docs.anthropic.com / platform.claude.com)
실습 — tool_result 돌려주기 + 우리 CLI 루프 (셀 2)
# [SDK 정식] tool_use 결과를 실행해 tool_result로 돌려준다
def get_gecko_weight(individual_id):
db = {"A": {"sex": "female", "weight_g": 42, "status": "성체"}}
return db.get(individual_id, {"error": "없는 개체"})
tool_use = msg.content[-1] # tool_use 블록
result = get_gecko_weight(**tool_use.input) # 우리가 실행
followup = client.messages.create(
model="claude-haiku-4-5", max_tokens=512, tools=tools,
messages=[
{"role": "user", "content": "A개체 지금 교배 가능한 체중이야?"},
{"role": "assistant", "content": msg.content},
{"role": "user", "content": [{
"type": "tool_result", "tool_use_id": tool_use.id,
"content": str(result),
}]},
],
)
print(followup.content[0].text) # 42g, 45g 미달 → 증체 후
# [이 글의 캡처] API 키 없이 — claude -p 를 추론엔진으로 같은 왕복:
# Action: get_gecko_weight {"individual_id":"A"} ← LLM이 텍스트로
# Observation: {"weight_g": 42, ...} ← 파이썬이 실행해 되먹임
# Final Answer: ... ← 결과로 판단SDK는 tool_use/tool_result 블록을, 우리 CLI 루프는 Action/Observation 텍스트를 주고받습니다. 이름만 다르고 원리는 같습니다. 아래 캡처는 전부 CLI 루프 실제 실행입니다.
도구를 붙여 실제로 돌려보면?
이제 도구 하나(get_gecko_weight)를 붙여 ReAct 루프를 돌려봤습니다. LLM이 Action으로 함수를 부르고, 파이썬이 실행해 Observation으로 결과를 돌려주면, LLM이 그 숫자로 판단합니다. 같은 도구를 다른 입력으로 재사용하고, 없는 개체를 물었을 때 에러를 어떻게 다루는지도 함께 담았습니다.
먼저 A개체 한 건. Thought → Action → Observation(42g) → Final로 한 바퀴가 돕니다.

같은 도구를 입력만 바꿔 B개체(수컷)로 재사용. 함수 하나로 어느 개체든 조회됩니다.

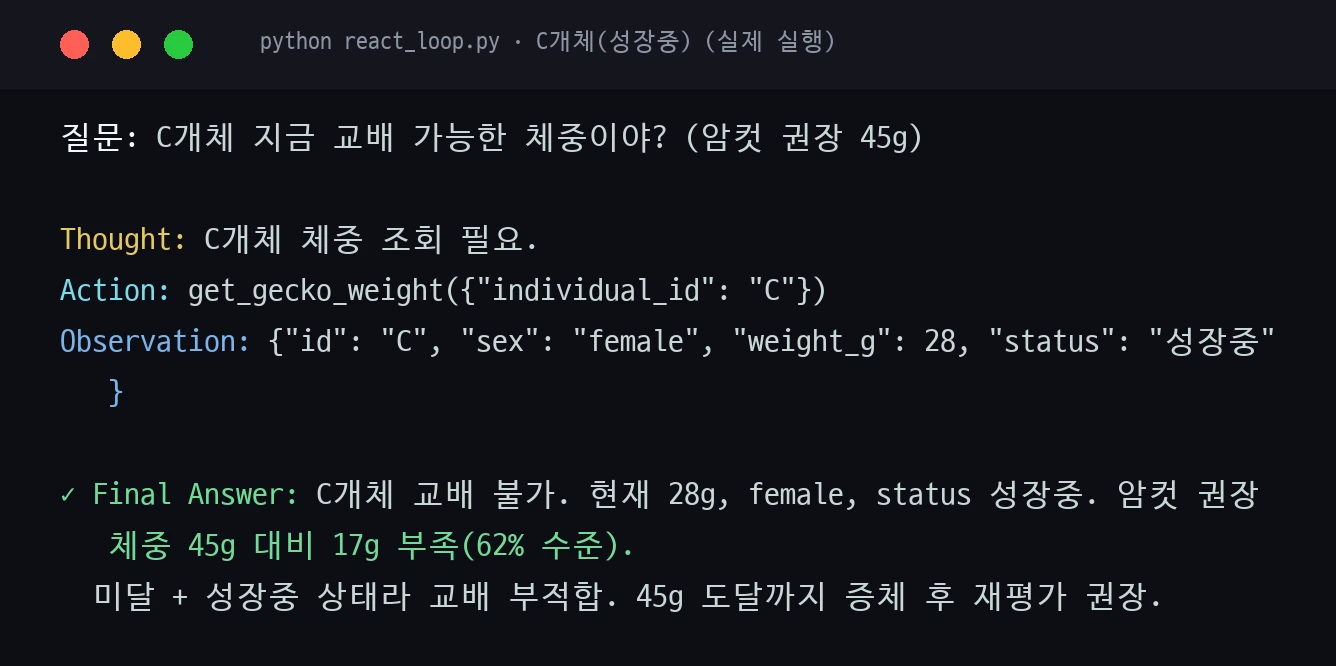
성장중인 C개체(28g)도 같은 도구로. 권장 45g에 한참 못 미치니 에이전트가 "성장 더 필요"로 판단합니다.
도구가 항상 성공하는 건 아니죠. 등록 안 된 D개체를 물으니, 도구가 {"error": "..."}를 반환하고, 에이전트는 그걸 보고 "D는 없다, A/B/C뿐"이라고 솔직히 답합니다. 에러도 결국 하나의 Observation입니다.

이 에러 처리가 의외로 중요해요. 도구는 실패할 수 있고(없는 입력, 네트워크 오류 등), 잘 만든 에이전트는 그 실패를 관찰로 받아 다음 행동을 정합니다. 크래시 대신 "그건 못 찾았어"라고 말하게 하는 거죠. ㅎㅎ
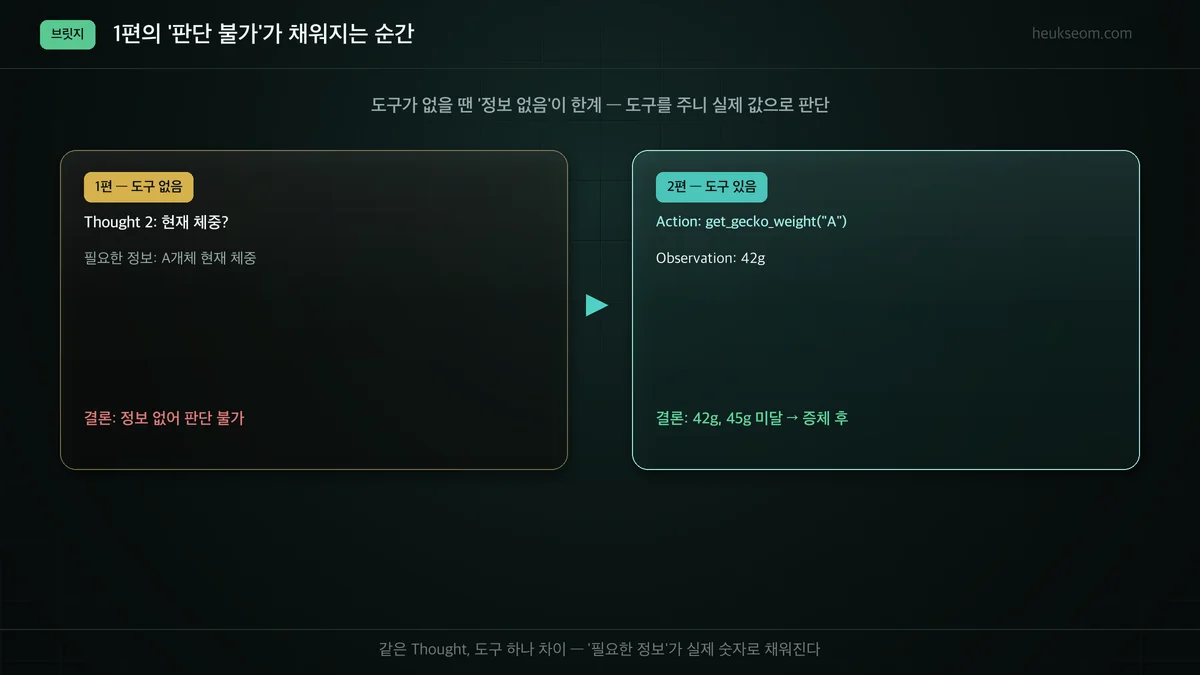
1편의 '판단 불가'는 어떻게 됐나요?
1편에서 "Thought 2: 현재 체중"은 알아내야 할 정보로 남았고, 도구가 없어 결국 "판단 불가"로 끝났습니다. 2편에서 도구를 붙이자 그 자리가 실제 숫자(42g)로 채워졌습니다. 같은 생각, 도구 하나 차이로 '정보 없음'이 '근거 있는 판단'이 됩니다.
정리
2편 핵심만 정리합니다.
- tool use = LLM의 '함수 호출 의도' + 우리 코드의 '실제 실행'. LLM은 직접 실행하지 않습니다.
- 도구는 이름·설명·입력 스키마로 정의하고, 특히 설명이 도구 선택을 좌우합니다.
- tool_use → 실행 → tool_result 왕복이 표준입니다(SDK든 CLI든 구조는 동일).
- 도구 결과로 1편의 '판단 불가'가 실제 숫자로 채워집니다.
- 에러도 하나의 Observation — 잘 만든 에이전트는 실패를 받아 다음 행동을 정합니다.

도구 하나를 붙였더니 에이전트가 진짜로 '일'을 하기 시작했습니다.
근데 도구가 하나뿐이면 한계가 있죠. 3편에서는 도구를 여러 개 주고, LLM이 스스로 골라 연쇄로 호출하게 합니다. "A개체랑 B개체 페어 돼?" 같은 다단계 질문을, 도구를 몇 번이고 반복해 풀어내는 진짜 멀티스텝 에이전트로요. ㅎㅎ