
[머신러닝 기초 1편] k-최근접 이웃(k-NN) — 주변을 보고 판단한다
가장 직관적인 머신러닝 알고리즘, k-NN. 데이터 포인트 간의 거리를 계산해 가장 가까운 k개의 이웃을 찾고 다수결로 분류합니다. 유클리드 거리 계산부터 k값 선택까지, 붓꽃 데이터셋으로 직접 구현해봅니다.
시작하며 — 머신러닝 기초 시리즈를 시작합니다
요즘은 누구나 개발을 하고, AI를 쓰는 시대가 되었습니다.
ChatGPT에 물어보고, Copilot이 코드를 짜주고, 클릭 몇 번으로 모델을 배포하는 것도 이젠 정말 어렵지 않은 영역이 되어버렸습니다.
근데 거기서 한 발 더 나아가면 AI는 쓰는 것을 넘어 응용할 수 있는 영역에 진입할 수 있다고 믿습니다.
사실 이용하는 건 누구나 할 수 있지만, 그것을 응용하고 최적화하는 건 아무나 못 합니다.
모델이 왜 틀리는지, 어떤 알고리즘이 이 데이터에 맞는지, 파라미터를 어떻게 잡아야 하는지 —
그건 엔지니어링의 영역이에요.
이 시리즈는 그 엔지니어링의 입구에 서보려는 사람들을 위한 기초 시리즈입니다.
거창한 목표 보다는 그냥, 지금보다 조금 더 알고 싶은 분들이나 흥미가 있는 분들이 짧은 아티클을 읽듯이 재밌게 봐주셨으면 합니다 ㅎㅎㅎ.
알고리즘 기초 시리즈에 이어, 이번엔 인공지능의 꽃, 머신러닝을 같이 들여다봅니다.
첫 번째 주제는 머신러닝 알고리즘 중에서도 가장 직관적인 k-최근접 이웃(k-NN)이에요.
원리는 딱 하나입니다.
"주변에 누가 있는지 보고 판단한다."
k-NN은 어떻게 동작하나요?
k-NN은 새 데이터가 들어오면 기존 모든 데이터와의 거리를 계산해서 가장 가까운 k개의 이웃을 찾고, 그 이웃들의 다수결로 분류를 결정하는 알고리즘이에요. 별도의 학습 과정 없이 거리 계산만으로 동작하는 가장 직관적인 머신러닝 방식입니다.
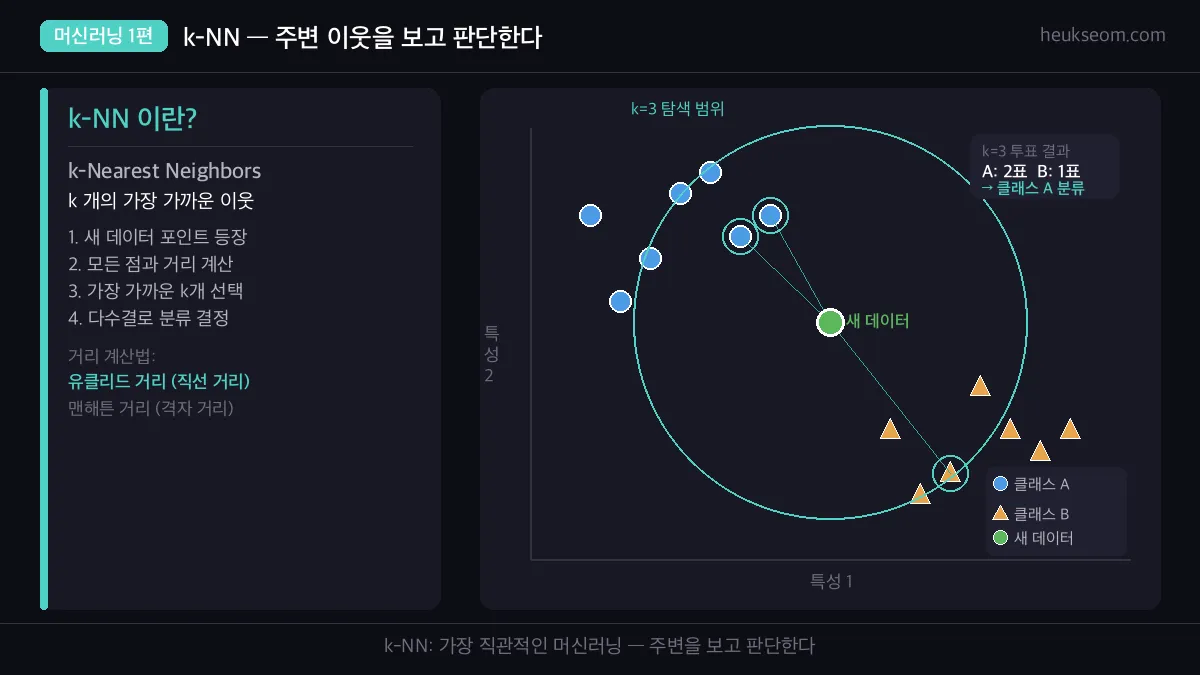
위 그림처럼 k-NN은 4단계로 동작합니다.
- 새 데이터 포인트가 들어온다
- 기존 모든 데이터와의 거리를 계산한다
- 가장 가까운 k개의 이웃을 선택한다
- k개 이웃의 다수결로 분류를 결정한다
k=3일 때 이웃 중 A가 2개, B가 1개라면 → 클래스 A로 분류됩니다.
별다른 학습 과정 없이, 거리 계산만으로 동작하는 게 k-NN의 핵심이에요.
거리는 어떻게 계산하나요?
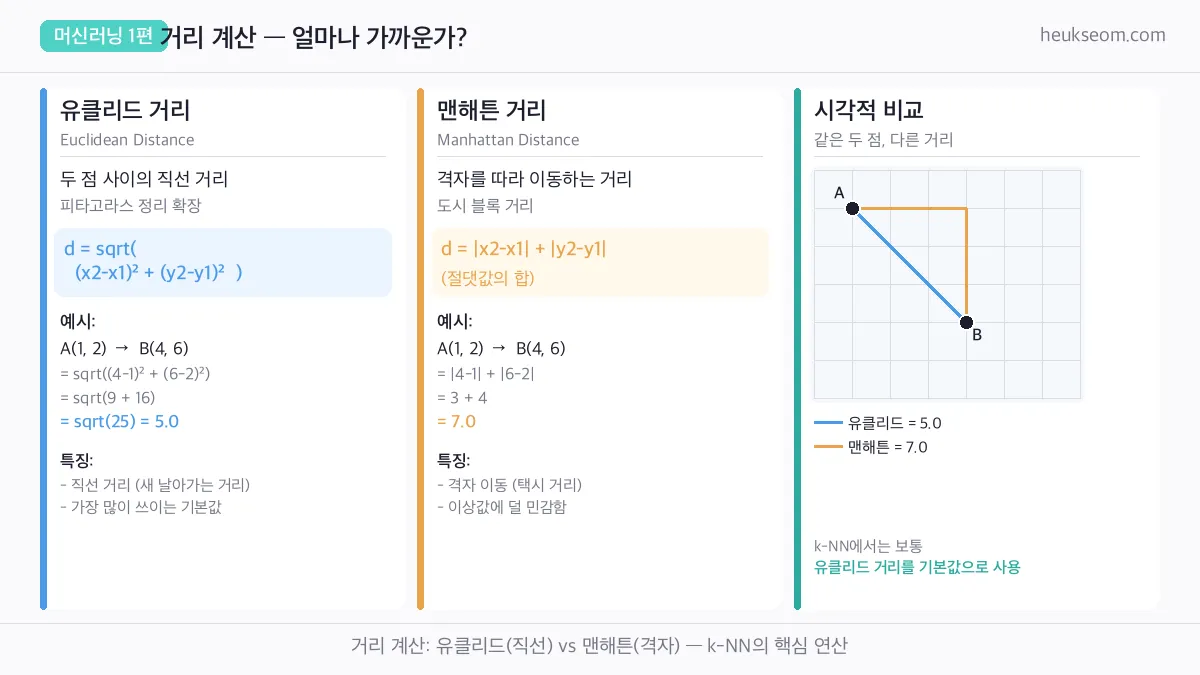
두 점 사이의 거리를 재는 방법은 여러 가지예요.
유클리드 거리는 두 점을 직선으로 이었을 때의 거리입니다.
피타고라스 정리를 그대로 확장한 거예요.
A(1,2)와 B(4,6)의 유클리드 거리는 sqrt((4-1)² + (6-2)²) = 5.0
맨해튼 거리는 격자를 따라 이동하는 거리예요.
택시가 도시 블록을 따라 움직이는 것처럼요.
같은 두 점의 맨해튼 거리는 |4-1| + |6-2| = 7.0
k-NN에서는 보통 유클리드 거리를 기본값으로 사용합니다.
k값은 어떻게 정하나요?

k값이 달라지면 결정 경계가 완전히 달라집니다.
- k=1 — 경계가 너무 복잡해서 노이즈에 민감 (과적합)
- k=5 — 안정적인 경계, 일반화 잘 됨 (적정)
- k=15 — 경계가 너무 단순해서 세부 패턴 무시 (과소적합)
실무에서는 보통 k=5~10에서 시작해서, 교차검증(Cross-Validation)으로 최적값을 찾아요.
직접 구현해보기 — 붓꽃(Iris) 분류
sklearn의 붓꽃 데이터셋으로 k-NN을 직접 돌려봤습니다.
꽃받침 길이/너비 2개 특성으로 3가지 품종을 분류하는 문제예요.
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report
iris = load_iris()
X, y = iris.data[:, :2], iris.target # 꽃받침 길이/너비만 사용
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
print(f"훈련 정확도: {knn.score(X_train, y_train):.3f}")
print(f"테스트 정확도: {knn.score(X_test, y_test):.3f}")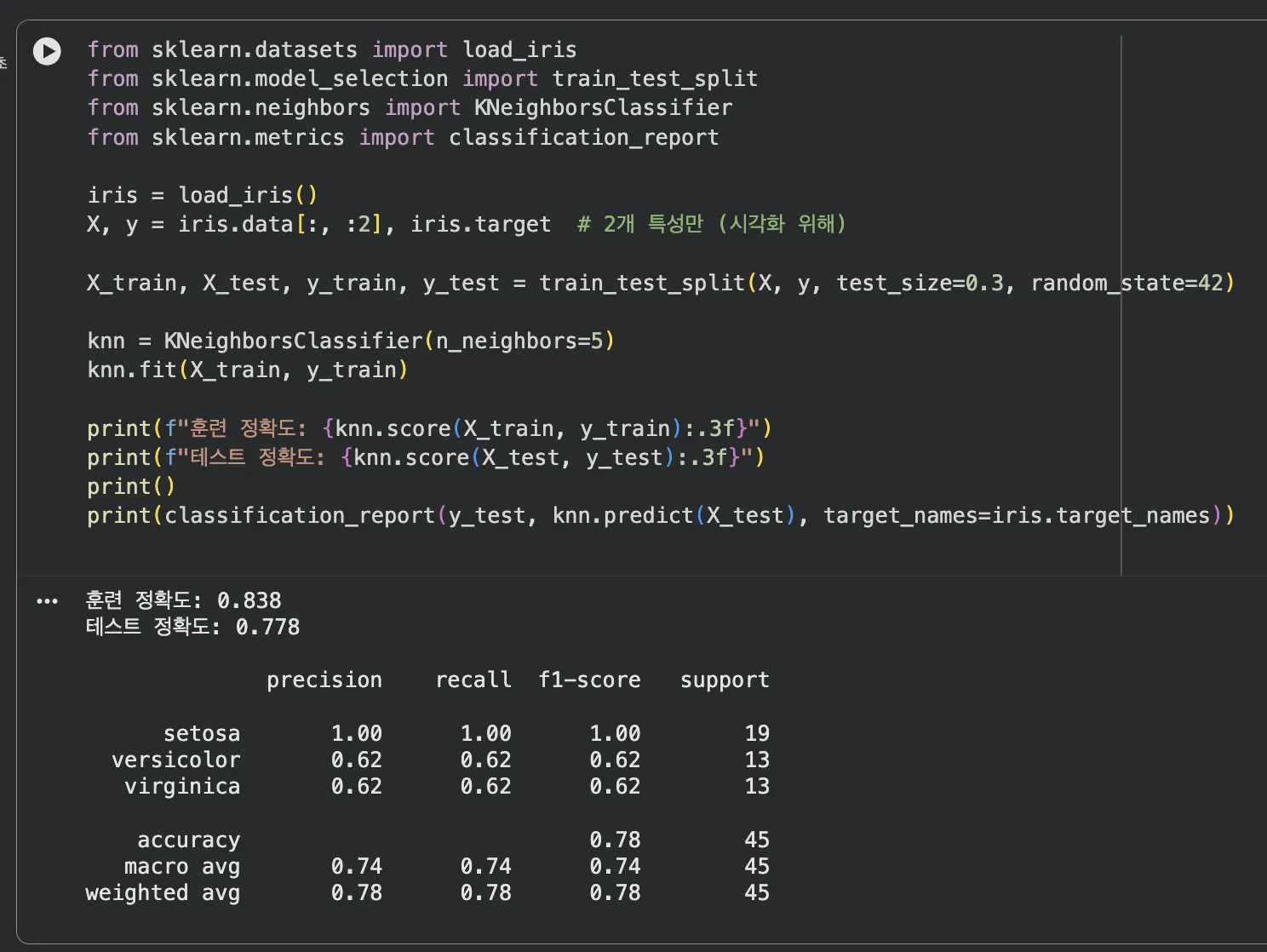
훈련 정확도 83.8%, 테스트 정확도 77.8%가 나왔어요.
setosa(파란색)는 완벽하게 분류했고, versicolor와 virginica는 꽃받침만으로는 경계가 모호해서 일부 혼동이 발생했습니다.
특성을 4개 모두 쓰면 정확도가 훨씬 올라가요.
결정 경계 시각화
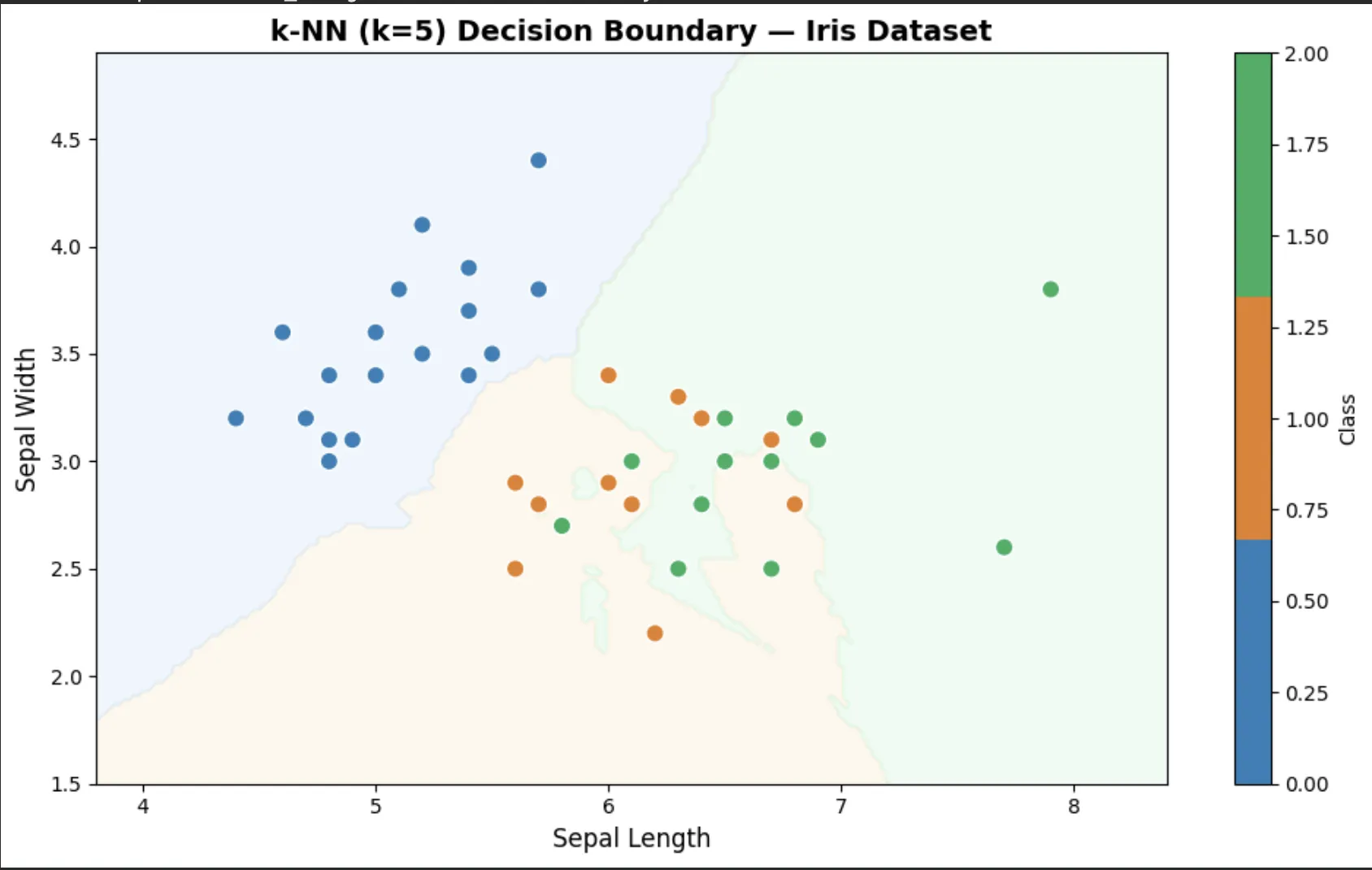
파란 영역은 setosa, 주황 영역은 versicolor, 초록 영역은 virginica로 분류되는 구간이에요.
경계 근처 데이터는 오분류가 생기지만, 전체적으로 꽤 잘 나뉘는 걸 볼 수 있어요.
k-NN 장단점 정리
- 장점 — 이해하기 쉽고 구현 간단, 학습 과정 없음, 다중 클래스 자연스럽게 처리
- 단점 — 데이터가 많아질수록 예측이 느림 (모든 거리 계산), 특성 스케일에 민감 (정규화 필수), 고차원 데이터에 약함
데이터가 크지 않고, 직관적인 분류가 필요할 때 k-NN은 여전히 좋은 선택이에요.
다음 편에서는 결정 트리(Decision Tree)를 다룹니다.
스무고개처럼 질문을 쪼개서 답을 찾는 알고리즘이에요.