
[머신러닝 기초 2편] 결정 트리 — 스무고개처럼 질문을 쪼개서 답을 찾는다
결정 트리는 데이터를 질문으로 쪼개 분류하는 알고리즘입니다. 지니 불순도와 정보 이득으로 최적 분할 기준을 찾고, 트리 깊이에 따른 과적합 문제까지 — 붓꽃 데이터셋으로 직접 구현해봅니다.
시작하며 — 스무고개 게임, 이겁니다 ㅋㅋ
스무고개 게임 다들 아시죠 (TMI: 소싯적 초등학교 2학년 때, 쉬는시간마다 친구들이랑 스무고개를 했던 기억이 나네요. ㅋㅋㅋ)
"동물인가요?" "네발인가요?" "털이 있나요?" — 질문을 계속 좁혀가다 보면 결국 답을 찾게 되죠.
결정 트리가 딱 이 방식으로 작동합니다.
데이터를 보면서 "이 조건이 맞으면 왼쪽, 아니면 오른쪽" 식으로 계속 분기해 나가고,
마지막 리프 노드에 도달하면 분류 결과를 냅니다.
직관적이고, 결과를 사람이 이해하기도 쉬워서 실무에서 자주 쓰입니다.
결정 트리 구조는 어떻게 생겼나요?
결정 트리는 루트 노드에서 시작해서 조건에 따라 왼쪽/오른쪽으로 분기하고, 리프 노드에 도달하면 최종 분류 결과를 내놓는 트리 구조예요. 스무고개처럼 질문을 쪼개가며 답을 찾는 방식이라 결과를 사람이 이해하기 쉽습니다.
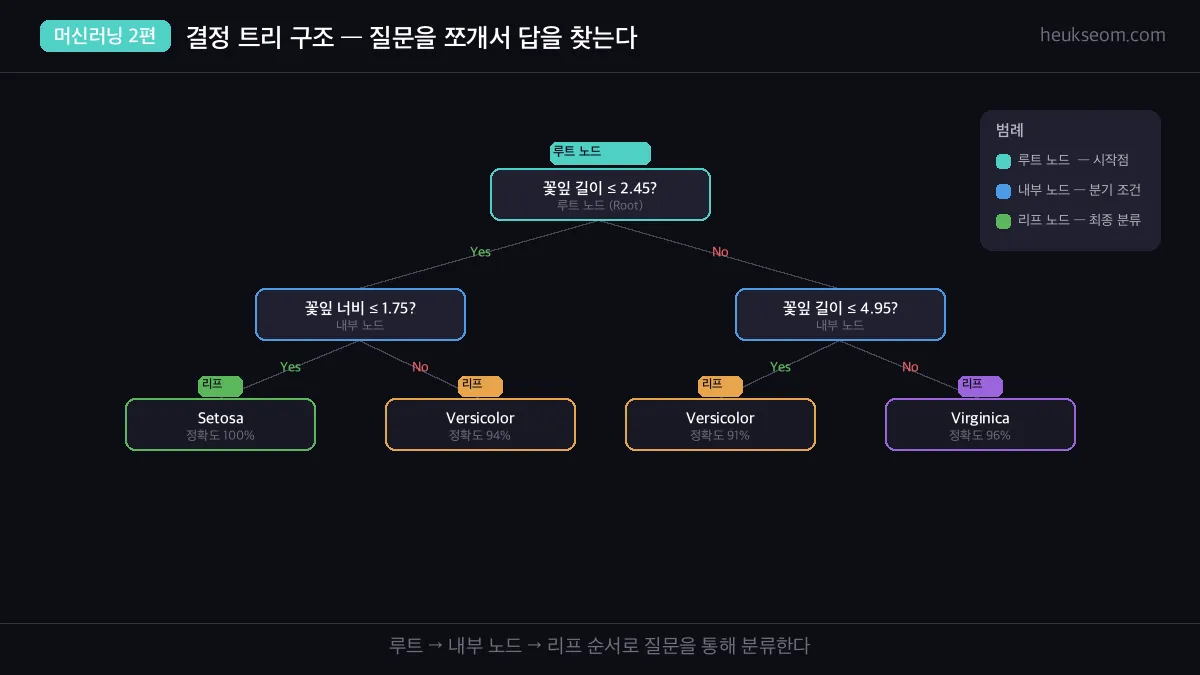
트리는 3가지 구성요소로 이루어져 있어요.
- 루트 노드 (Root) — 첫 번째 분기 조건. 가장 중요한 특성으로 시작합니다
- 내부 노드 (Internal Node) — 중간 분기 조건들
- 리프 노드 (Leaf) — 더 이상 분기하지 않는 최종 분류 결과
위 그림에서 "꽃잎 길이 ≤ 2.45?" 가 루트 노드예요.
Yes면 바로 Setosa로 분류(정확도 100%), No면 다음 질문으로 넘어갑니다.
어디서 분할하는 게 가장 좋은가요?
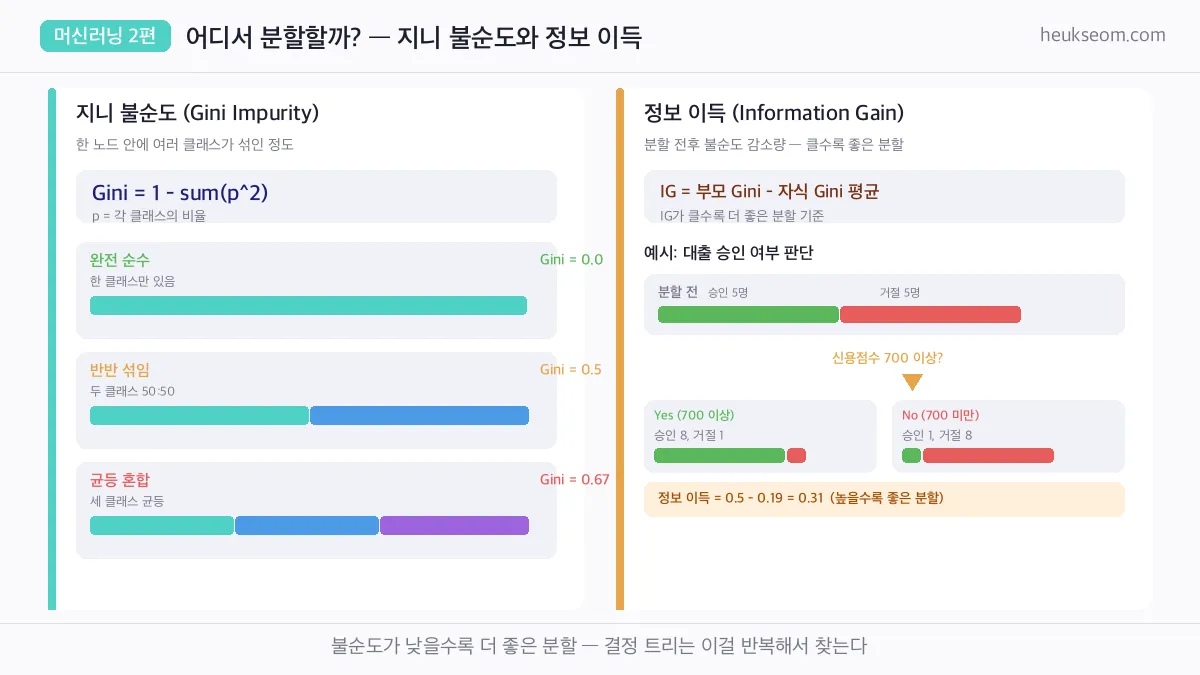
결정 트리의 핵심은 "어느 조건으로 분할하는 게 가장 좋을까?" 를 찾는 거예요.
이걸 판단하는 기준이 지니 불순도(Gini Impurity) 와 정보 이득(Information Gain) 입니다.
지니 불순도 — 한 노드 안에 여러 클래스가 섞인 정도
완전 순수(한 클래스만) = 0, 균등 혼합 = 최대
정보 이득 = 분할 전 불순도 − 분할 후 불순도 평균
이 값이 클수록 더 좋은 분할 기준
결정 트리는 모든 특성, 모든 임계값을 시도해보면서
정보 이득이 가장 큰 분할 기준을 선택합니다. 이걸 반복하는 거예요.
결정 트리도 과적합이 생기나요?
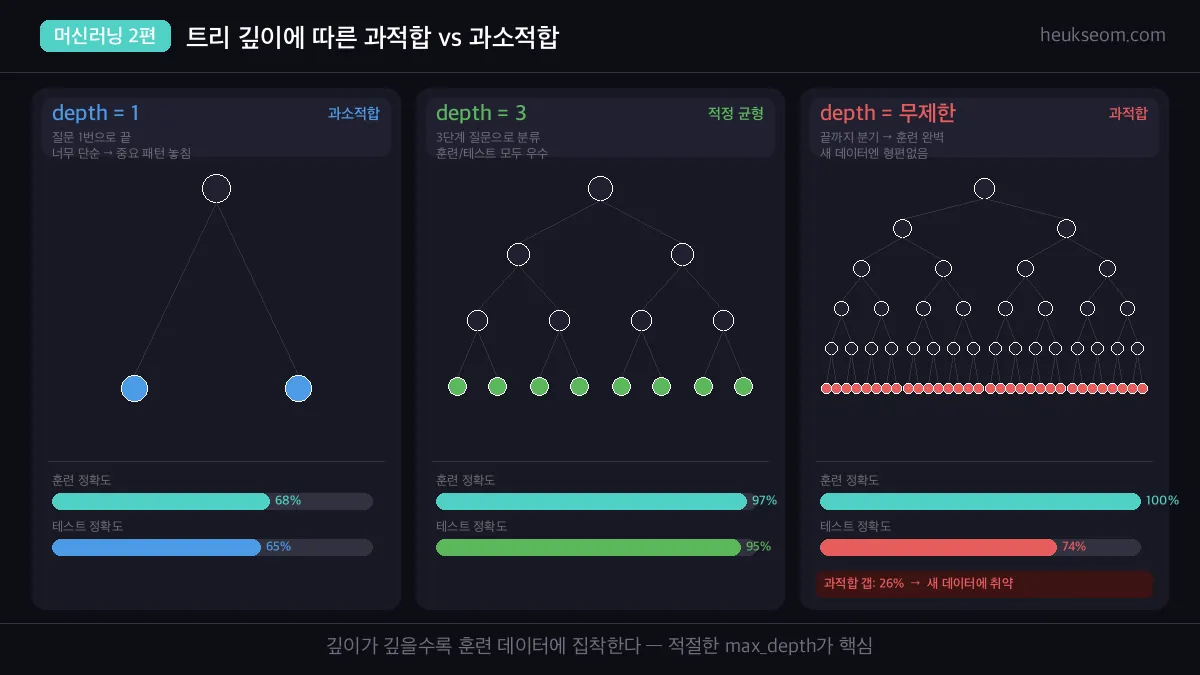
결정 트리의 가장 큰 약점은 과적합(Overfitting) 이에요.
제한 없이 분기하면 훈련 데이터는 100% 맞추지만, 새 데이터에는 형편없어집니다.
훈련 100% → 테스트 74% 라면 26%p의 과적합 갭이 생긴 거예요.
해결책은 간단합니다 — max_depth 로 트리 깊이를 제한하는 거예요.
코드로 직접 구현해보기
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42, stratify=y
)
# depth=3으로 제한
clf = DecisionTreeClassifier(max_depth=3, random_state=42)
clf.fit(X_train, y_train)
print(f"Train Accuracy: {clf.score(X_train, y_train):.4f}")
print(f"Test Accuracy: {clf.score(X_test, y_test):.4f}")
# 트리 구조 시각화
fig, ax = plt.subplots(figsize=(16, 8))
plot_tree(clf, feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True, fontsize=11, ax=ax)
plt.show()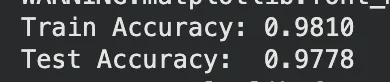
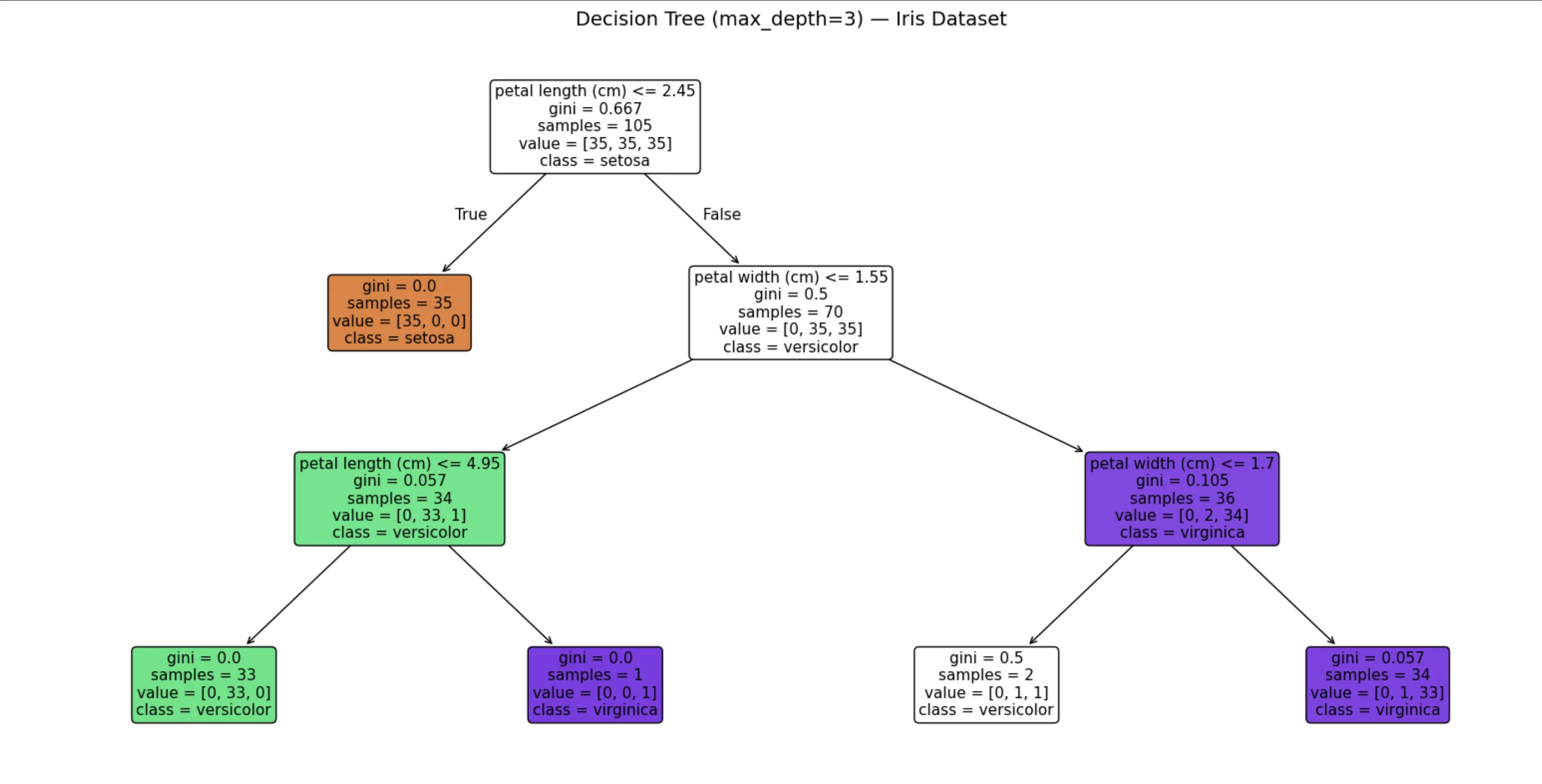
Train 98.1%, Test 97.8% — 갭이 거의 없어요.
max_depth=3 으로 적절히 제한한 덕분입니다.
장단점 정리
장점
- 결과를 사람이 이해하기 쉬움
- 데이터 전처리 거의 불필요
- 수치형 + 범주형 모두 처리 가능
단점
- 깊어질수록 과적합 위험
- 데이터 변화에 민감
- 단독으론 성능 한계 (→ 랜덤 포레스트로 보완)
정리
- 결정 트리는 데이터를 질문으로 분기해 분류 — 루트/내부/리프 노드로 구성
- 지니 불순도와 정보 이득으로 최적 분할 기준을 찾는다
max_depth로 과적합을 제어한다
다음 편에서는 S자 곡선으로 어떤 숫자든 0~1 사이 확률로 바꾸는 시그모이드 함수와 로지스틱 회귀를 다룹니다.