
[머신러닝 기초 3편] 로지스틱 회귀 — S자 곡선 하나로 분류를 끝낸다
로지스틱 회귀는 시그모이드 함수를 이용해 어떤 숫자든 0~1 사이 확률로 변환하고 분류합니다. 스팸 탐지, 암 진단, 신용 심사에 실제로 쓰이는 이 알고리즘을 유방암 데이터셋으로 직접 구현해봅니다.
시작하며 — "맞다/아니다"를 확률로 표현한다
카카오톡 단톡방에서 링크 눌렀는데 스팸이라고 차단된 경험 있나요? (없길 바랍니다...ㅎㅎㅎ)
아니면 유튜브에서 '이 영상 좋아할 것 같아요' 하고 딱 맞는 추천이 뜨거나.
이런 것들, 전부 AI가 "예 / 아니오"를 판단한 결과입니다.
스팸이다 / 아니다. 좋아할 것 같다 / 아닐 것 같다.
그런데 AI는 이 이분법적 결론을 어떻게 낼까요?
단순하게 딱 자르는 게 아니라, 실제로는 "스팸일 확률 92%" 같은 확률값으로 계산한 다음 분류합니다.
로지스틱 회귀는 바로 이 확률을 계산해서 분류하는 알고리즘이에요.
시그모이드 함수가 뭔가요?
시그모이드 함수는 어떤 숫자를 넣어도 0과 1 사이의 확률값으로 변환해주는 S자 곡선 함수예요. 로지스틱 회귀의 핵심으로, 입력값이 크면 1에 가까워지고 작으면 0에 가까워지면서 "양성일 확률이 몇 %인지"를 계산해줍니다.
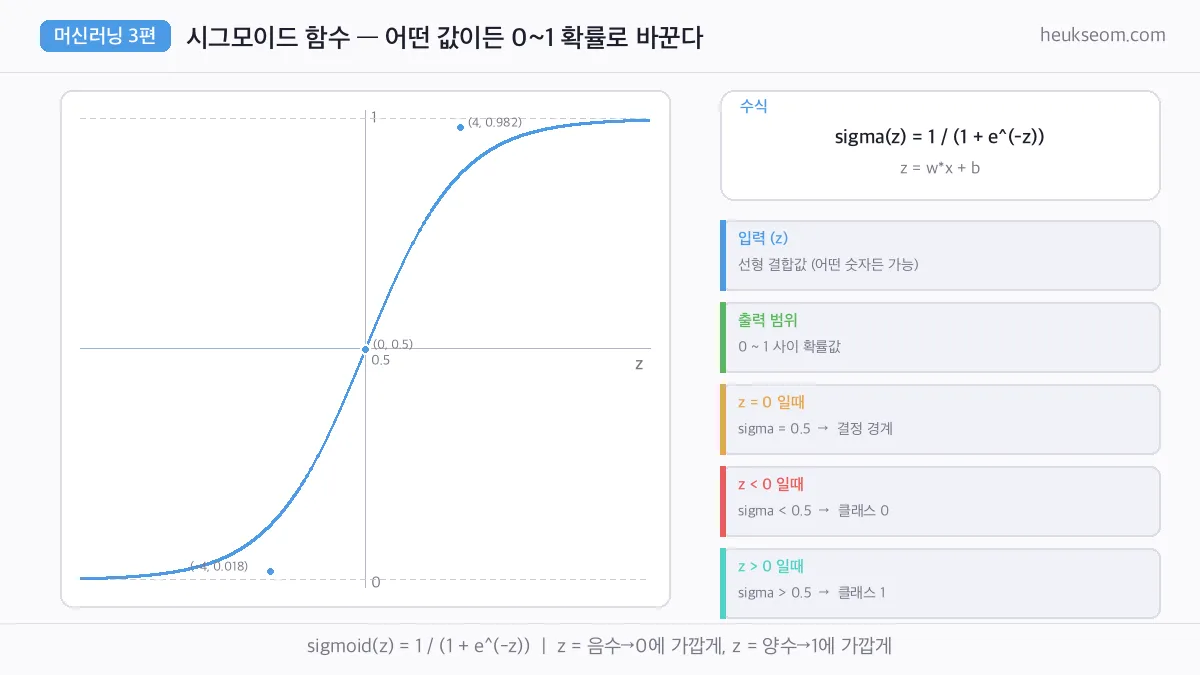
로지스틱 회귀의 핵심은 시그모이드(Sigmoid) 함수입니다.
어떤 숫자를 넣어도 반드시 0과 1 사이의 값으로 압축해줘요.
sigma(z) = 1 / (1 + e^(-z))
z가 매우 크면 → 1에 가까워진다 (거의 확실하게 양성)
z = 0이면 → 정확히 0.5 (50:50)
z가 매우 작으면 → 0에 가까워진다 (거의 확실하게 음성)
왼쪽 그래프의 S자 곡선이 바로 시그모이드예요.
어떤 숫자든 이 곡선을 통과하면 "확률"이 되어 나옵니다.
로지스틱 회귀 파이프라인
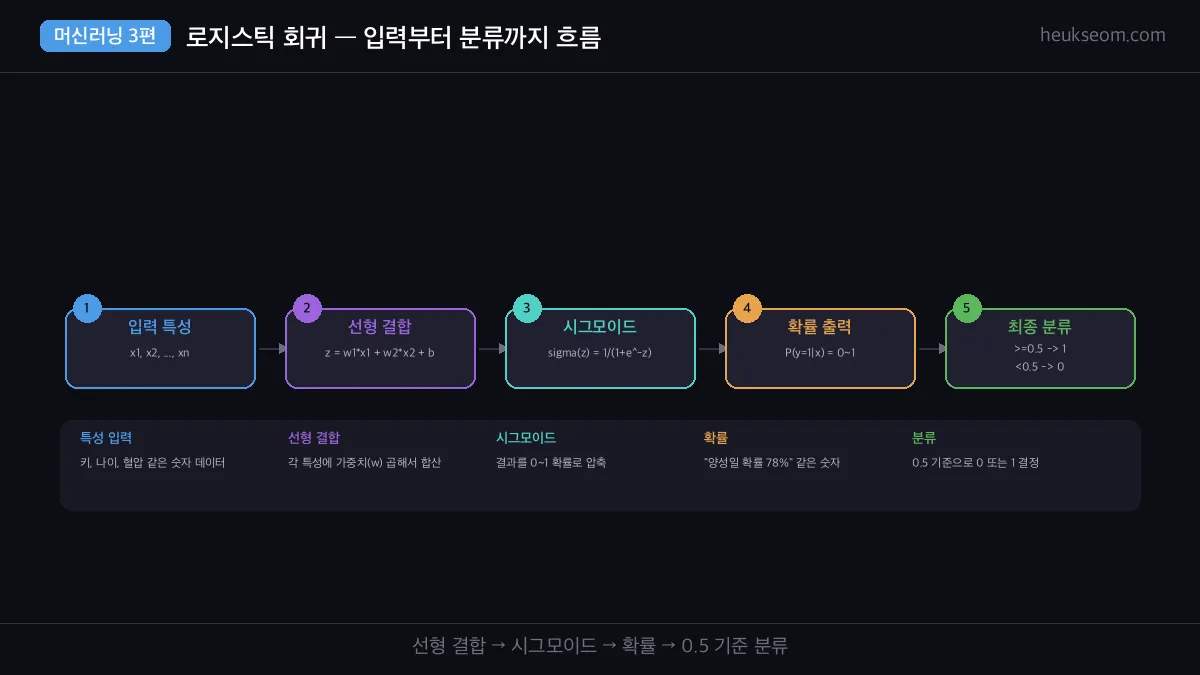
전체 흐름은 간단합니다.
- 입력 특성 — 나이, 키, 혈압 같은 숫자 데이터
- 선형 결합 — z = w1*x1 + w2*x2 + ... + b (각 특성에 가중치 곱해서 합산)
- 시그모이드 — z를 0~1 확률로 변환
- 확률 출력 — "양성일 확률 78%"
- 최종 분류 — 0.5 이상이면 1, 미만이면 0
학습 과정에서는 가중치(w)와 편향(b)을 조정해서
예측 확률과 실제 정답의 차이를 최소화합니다 — 이게 바로 경사 하강법이에요.
결정 경계란 뭔가요?
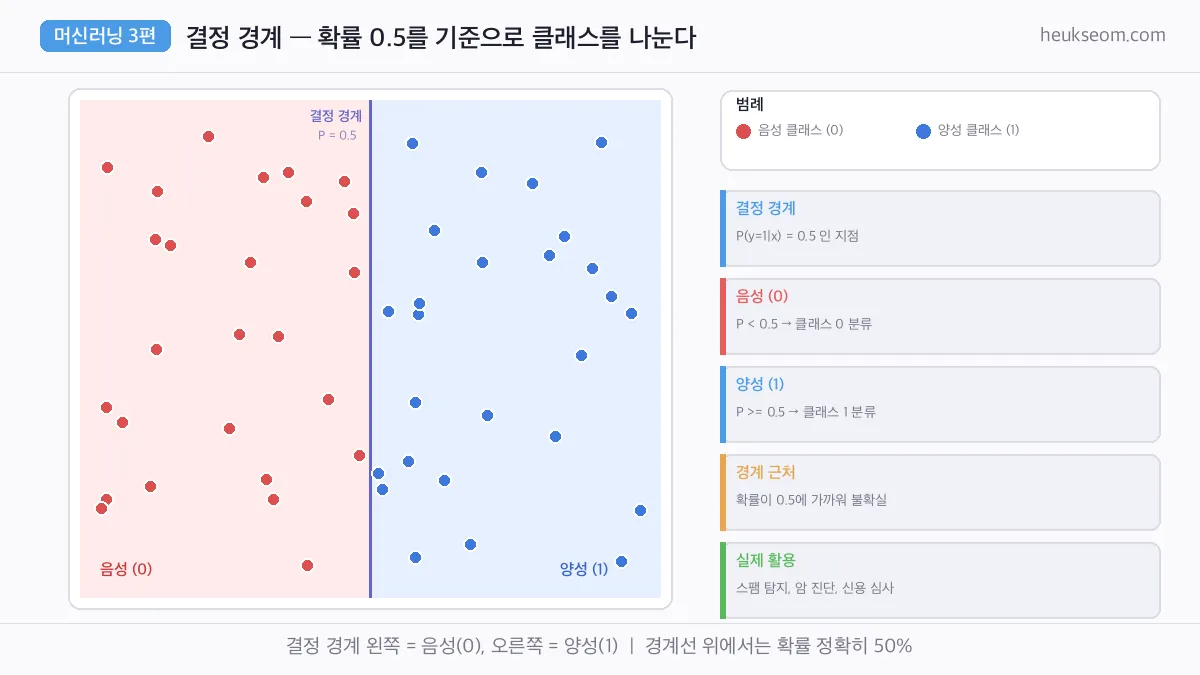
확률 0.5를 기준으로 클래스가 나뉘는 경계를 결정 경계(Decision Boundary)라고 합니다.
경계 왼쪽은 음성(0), 오른쪽은 양성(1).
경계 근처 데이터는 확률이 0.5에 가까워서 불확실한 케이스예요.
코드로 직접 구현해보기
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 유방암 데이터셋 (양성/음성 이진 분류)
data = load_breast_cancer()
X, y = data.data, data.target
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# 스케일링 (로지스틱 회귀는 스케일에 민감)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 모델 학습
model = LogisticRegression(max_iter=1000, random_state=42)
model.fit(X_train, y_train)
print(f"Train Accuracy: {model.score(X_train, y_train):.4f}")
print(f"Test Accuracy: {model.score(X_test, y_test):.4f}")
# 확률 예측
proba = model.predict_proba(X_test[:5])
print("\n첫 5개 샘플 예측 확률:")
for i, p in enumerate(proba):
print(f" 샘플 {i+1}: 음성 {p[0]*100:.1f}% 양성 {p[1]*100:.1f}%")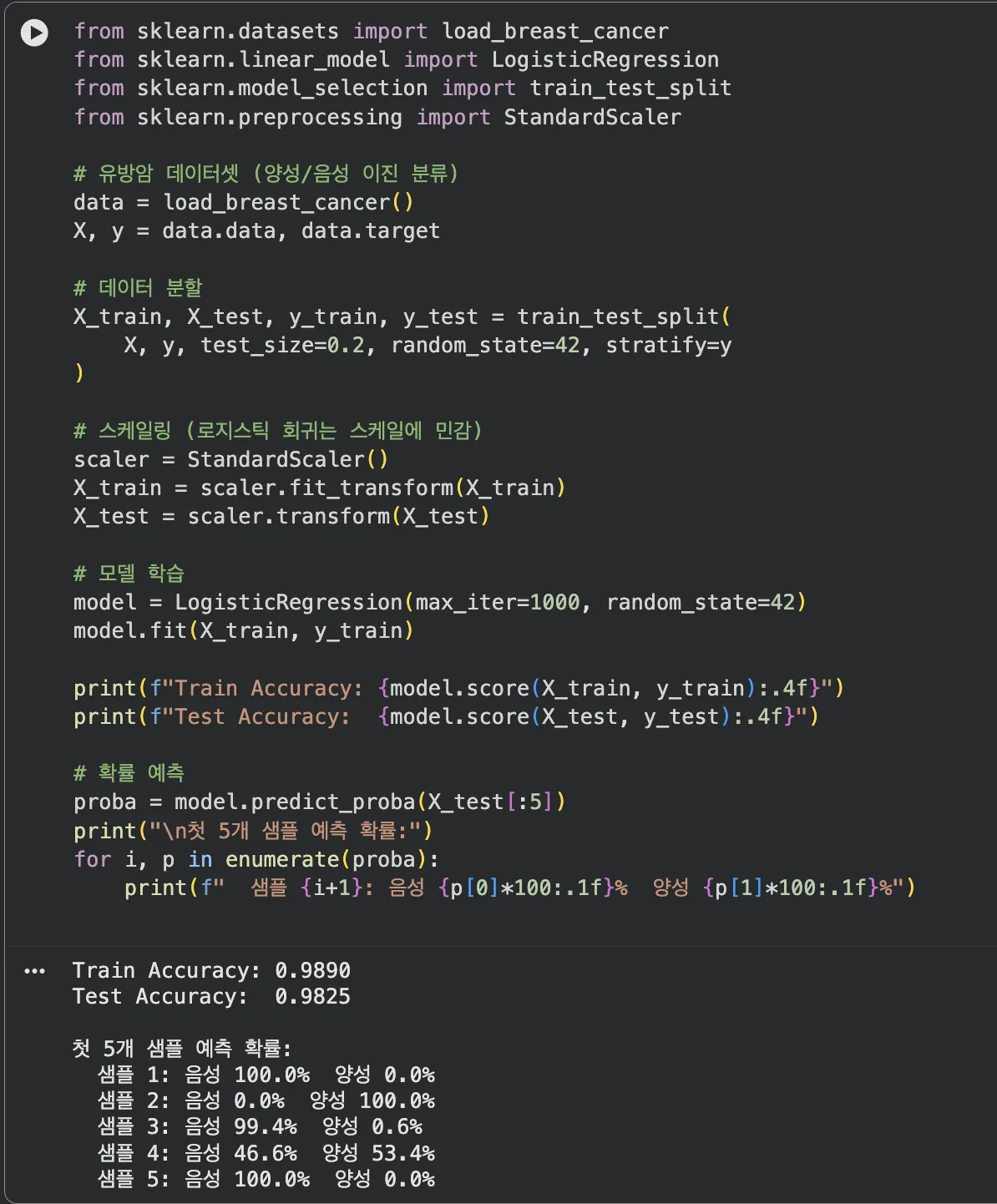
Train 98.9%, Test 98.25% — 갭이 거의 없는 안정적인 결과예요.
첫 5개 샘플은 전부 확률이 한쪽으로 몰려 있어서 (음성 100% 또는 양성 100%에 가깝게)
모델이 꽤 확신을 갖고 분류하고 있다는 걸 알 수 있어요.
로지스틱 회귀는 단순하지만 이런 의료 데이터에서도 95% 이상 정확도를 내는 강력한 알고리즘이에요.
k-NN · 결정트리 · 로지스틱 회귀 비교
k-NN (1편)
거리 기반
이웃 다수결
모델 저장 없음
결정 트리 (2편)
질문 분기
트리 구조
해석이 쉬움
로지스틱 회귀 (3편)
확률 기반
선형 경계
빠르고 안정적
정리
- 시그모이드 함수는 어떤 숫자든 0~1 확률로 압축한다
- 선형 결합 → 시그모이드 → 0.5 기준 분류가 로지스틱 회귀의 전체 흐름
- 단순하지만 실무에서 여전히 강력한 베이스라인 알고리즘
다음 편에서는 데이터가 아무리 많아도 빠르게 찾아내는 나이브 베이즈를 다룹니다.