
[머신러닝 기초 5편] 선형 회귀 — 직선 하나로 미래를 예측한다
선형 회귀는 데이터 사이의 직선 관계를 찾아내는 가장 기본적인 예측 알고리즘입니다. y=wx+b 수식이 어떻게 집값, 매출, 체중을 예측하는지, 경사 하강법으로 최적의 직선을 어떻게 찾는지 직접 구현해봅니다.
시작하며 — 데이터로 미래를 예측할 수 있을까?
집 평수를 보고 가격을 예측한다. 광고비를 보고 매출을 예측한다.
공부 시간을 보고 시험 점수를 예측한다.
이런 것들, 전부 선형 회귀(Linear Regression)로 할 수 있어요. ㅎㅎㅎ
머신러닝 알고리즘 중 가장 단순하지만, 실무에서도 여전히 많이 쓰입니다.
직선 하나로 데이터의 패턴을 포착하는 거예요.
1~4편에서 분류를 다뤘다면 이번 편부터는 숫자 값을 예측하는 회귀입니다.
선형 회귀란 뭔가요?
선형 회귀는 데이터 속 패턴을 직선 하나로 표현해서 미래 값을 예측하는 알고리즘이에요. y = wx + b 수식에서 가중치 w와 편향 b를 학습해서, 집값이나 매출 같은 연속적인 숫자 값을 예측할 수 있습니다.
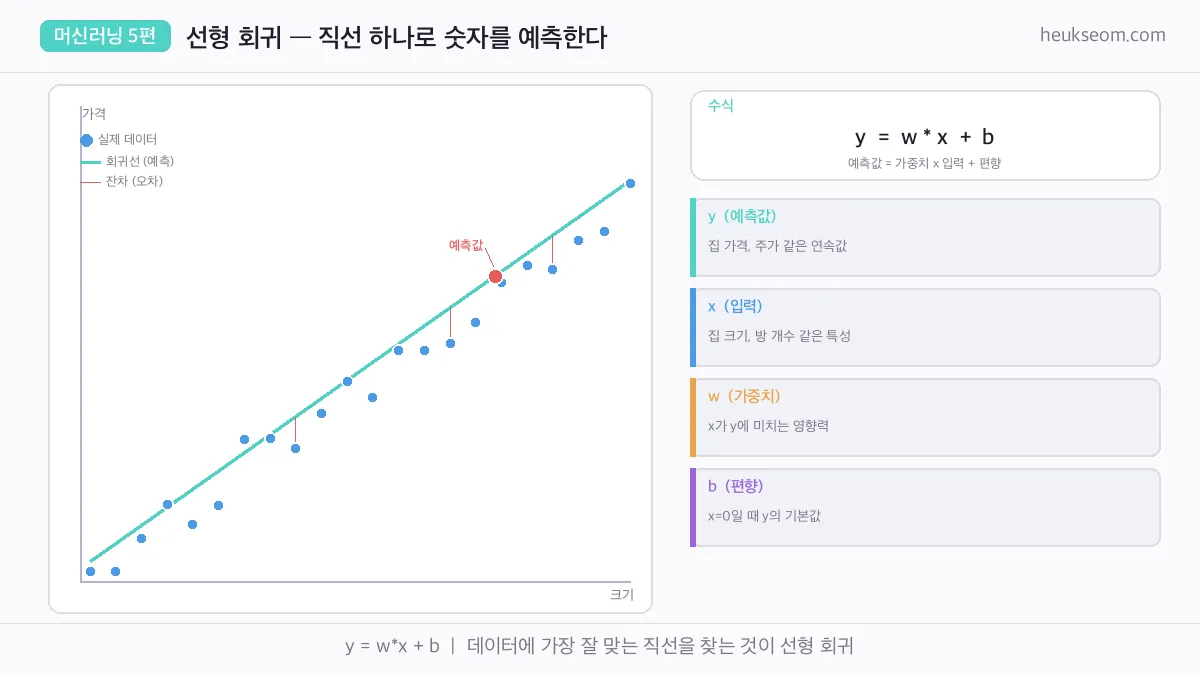
선형 회귀의 핵심은 딱 하나의 수식입니다.
y = wx + b
y — 예측값 (집값, 매출, 점수 등)
x — 입력값 (평수, 광고비, 공부 시간 등)
w — 가중치(기울기): x가 1 증가할 때 y가 얼마나 바뀌는지
b — 편향(절편): x가 0일 때 y의 기본값
그래프로 보면 — 데이터 점들 사이를 가장 잘 관통하는 직선을 찾는 거예요.
그 직선이 바로 우리의 예측 모델입니다.
잔차(residual)는 실제값과 예측값의 차이 — 이게 작을수록 좋은 모델이에요.
최적의 직선은 어떻게 찾나요?

그럼 w, b 값을 어떻게 정할까요?
핵심은 MSE(Mean Squared Error, 평균 제곱 오차)를 최소화하는 겁니다.
MSE = (1/n) × Σ(y_pred - y_true)²
예측값과 실제값의 차이를 제곱해서 평균 낸 것.
이 값이 작을수록 직선이 데이터를 잘 표현하는 것.
MSE를 최소화하는 방법이 경사 하강법(Gradient Descent)입니다.
산에서 가장 빠른 길로 내려오듯 — 기울기 반대 방향으로 w, b를 조금씩 조정해요.
반복하다 보면 MSE가 최소인 지점에 도달합니다.
import numpy as np
# 경사 하강법으로 선형 회귀 직접 구현
def gradient_descent(X, y, lr=0.01, epochs=1000):
w, b = 0.0, 0.0
n = len(X)
for _ in range(epochs):
y_pred = w * X + b
loss = np.mean((y_pred - y) ** 2) # MSE
# 기울기 계산
dw = (2/n) * np.dot(X, (y_pred - y))
db = (2/n) * np.sum(y_pred - y)
# 파라미터 업데이트
w -= lr * dw
b -= lr * db
return w, b
# 예시: 공부 시간 → 시험 점수
X = np.array([1, 2, 3, 4, 5, 6, 7, 8])
y = np.array([55, 60, 65, 70, 75, 80, 85, 90])
w, b = gradient_descent(X, y)
print(f"기울기(w): {w:.2f}, 절편(b): {b:.2f}")
print(f"10시간 공부 예상 점수: {w*10 + b:.1f}점")단순 회귀와 다중 회귀, 뭐가 다른가요?
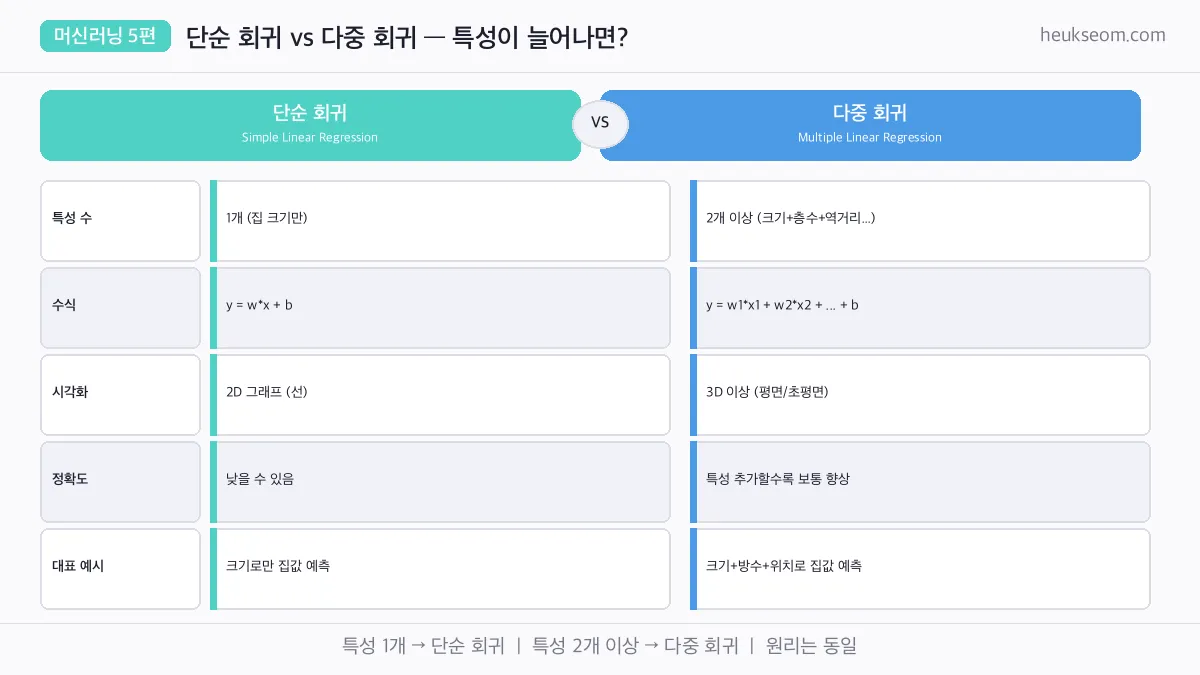
지금까지 x가 하나인 단순 선형 회귀를 봤는데,
현실에선 입력이 여러 개인 다중 선형 회귀를 더 자주 씁니다.
단순: y = w₁x₁ + b (입력 1개)
다중: y = w₁x₁ + w₂x₂ + w₃x₃ + b (입력 여러 개)
집값 예측: 평수(x₁) + 방 개수(x₂) + 역까지 거리(x₃) → 가격(y)
from sklearn.linear_model import LinearRegression
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
housing = fetch_california_housing()
X, y = housing.data, housing.target # 8개 특성 → 집값
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
model = LinearRegression()
model.fit(X_train, y_train)
print(f"Train R²: {model.score(X_train, y_train):.4f}")
print(f"Test R²: {model.score(X_test, y_test):.4f}")
print(f"\n특성별 가중치:")
for name, coef in zip(housing.feature_names, model.coef_):
print(f" {name:20s}: {coef:.4f}")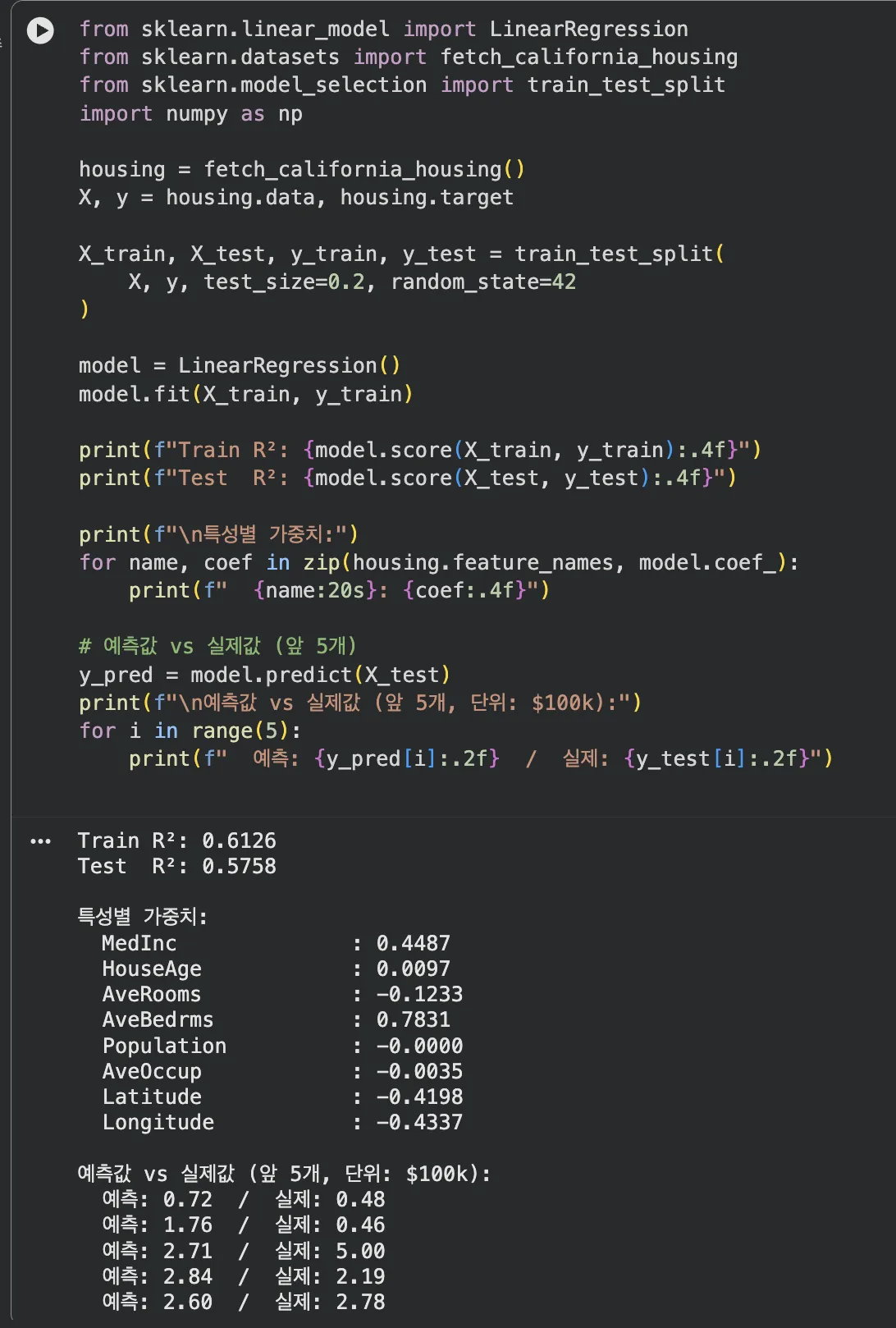
Train R² 0.6126, Test R² 0.5758 — 8개 특성만으로도 집값의 약 58%를 설명합니다.
가중치를 보면 MedInc(중위 소득)이 가장 큰 양의 영향, AveOccup(평균 입주자 수)은 음의 영향이에요.
단순 회귀보다 훨씬 현실적인 예측이 가능해지죠.
정리
- 선형 회귀는 y=wx+b 직선으로 연속적인 값을 예측한다
- MSE를 최소화하는 방향으로 경사 하강법이 w, b를 찾아간다
- 입력이 여러 개인 다중 선형 회귀가 현실에서 더 자주 쓰인다
다음 편에서는 모델이 얼마나 잘 작동하는지 평가하는 모델 평가 지표를 다룹니다.