
[머신러닝 중급 1편] 과적합과 과소적합 — 모델이 시험 문제만 외우면 생기는 일
처음 머신러닝을 배울 때 '과적합'이 뭔 소린지 감이 안 왔습니다. 잘 맞추면 좋은 거 아닌가? 근데, 직접 코드를 돌려보고 나서야 이해했던 경험이 있습니다. degree 하나 바꿨을 뿐인데 그래프가 미친 듯이 요동치는 걸 보고.. 과적합·과소적합의 차이, 편향-분산 트레이드오프, 학습 곡선까지 직접 실행하면서 정리합니다.
시작하며 — 시험 공부의 딜레마
솔직히 말하면, 처음 머신러닝을 배울 때 과적합이라는 단어가 와닿지 않았습니다.
"훈련 데이터에 너무 맞춰졌다"는 게 대체 무슨 뜻이지? 잘 맞추면 좋은 거 아닌가?
그러다 직접 모델을 돌려보고 나서야 이해했습니다.ㅋㅋ..
학교 다닐 때, 기출문제만 달달 외워서 모의고사 100점 맞는 친구 있었잖아요.
근데 실전 수능에서는 망하는 그 케이스.
문제를 외운 거지, 풀이법을 배운 게 아니었기 때문입니다.
머신러닝 모델도 똑같은 실수를 합니다.
훈련 데이터에 너무 딱 맞춰진 모델 — 이걸 과적합(Overfitting)이라고 해요.
이번 편에서는 제가 직접 코드를 돌려보면서 "아, 이게 과적합이구나" 느꼈던 과정을 같이 공유합니다.
과소적합, 적정, 과적합은 어떻게 다른가요?
과소적합은 모델이 너무 단순해서 패턴을 못 잡는 상태이고, 과적합은 훈련 데이터를 외워버려서 새 데이터에서 실패하는 상태예요. 그 사이 적정 수준이 가장 좋은 모델인데, 다항 회귀의 degree 하나만 바꿔도 세 가지가 확연히 달라집니다.
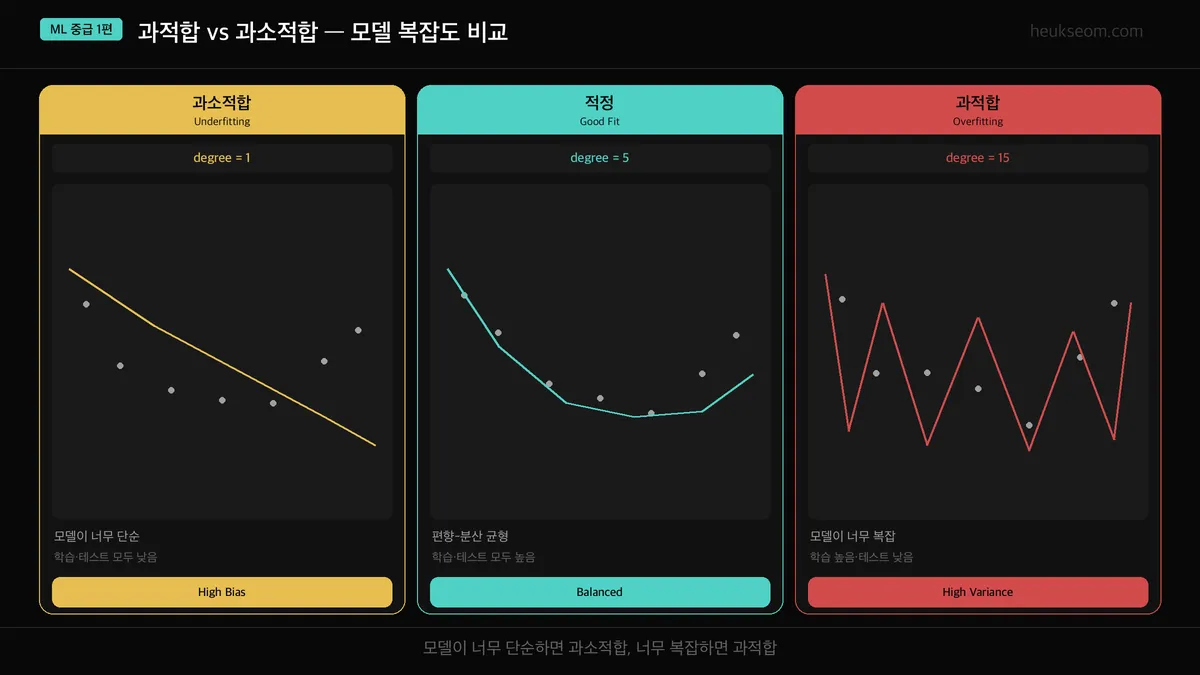
다항 회귀(Polynomial Regression)로 세 가지 모델을 비교해봤습니다.
degree(차수) 값 하나 바꿨을 뿐인데, 모델 성격이 완전히 달라지더라고요.
degree=1 (과소적합) — 직선 하나로 전체를 설명. 너무 단순해서 패턴을 못 잡음
degree=5 (적정) — 데이터의 실제 패턴을 잘 따라감
degree=15 (과적합) — 노이즈까지 전부 외워서 구불구불. 새 데이터에서 망함
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import Pipeline
import numpy as np
# 각 degree별 모델 학습
for degree in [1, 5, 15]:
model = Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('linear', LinearRegression())
])
model.fit(X_train, y_train)
train_score = model.score(X_train, y_train)
test_score = model.score(X_test, y_test)
print(f"degree={degree:2d} | train={train_score:.3f} | test={test_score:.3f}")
직접 주피터에서 돌려봤습니다. degree=1은 뭐.. 직선이라 패턴을 아예 못 잡고,
degree=15는 보자마자 "아 이건 아닌데" 싶었어요. 곡선이 미친 듯이 요동칩니다.
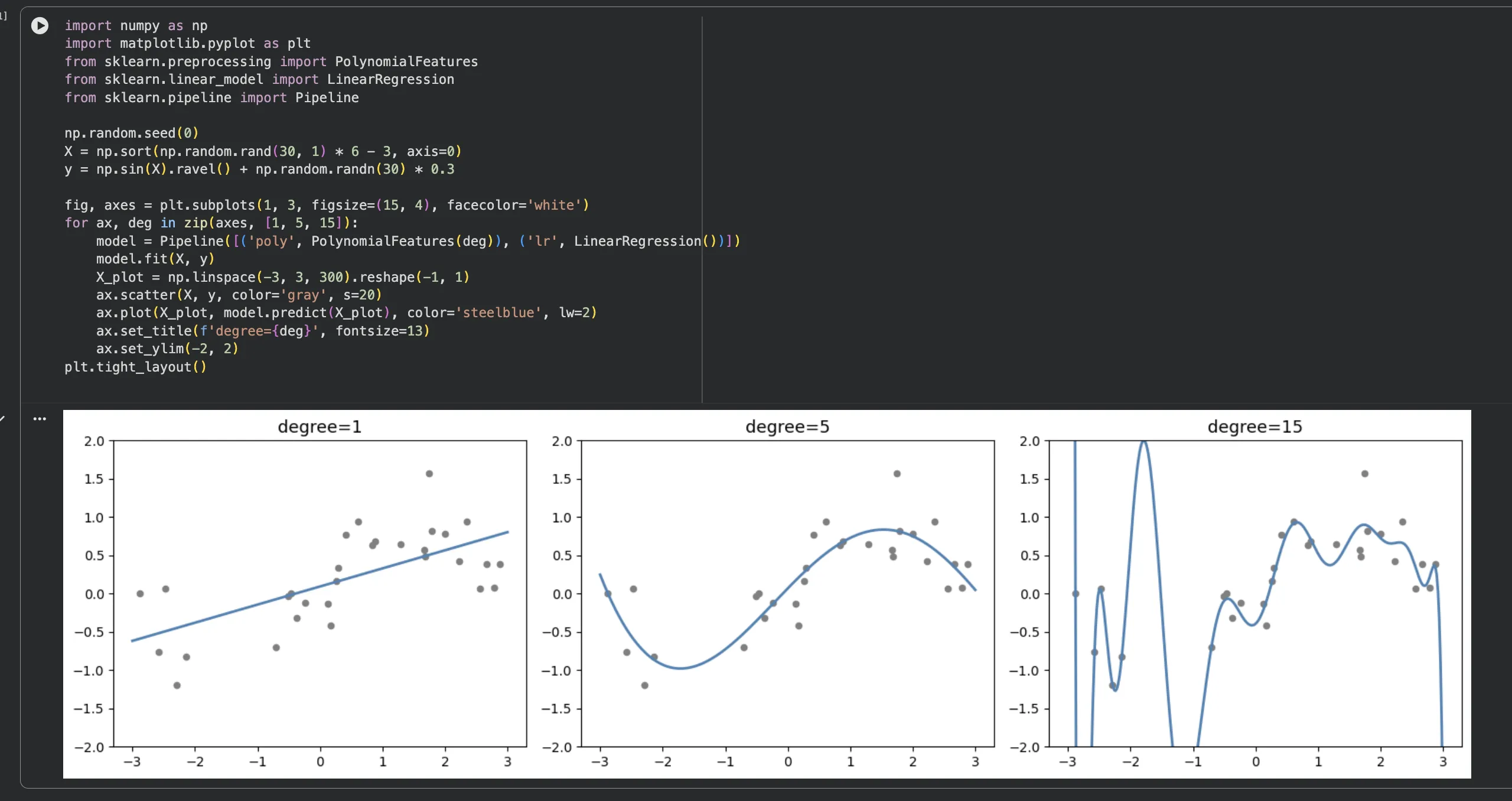
왼쪽(degree=1)은 너무 심플해서 데이터 패턴을 놓치고,
오른쪽(degree=15)은 모든 점을 지나려고 난리를 치고 있죠.
가운데(degree=5)가 그나마 자연스럽게 흐름을 따라가는 적정 수준입니다.
처음 이 그래프를 봤을 때 과적합이 뭔지 바로 체감됐어요.
편향-분산 트레이드오프가 뭔가요?
위에서 과소적합과 과적합을 봤는데, 사실 이 둘은 동전의 양면입니다.
한쪽을 줄이면 다른 쪽이 올라가는 구조예요. 처음엔 "그냥 둘 다 줄이면 되는 거 아닌가?" 싶었는데,
공부할수록 그게 안 된다는 걸 깨달았습니다. 이걸 편향-분산 트레이드오프라고 합니다.
편향(Bias) — 모델이 얼마나 잘못된 가정을 하는가. 높으면 과소적합
분산(Variance) — 데이터가 조금 바뀌어도 예측이 크게 흔들리는가. 높으면 과적합
Total Error = Bias² + Variance + Irreducible Noise
모델을 복잡하게 만들면 편향은 낮아지지만 분산이 높아집니다.
반대로 단순하게 만들면 분산은 낮아지지만 편향이 높아집니다.
최적 지점을 찾는 것이 머신러닝의 핵심 과제입니다.
학습 곡선으로 과적합을 어떻게 진단하나요?
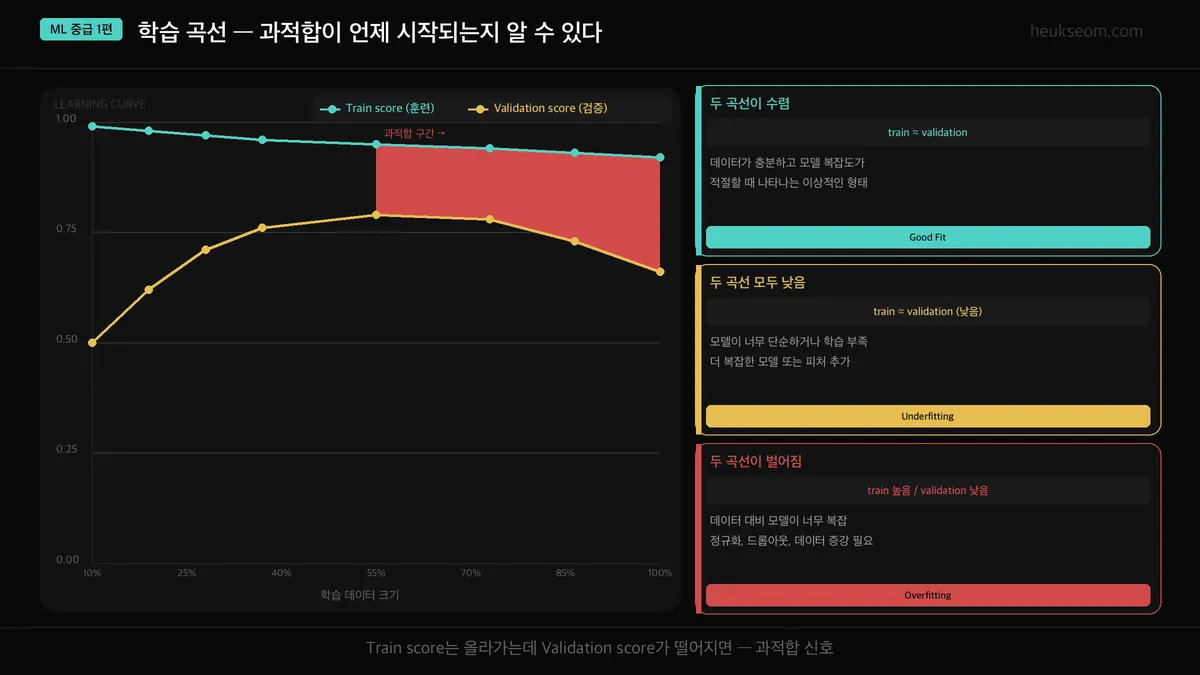
학습 곡선(Learning Curve)은 훈련 데이터 크기에 따른 train/validation 점수 변화를 보여줍니다.
두 곡선의 관계로 현재 상태를 진단할 수 있습니다.
두 곡선이 수렴 → 적정 (Good Fit)
두 곡선 모두 낮음 → 과소적합 (Underfitting)
두 곡선이 벌어짐 → 과적합 (Overfitting)
여기서 헷갈리기 쉬운 포인트가 하나 있습니다.
그래프 왼쪽(데이터가 적을 때)에도 두 곡선이 벌어져 있거든요. 근데 이건 과적합이 아닙니다.
학습 데이터가 적으면 train은 당연히 높고 val은 낮아요. 데이터가 늘면서 좁혀지는 건 정상적인 흐름입니다.
진짜 과적합 신호는 "좁혀지다가 다시 벌어지는" 구간입니다.
데이터를 더 줘도 갭이 안 줄거나, 오히려 다시 커지기 시작하면 — 그게 과적합이 시작된 지점이에요.
위 그래프에서 빨간 영역이 바로 그 구간입니다.
from sklearn.model_selection import learning_curve
import matplotlib.pyplot as plt
import numpy as np
train_sizes, train_scores, val_scores = learning_curve(
model, X, y,
train_sizes=np.linspace(0.1, 1.0, 7),
cv=5,
scoring='accuracy'
)
train_mean = train_scores.mean(axis=1)
val_mean = val_scores.mean(axis=1)
plt.plot(train_sizes, train_mean, label='Train score', color='#4FD1C5')
plt.plot(train_sizes, val_mean, label='Validation score', color='#E6BE50')
plt.xlabel('Training set size')
plt.ylabel('Score')
plt.legend()
plt.show()직접 돌려보니까 이런 결과가 나왔습니다. 처음에는 "이게 뭐지?" 싶었는데, 잘 보면 재밌어요.
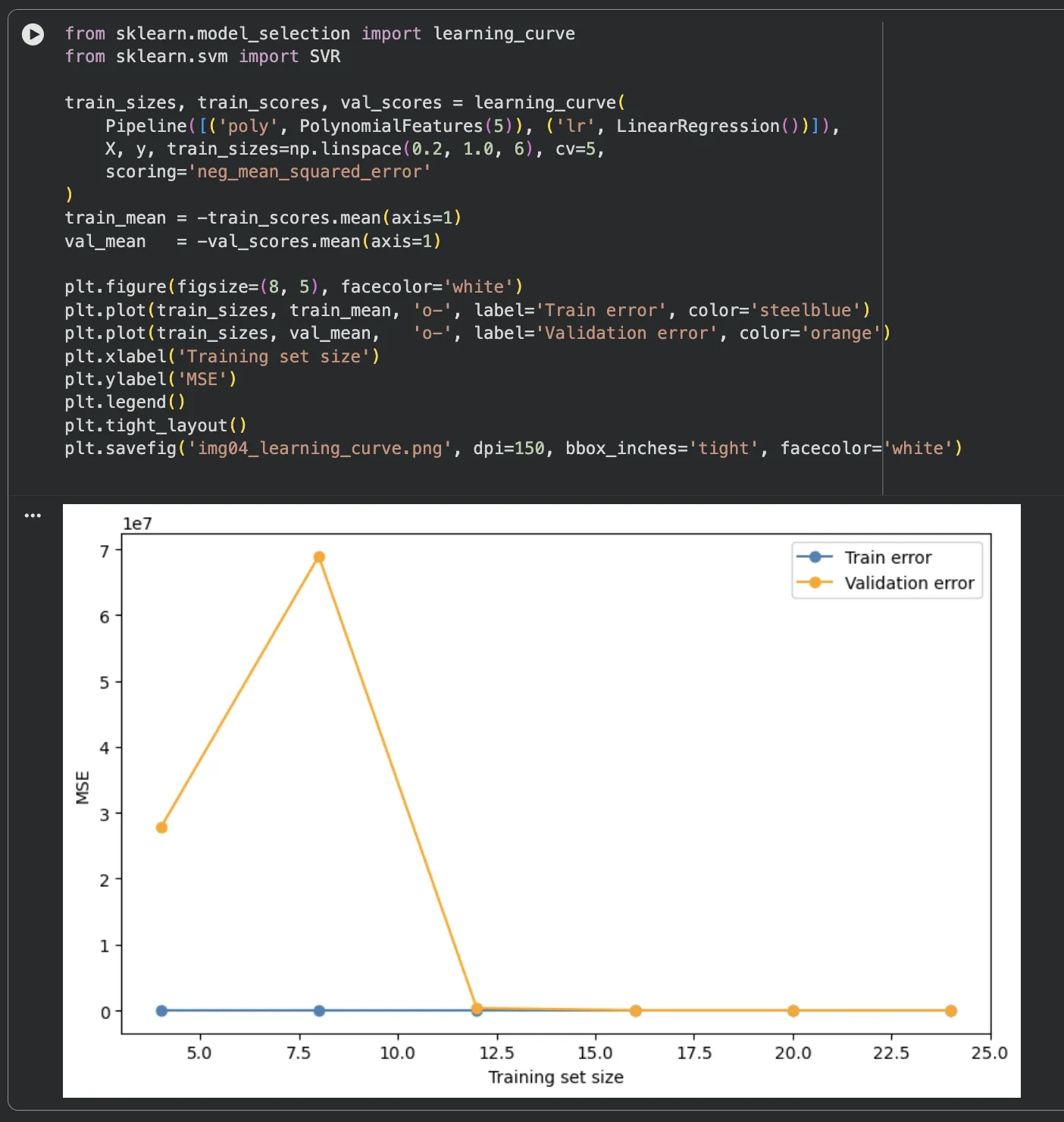
데이터가 적을 때는 Train error와 Validation error 차이가 확 벌어집니다.
데이터가 늘어나면서 두 곡선이 점점 가까워지는 게 보이죠?
이게 안 좁혀지고 계속 벌어져 있으면 — 과적합 신호입니다.
저도 처음엔 그래프만 봐서는 감이 안 왔는데, 직접 degree를 바꿔가면서 학습 곡선을 여러 번 그려보니까 확실히 느껴지더라고요.
과적합은 어떻게 해결하나요?
과적합을 잡는 방법은 여러 가지가 있는데, 실제로 써보니 상황에 따라 효과가 다릅니다.
제가 정리한 4가지 방법입니다.
1. 더 많은 데이터
가장 확실한 해결책입니다. 데이터가 다양할수록 모델이 패턴을 제대로 배울 확률이 올라가요.
현실에서는 데이터를 무한정 구할 수 없으니 데이터 증강(Augmentation)으로 보완하는 경우가 많습니다.
2. 정규화 (Regularization)
가중치에 패널티를 부여해서 모델이 너무 복잡해지지 않도록 막는 방법입니다.
L1(Lasso)은 불필요한 특성을 아예 제거하고, L2(Ridge)는 가중치를 전체적으로 줄여요.
이 부분은 내용이 많아서 다음 편(3편)에서 따로 정리할 예정입니다.
3. 모델 단순화
결정 트리 깊이를 제한하거나, 특성 수를 줄이거나, 뉴럴넷 레이어를 줄이는 방법입니다.
max_depth, max_features 같은 파라미터를 조절하면 됩니다.
위에서 degree=15를 5로 낮춘 것도 결국 모델 단순화의 한 예시입니다.
4. 교차 검증 (Cross-Validation)
데이터를 여러 묶음으로 나눠서 돌아가며 학습/검증을 반복하는 방법입니다.
한 번의 train/test 분리보다 훨씬 안정적인 성능 측정이 가능합니다.
from sklearn.model_selection import cross_val_score
scores = cross_val_score(model, X, y, cv=5, scoring='accuracy')
print(f"CV scores: {scores}")
print(f"Mean: {scores.mean():.3f} ± {scores.std():.3f}")정리
처음에 과적합이라는 개념이 추상적으로 느껴졌는데,
직접 degree를 바꿔가면서 그래프를 그려보니까 바로 이해가 됐습니다.
역시 머신러닝은 직접 돌려봐야 감이 와요.
1. 과적합 — 훈련 데이터에 너무 맞춰져서 새 데이터에서 실패한다
2. 학습 곡선 — train/validation 점수 차이로 지금 모델 상태를 진단할 수 있다
3. 해결책 — 데이터 늘리기 / 정규화 / 모델 단순화 / 교차검증
다음 편(2편)에서는 서포트 벡터 머신(SVM)을 다룹니다.
두 그룹 사이의 가장 넓은 길을 찾는 알고리즘인데, 마진 최대화와 커널 트릭 개념이 생각보다 직관적이에요.
다음 편에서 같이 정리해보겠습니다.