
[머신러닝 중급 6편] 주성분 분석(PCA) — 100개 특성을 2개로 줄여도 되는 이유
처음 PCA를 접했을 때 '특성을 줄이면 정보가 날아가는 거 아닌가?' 싶었습니다. 근데 iris 데이터 4개 특성을 2개로 줄여서 산점도를 그려보니까, 클래스 구분이 여전히 선명하더라고요. 분산 설명 비율, Scree Plot, 차원 축소 전후 비교까지 직접 코드로 확인합니다.
시작하며 — 특성이 100개일 때
데이터에 특성이 5~10개면 괜찮은데,
50개, 100개가 넘어가면 문제가 생기기 시작합니다.
차원의 저주 (Curse of Dimensionality)
- 특성이 많을수록 데이터 포인트 사이의 거리가 비슷해짐
- 모델 학습이 느려지고, 과적합 위험 증가
- 시각화도 불가능 (3차원까지가 한계)
처음에 "특성을 줄이면 정보가 날아가는 거 아닌가?" 싶었는데,
PCA를 돌려보니까 핵심 정보는 거의 그대로 남으면서 차원만 줄어드는 걸 확인할 수 있었습니다.
PCA는 어떤 원리로 차원을 줄이나요?
PCA는 데이터가 가장 많이 퍼져 있는 방향(분산이 최대인 방향)을 찾아서 그 축으로 데이터를 요약하는 기법이에요. 이 방향을 주성분이라 하고, 상위 몇 개 주성분만으로도 원본 정보의 대부분을 보존할 수 있어서 차원 축소에 효과적입니다.
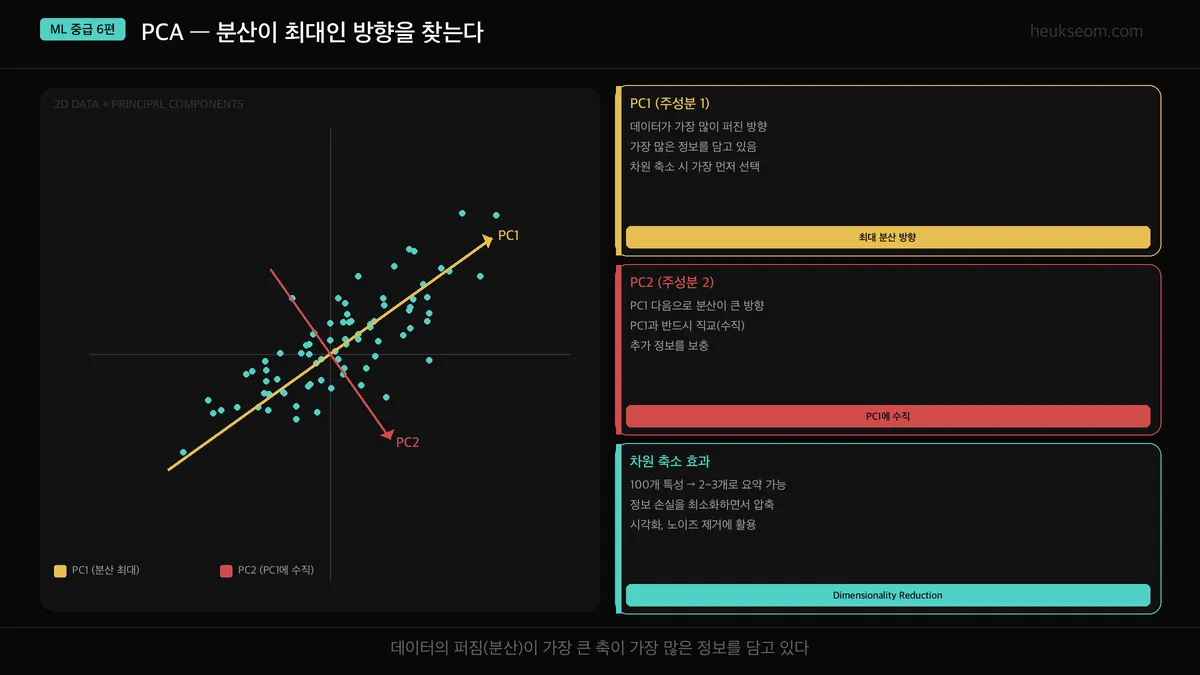
PCA는 Principal Component Analysis의 약자입니다. 직역하면 "주요 성분 분석"인데, 우리말로 주성분 분석이라고 해요.
핵심 아이디어는 심플합니다.
데이터가 가장 많이 퍼져 있는 방향(=분산이 최대인 방향)이
가장 많은 정보를 담고 있다.
이 방향을 주성분(Principal Component)이라고 하고,
PC1이 분산 최대, PC2는 PC1에 수직인 방향에서 분산 최대, ...
사람을 설명할 때 키, 몸무게, BMI, 체지방률, 허리둘레... 다 쓰는 대신
"체형 점수" 하나로 요약할 수 있는 거랑 비슷합니다.
그 "체형 점수"가 바로 첫 번째 주성분(PC1)이에요.
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris
import numpy as np
# iris 데이터 (4개 특성)
iris = load_iris()
X = iris.data # (150, 4)
y = iris.target
# 스케일링 (PCA 전에 반드시!)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# PCA로 4차원 → 2차원
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
print(f"원래 차원: {X.shape}")
print(f"PCA 후: {X_pca.shape}")
print(f"분산 설명 비율: {pca.explained_variance_ratio_}")
print(f"총 설명 비율: {pca.explained_variance_ratio_.sum():.3f}")
이걸 돌려보면 PC1이 약 72%, PC2가 약 23%의 분산을 설명합니다.
즉 2개 주성분만으로 전체 정보의 95%를 담을 수 있다는 뜻이에요.
4개 특성을 2개로 줄였는데 정보 손실이 5%뿐인 거죠.
주성분을 몇 개 써야 하나요?
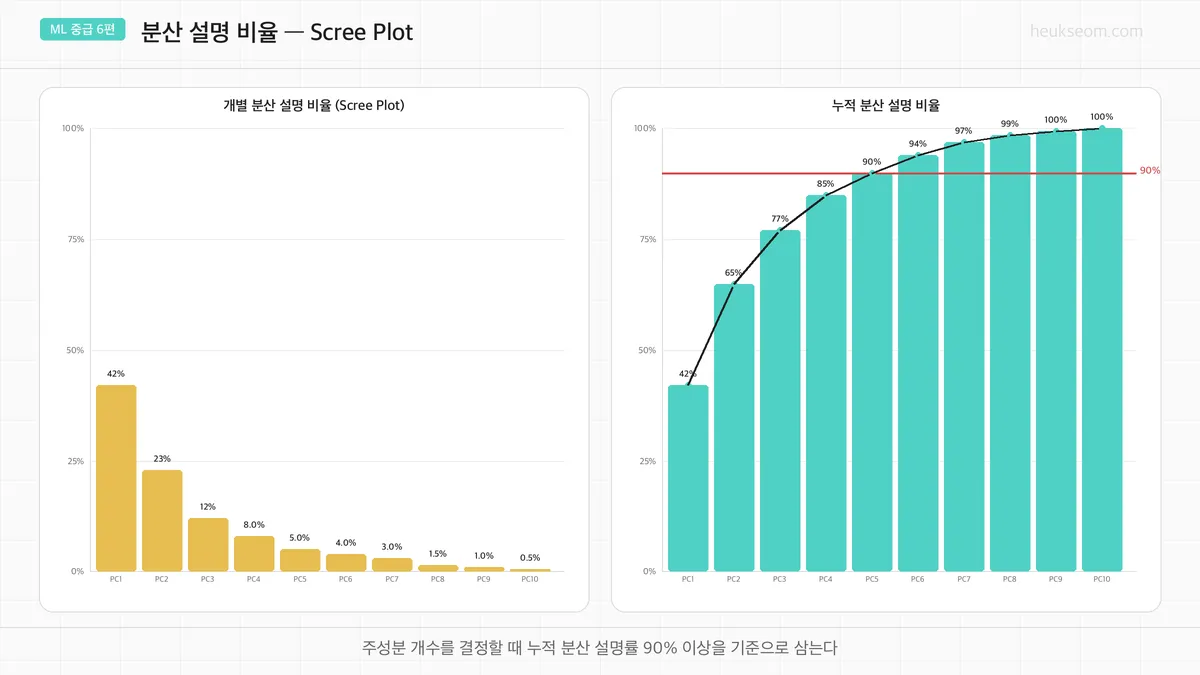
"몇 개 주성분을 쓸 것인가"를 결정할 때 Scree Plot을 씁니다.
개별 분산 설명 비율 — PC1이 가장 크고 뒤로 갈수록 급격히 감소. "팔꿈치(elbow)" 지점을 찾음
누적 분산 설명 비율 — 보통 90% 이상을 기준으로 주성분 개수를 결정
# 모든 주성분의 분산 설명 비율 확인
pca_full = PCA()
pca_full.fit(X_scaled)
print("각 주성분의 분산 설명 비율:")
for i, ratio in enumerate(pca_full.explained_variance_ratio_):
cumsum = pca_full.explained_variance_ratio_[:i+1].sum()
print(f" PC{i+1}: {ratio:.4f} (누적: {cumsum:.4f})")
# 90% 이상이 되는 주성분 수
cumsum = np.cumsum(pca_full.explained_variance_ratio_)
n_90 = np.argmax(cumsum >= 0.90) + 1
print(f"\n90% 설명에 필요한 주성분 수: {n_90}개")PCA 전후로 데이터가 어떻게 달라지나요?
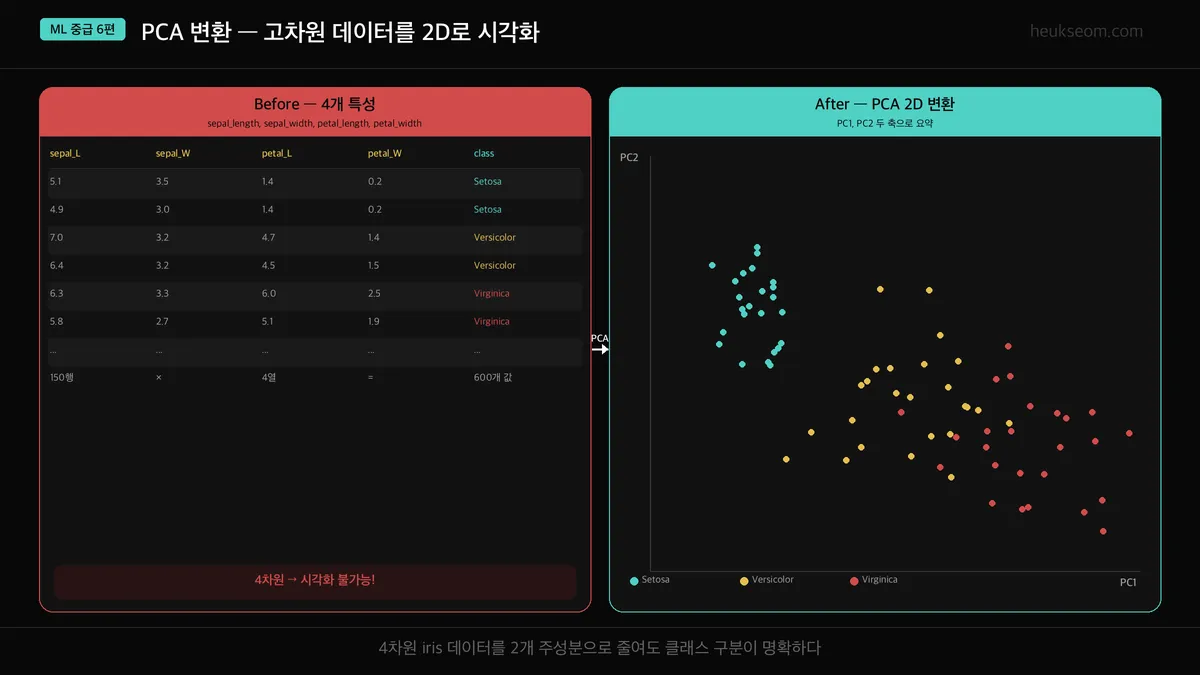
위 이미지가 PCA의 핵심을 보여줍니다.
왼쪽: 4개 특성이라 시각화가 불가능.
오른쪽: PCA로 2개로 줄이니까 산점도로 그릴 수 있고, 클래스 구분도 선명하게 보입니다.
import matplotlib.pyplot as plt
# PCA 2D 시각화
plt.figure(figsize=(8, 6))
target_names = iris.target_names
colors = ['#4FD1C5', '#E6BE50', '#D24B4B']
for i, (name, color) in enumerate(zip(target_names, colors)):
mask = y == i
plt.scatter(X_pca[mask, 0], X_pca[mask, 1],
c=color, label=name, s=50, alpha=0.7)
plt.xlabel(f'PC1 ({pca.explained_variance_ratio_[0]:.1%})')
plt.ylabel(f'PC2 ({pca.explained_variance_ratio_[1]:.1%})')
plt.title('Iris Dataset — PCA 2D Projection')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()축 라벨에 분산 설명 비율을 적어두면 "이 축이 전체 정보의 몇 %를 담고 있는지" 바로 보여서 좋습니다.
PCA는 시각화 말고 어디에 쓰이나요?
PCA가 시각화에만 쓰이는 줄 알았는데, 실무에서는 다른 용도도 많습니다.
1. 전처리 — 차원 축소
특성이 너무 많을 때 PCA로 줄여서 모델 학습 속도 향상 + 과적합 방지
2. 노이즈 제거
하위 주성분은 노이즈를 담고 있는 경우가 많아서, 상위 주성분만 쓰면 노이즈 제거 효과
3. 다중공선성 해결
상관관계 높은 특성들을 독립적인 주성분으로 변환
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
# PCA를 전처리로 활용
pipe = Pipeline([
('scaler', StandardScaler()),
('pca', PCA(n_components=2)),
('clf', LogisticRegression(random_state=42))
])
# 원본 4개 특성 vs PCA 2개 특성
scores_original = cross_val_score(
LogisticRegression(random_state=42),
StandardScaler().fit_transform(X), y, cv=5
)
scores_pca = cross_val_score(pipe, X, y, cv=5)
print(f"원본 (4특성): {scores_original.mean():.4f}")
print(f"PCA (2특성): {scores_pca.mean():.4f}")
iris 데이터에서는 4개를 2개로 줄여도 성능 차이가 거의 없습니다.
특성이 수십~수백 개인 실무 데이터에서는 이 효과가 훨씬 크게 나타나요.
직접 돌려본 결과 — iris PCA 2D 시각화
iris 데이터 4개 특성을 PCA로 2개로 줄여서 산점도를 그려봤습니다.
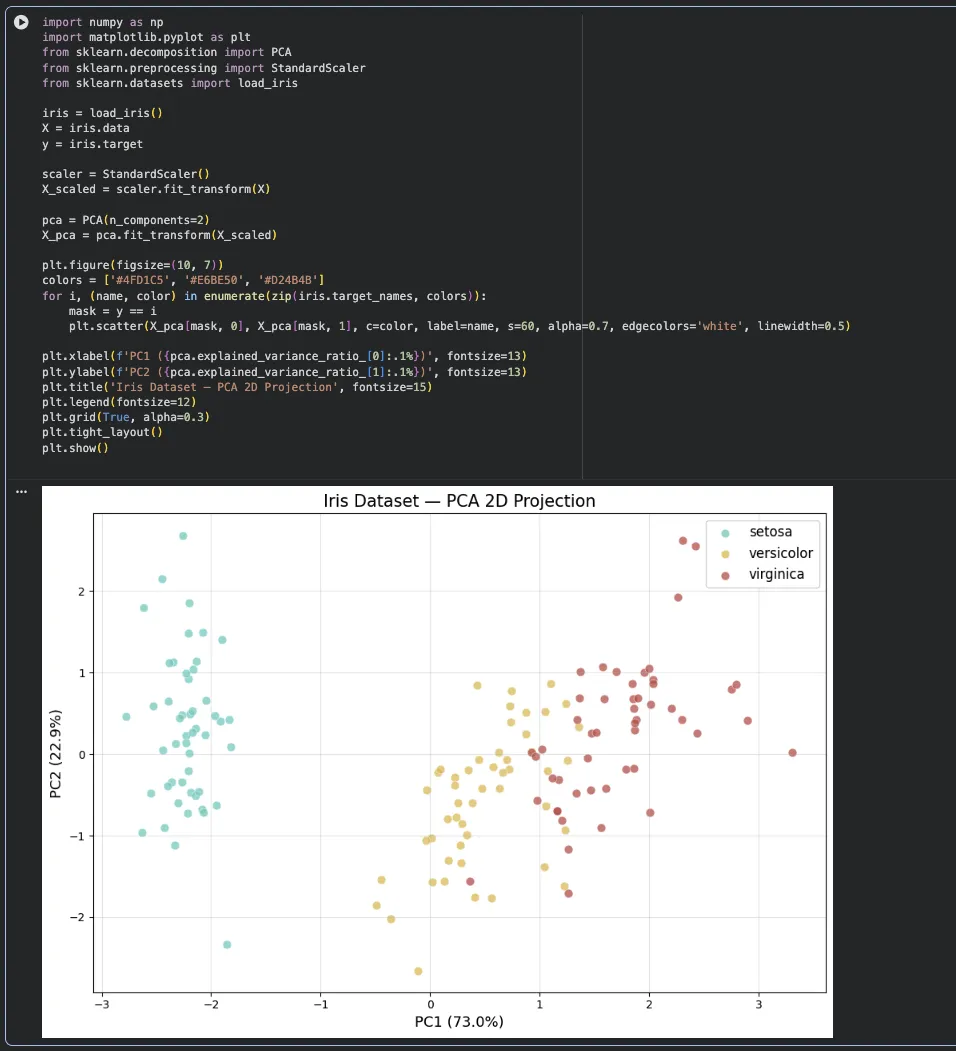
4차원을 2차원으로 줄였는데도 3개 클래스가 선명하게 구분됨
PC1이 72.8%, PC2가 23.0% — 합쳐서 95.8%의 정보를 담고 있음
분산 설명 비율은 어떻게 확인하나요?
각 주성분이 전체 분산의 몇 %를 설명하는지, 그리고 누적은 어떻게 되는지 확인.
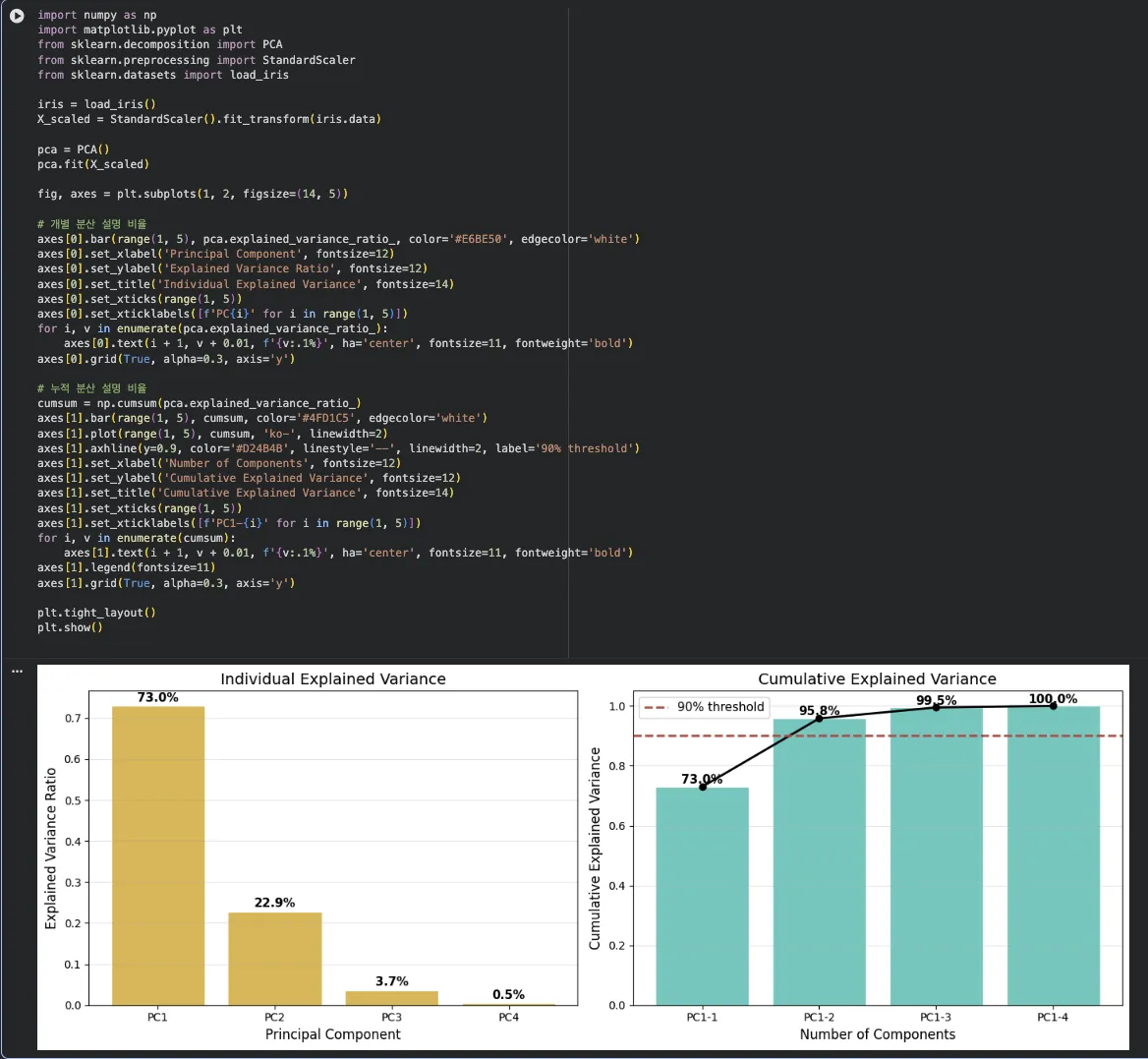
PC1만으로 72.8%, PC1+PC2면 95.8% 설명 → 2개면 충분
빨간 점선(90%)을 넘는 지점이 필요한 최소 주성분 수
주의사항
스케일링 필수 — PCA는 분산 기반이라, 단위가 다르면 결과가 왜곡됨. StandardScaler 먼저!
해석이 어려움 — PC1이 "무엇을 의미하는지" 직관적으로 설명하기 어려움. 원래 특성의 선형 조합이라서
비선형 관계 — PCA는 선형 변환이라 비선형 구조는 잘 못 잡음. 그럴 땐 t-SNE나 UMAP 사용
(t-SNE는 "가까운 점은 가깝게, 먼 점은 멀게" 보존하는 시각화 기법이고, UMAP은 t-SNE의 개선판으로 속도가 빠르고 전역 구조도 잘 보존합니다)
정리
PCA는 처음에 어렵게 느껴지지만, 핵심은 단순합니다.
"데이터가 가장 많이 퍼진 방향을 찾아서 그 축으로 데이터를 요약한다."
1. 주성분 — 분산이 최대인 방향. PC1이 가장 많은 정보를 담음
2. Scree Plot — 누적 분산 설명 비율 90%를 기준으로 주성분 개수 결정
3. 활용 — 시각화, 차원 축소 전처리, 노이즈 제거. 스케일링 필수
이것으로 머신러닝 중급 시리즈 6편을 마칩니다.
기초 시리즈에서 다룬 k-NN, 결정 트리, 로지스틱 회귀 등에 이어,
과적합·SVM·정규화·부스팅·이상치탐지·PCA까지 — 실무에서 자주 맞닥뜨리는 핵심 개념들을 정리했습니다.
여기까지 따라왔다면 대부분의 머신러닝 프로젝트를 이해하고 시작할 수 있는 기반이 갖춰졌을 거라고 생각합니다.