
[머신러닝 실전 1편] 통신사 고객 7천 명, 누가 떠날까 — EDA로 단서 찾기
처음 데이터를 받았을 때 바로 모델부터 돌렸습니다. 정확도 79%에 좋아했는데.. 자세히 보니 이탈 고객을 거의 못 잡고 있었습니다. 원인을 찾다 보니 데이터 자체에 문제가 있었습니다. 그때 깨달았습니다 — 모델 전에 데이터를 먼저 봐야 한다는 것을. 제가 했던 실수를 여러분은 안 하시도록, Telco Churn 데이터 7,043명을 직접 뜯어보면서 EDA가 왜 필수인지 확인합니다.
시작하며 — 제가 했던 실수부터 말씀드릴게요
솔직히 말하면, 저는 머신러닝을 배우면서 꽤 큰 실수를 했습니다.ㅋㅋ
k-NN, 결정 트리, SVM, XGBoost... 기초/중급 시리즈를 거치면서 도구를 안다고 생각했습니다.
그래서 실제 데이터를 받자마자 바로 모델부터 돌려버렸습니다.
결과는요? 정확도 79%. "오, 나쁘지 않은데?" 싶었는데..
자세히 뜯어보니 이탈 고객을 거의 못 잡고 있었습니다.
원인을 파헤쳐보니 — 데이터 자체에 결측치가 있었고, 숫자여야 할 컬럼이 문자열이었습니다.
그때서야 깨달았습니다. 모델을 돌리기 전에 데이터를 먼저 들여다봐야 한다는 것을요.
이걸 EDA(Exploratory Data Analysis, 탐색적 데이터 분석)라고 합니다.
이번 실전 시리즈에서는 제가 했던 실수를 여러분은 안 하시도록, 하나의 데이터셋을 가지고 처음부터 끝까지 완성하는 과정을 함께 진행합니다.
통신사 고객 이탈(Churn) 데이터는 어떻게 생겼나요?
Kaggle의 Telco Customer Churn 데이터셋으로, 통신사 고객 7,043명의 정보가 담겨 있습니다. 성별, 가입 기간, 월 요금, 서비스 종류 등 21개 컬럼과 함께 이탈 여부(Churn) 라벨이 포함되어 있어 분류 모델 실습에 적합합니다.
이번에 사용할 데이터는 Kaggle의 Telco Customer Churn 데이터셋입니다.
통신사 고객 7,043명의 정보가 담겨 있고, 핵심 질문은 하나입니다.
"이 고객이 이탈할 것인가, 유지할 것인가?"
7,043명 × 21개 변수 — 성별, 계약 유형, 월 요금, 재직 기간 등
타겟: Churn (Yes / No)
이 데이터셋을 고른 이유가 있습니다.
범주형(성별, 계약유형)과 수치형(요금, 재직기간)이 섞여 있고,
결측치도 있고, 불균형도 있어서 — 실전에서 맞닥뜨리는 문제를 전부 연습할 수 있습니다.
처음 이 데이터를 열어봤을 때 "이거 하나면 시리즈 전체를 커버할 수 있겠다" 싶었습니다.
데이터를 받으면 EDA는 어떻게 시작하나요?
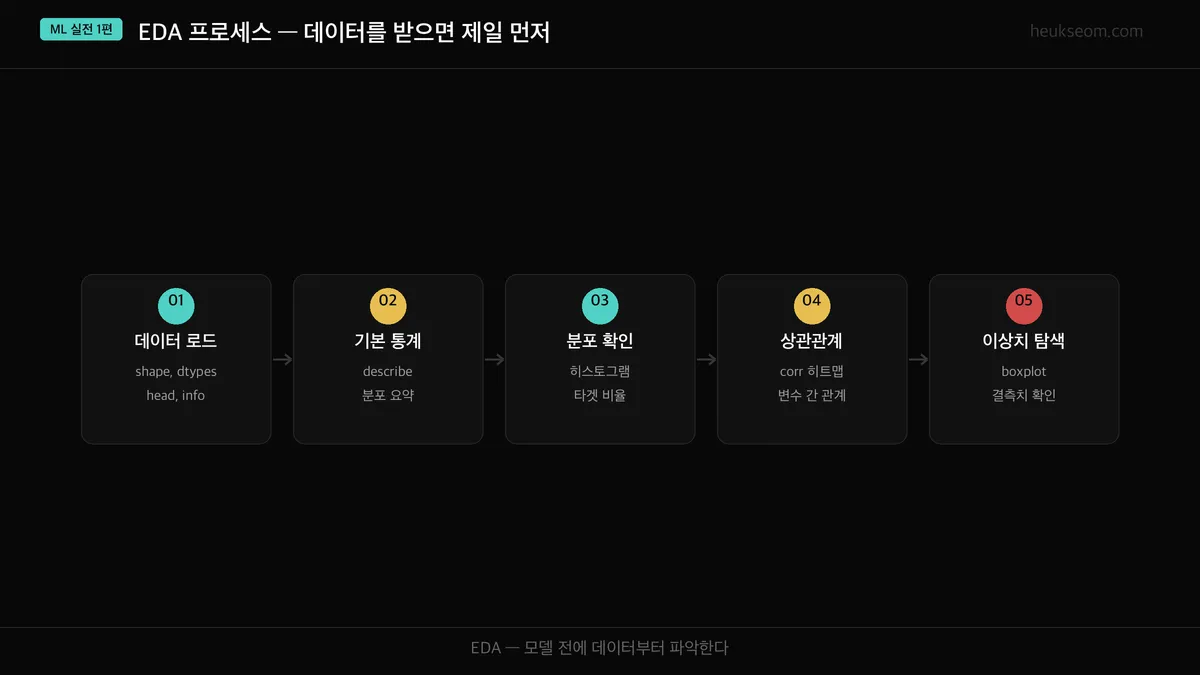
EDA는 거창한 게 아닙니다. 데이터를 이해하기 위한 탐색 과정입니다.
저도 처음에는 "그냥 head() 한번 찍어보면 되는 거 아니야?" 했는데,
위 5단계를 순서대로 밟아보니까 head()만으로는 절대 못 잡는 문제들이 보였습니다.
import pandas as pd
import numpy as np
# 데이터 로드
df = pd.read_csv('telco_churn.csv')
# 1단계: 기본 정보 확인
print(f"데이터 크기: {df.shape}") # (7043, 21)
print(f"컬럼 타입:\n{df.dtypes}")
print(f"\n결측치:\n{df.isnull().sum()[df.isnull().sum() > 0]}")
print(f"\n상위 5행:\n{df.head()}")여기서 바로 문제가 하나 보였습니다.
TotalCharges의 타입이 object(문자열)입니다. 숫자여야 하는데..
알고 보니 빈 문자열(" ")이 섞여 있어서 자동으로 숫자 변환이 안 된 것이었습니다.
처음에 이걸 모르고 그냥 넘어갔다가 나중에 모델이 에러를 뱉었습니다. 이런 걸 EDA 단계에서 잡아야 합니다.
# TotalCharges 타입 문제 확인
print(df['TotalCharges'].dtype) # object ← 숫자여야 하는데!
# 빈 문자열 찾기
empty = df[df['TotalCharges'] == ' ']
print(f"빈 값 개수: {len(empty)}개") # 11개
# 숫자로 변환 (빈 값 → NaN)
df['TotalCharges'] = pd.to_numeric(df['TotalCharges'], errors='coerce')
print(f"결측치: {df['TotalCharges'].isnull().sum()}개") # 11개타겟 분포에서 이탈 고객은 얼마나 되나요?
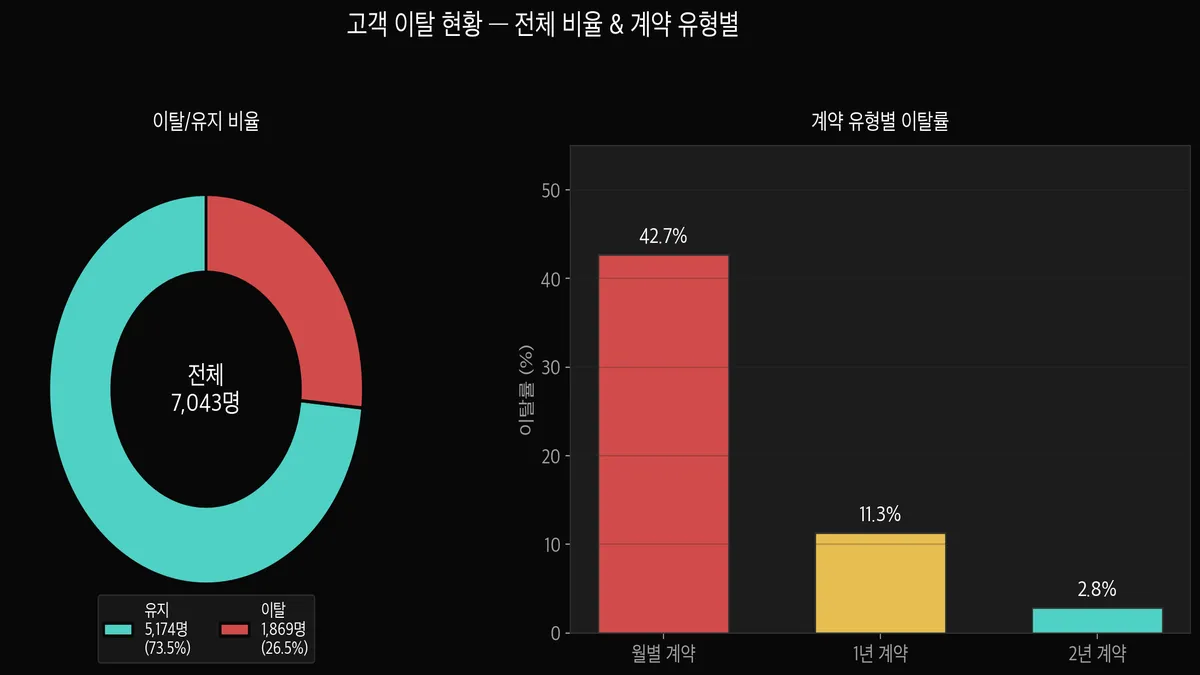
전체 7,043명 중 이탈은 1,869명으로 26.5%였습니다.
처음에 이 숫자를 보고 "4명 중 1명이 떠난다고?" 싶었는데 — 이게 왜 중요하냐면,
모델이 "전부 유지"라고 찍기만 해도 정확도가 73.5%가 나옵니다.
기초 6편에서 다뤘던 문제와 같습니다 — 정확도만 보면 안 됩니다.
제가 처음에 정확도 79%에 좋아했던 게 바로 이 함정이었습니다. 이탈 고객을 얼마나 잡아내는지(Recall)가 더 중요합니다.
그리고 오른쪽 차트를 보면 더 흥미로운 게 나옵니다.
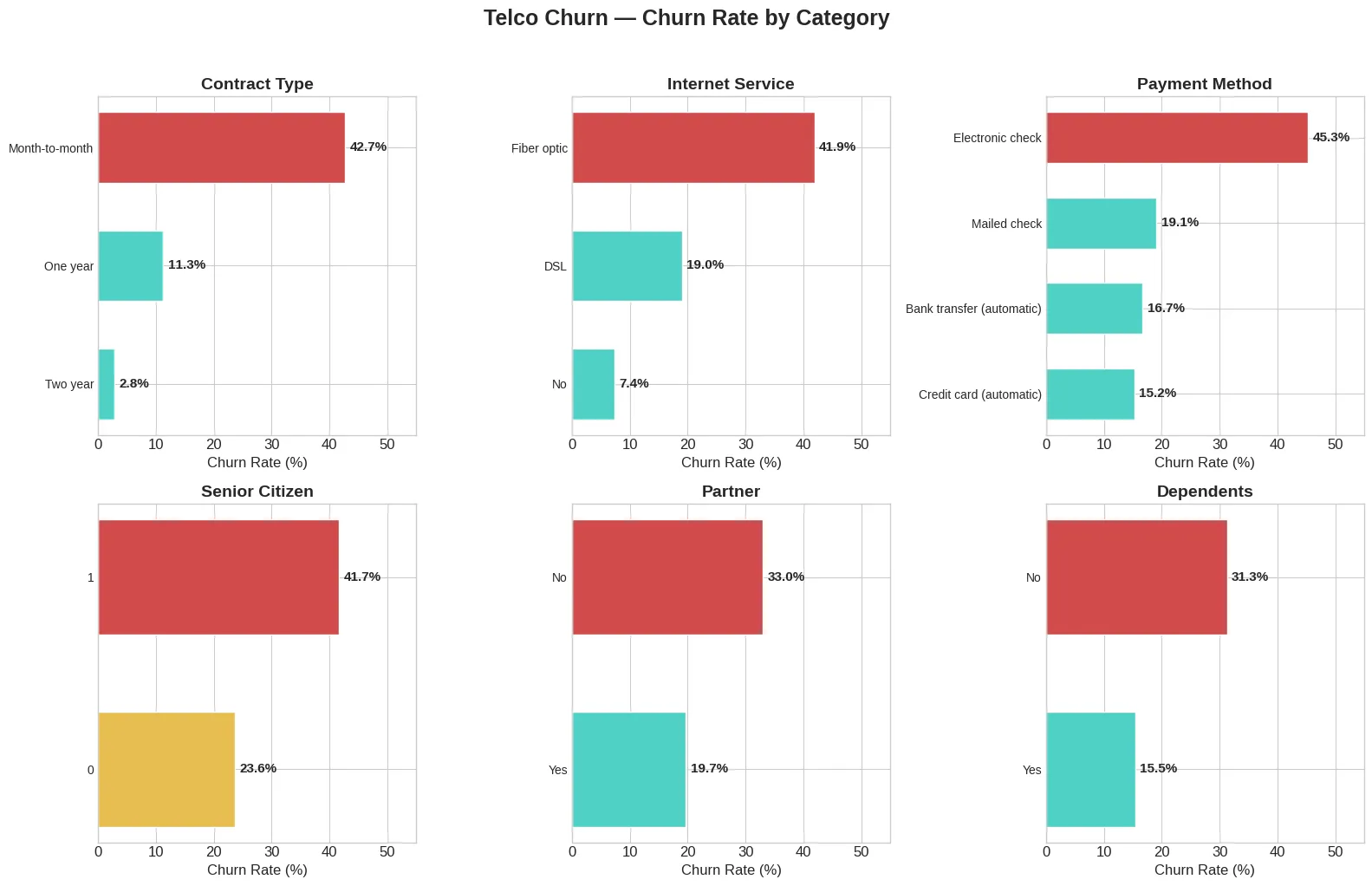
월별 계약 고객의 이탈률이 42.7%로 압도적입니다.
1년 계약은 11.3%, 2년 계약은 2.8%에 불과합니다.
아직 모델을 안 만들었는데도 계약 유형이 이탈을 예측하는 강력한 단서라는 게 바로 보입니다. 이게 EDA의 힘입니다.
# 타겟 분포 확인
print(df['Churn'].value_counts())
# No 5174 (73.5%)
# Yes 1869 (26.5%)
# 계약 유형별 이탈률
contract_churn = df.groupby('Contract')['Churn'].apply(
lambda x: (x == 'Yes').mean() * 100
)
print(contract_churn)
# Month-to-month 42.71%
# One year 11.27%
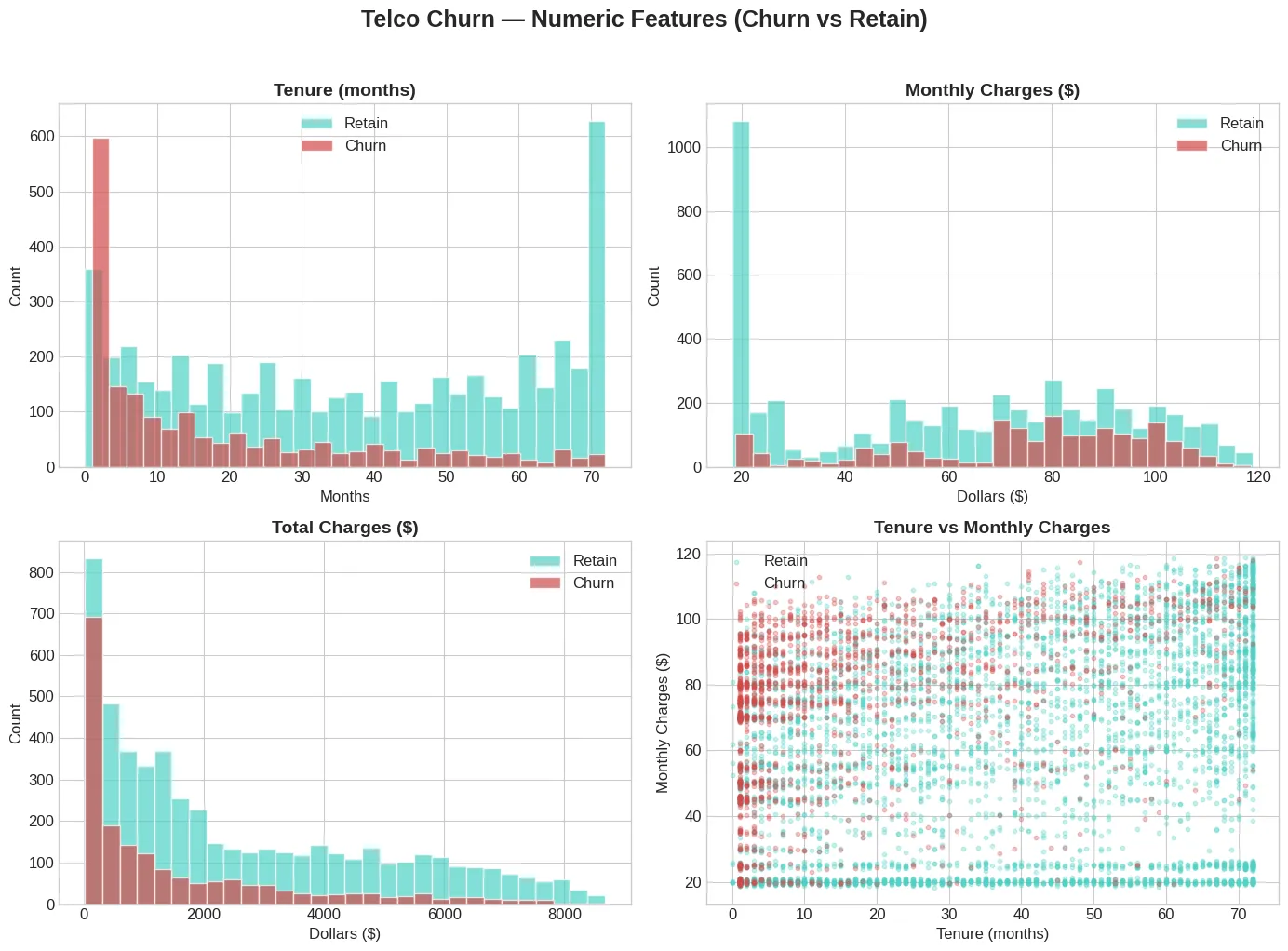
# Two year 2.83%수치형 변수에서 tenure와 월 요금은 어떤 패턴이 보이나요?
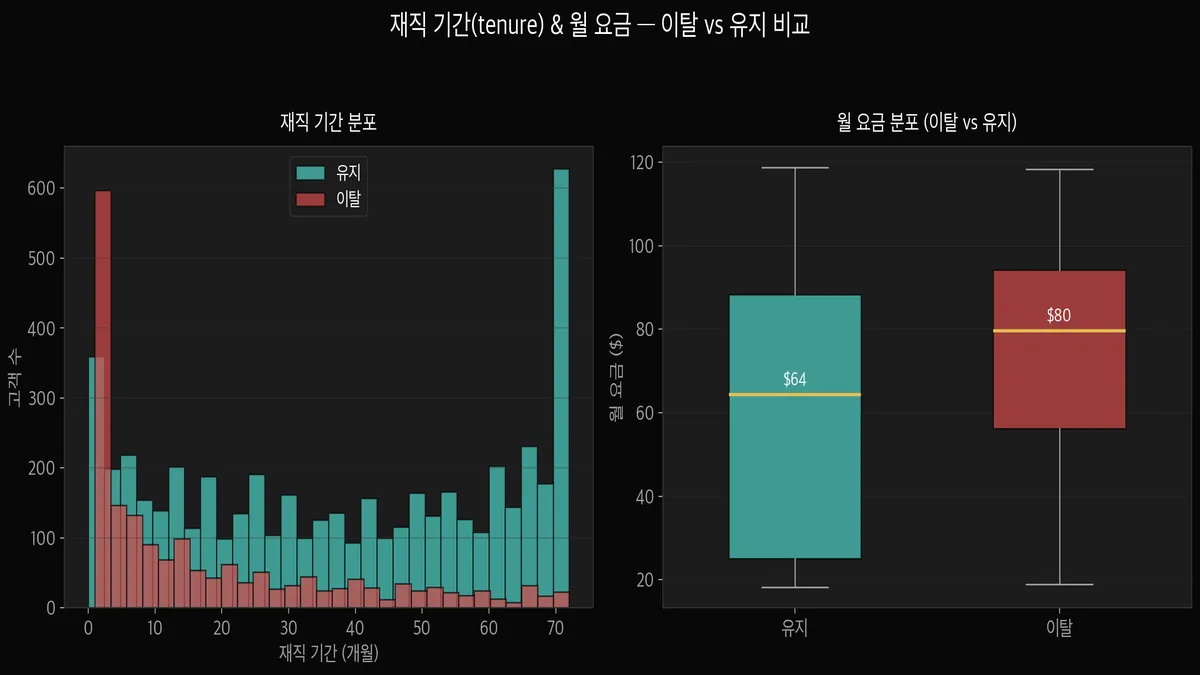
이 그래프를 처음 봤을 때 "아, 이거다" 싶었습니다.
왼쪽 히스토그램을 보면 이탈 고객(빨강)이 재직 기간 1~6개월에 확 몰려 있습니다.
반대로 유지 고객(민트)은 70개월 근처에 큰 봉우리가 있습니다.
해석하면 — 가입 초기 6개월이 고비라는 것입니다.
여기를 넘기면 장기 고객이 될 가능성이 높고, 못 넘기면 떠납니다.
통신사 입장에서는 "온보딩 6개월"에 집중 투자해야 한다는 인사이트가 나옵니다. 실제로 이런 분석이 마케팅 전략의 근거가 됩니다.
오른쪽 boxplot은 월 요금 비교입니다.
이탈 고객의 중앙값이 $80, 유지 고객은 $64입니다.
월 요금이 높을수록 이탈 확률이 올라갑니다. 비싼 요금제를 쓰는 고객일수록 "이 돈 내고 이 서비스?" 하면서 불만이 쌓이는 건 아닌지.. 직관적으로도 말이 됩니다.
# 이탈/유지별 tenure 통계
print(df.groupby('Churn')['tenure'].describe())
# 이탈 고객 평균: 17.98개월
# 유지 고객 평균: 37.57개월
# 이탈/유지별 월 요금 통계
print(df.groupby('Churn')['MonthlyCharges'].median())
# No 64.43
# Yes 79.65Jupyter Notebook 실행 결과
범주형 변수에서 서비스별 이탈률은 어떤가요?
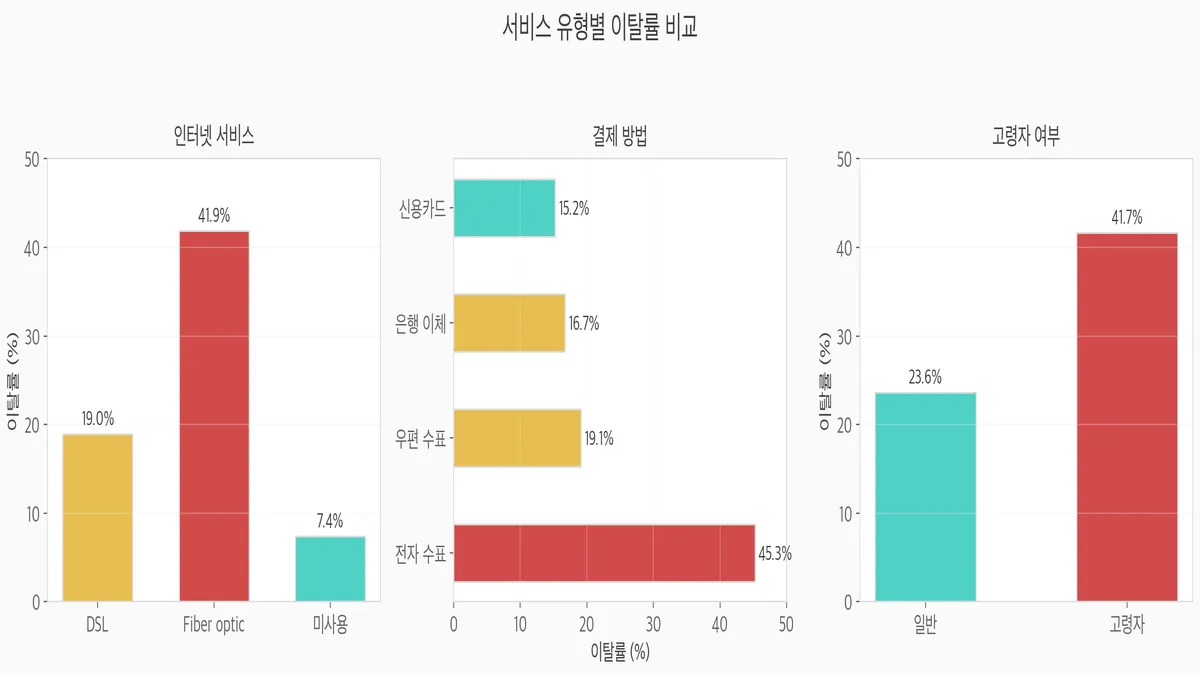
이번에는 범주형 변수를 봤는데, 여기서도 이탈률에 꽤 큰 차이가 나타났습니다.
인터넷 서비스 — Fiber optic 사용자의 이탈률이 41.9%로 가장 높음. DSL은 19.0%
결제 방법 — 전자 수표(Electronic check) 사용자가 45.3%로 압도적. 자동이체 계열은 15~19%
고령자 여부 — 고령자 이탈률 41.7%, 일반 23.6%. 거의 2배 차이
솔직히 Fiber optic 이탈률이 높은 건 처음에 이해가 안 됐습니다. 좋은 서비스인데 왜?
곰곰이 생각해보니 고속 인터넷일수록 월 요금이 높고 → 높은 요금에 대한 기대치가 높아지면서 불만으로 이어지는 것 같았습니다.
전자 수표 사용자의 이탈률이 높은 것도 재밌는 부분인데 — 자동이체가 아니라 매번 수동 결제하는 고객이니까 "해지 허들"이 낮은 것입니다. 이런 해석을 데이터에서 끌어내는 게 EDA의 재미입니다.ㅎㅎ
# 범주형 변수별 이탈률 한 번에 확인
cat_cols = ['gender', 'SeniorCitizen', 'Partner', 'Dependents',
'InternetService', 'Contract', 'PaymentMethod']
for col in cat_cols:
churn_rate = df.groupby(col)['Churn'].apply(
lambda x: (x == 'Yes').mean() * 100
)
print(f"\n[{col}]")
print(churn_rate.round(1))Jupyter Notebook 실행 결과
변수 간 상관관계는 어떻게 확인하나요?
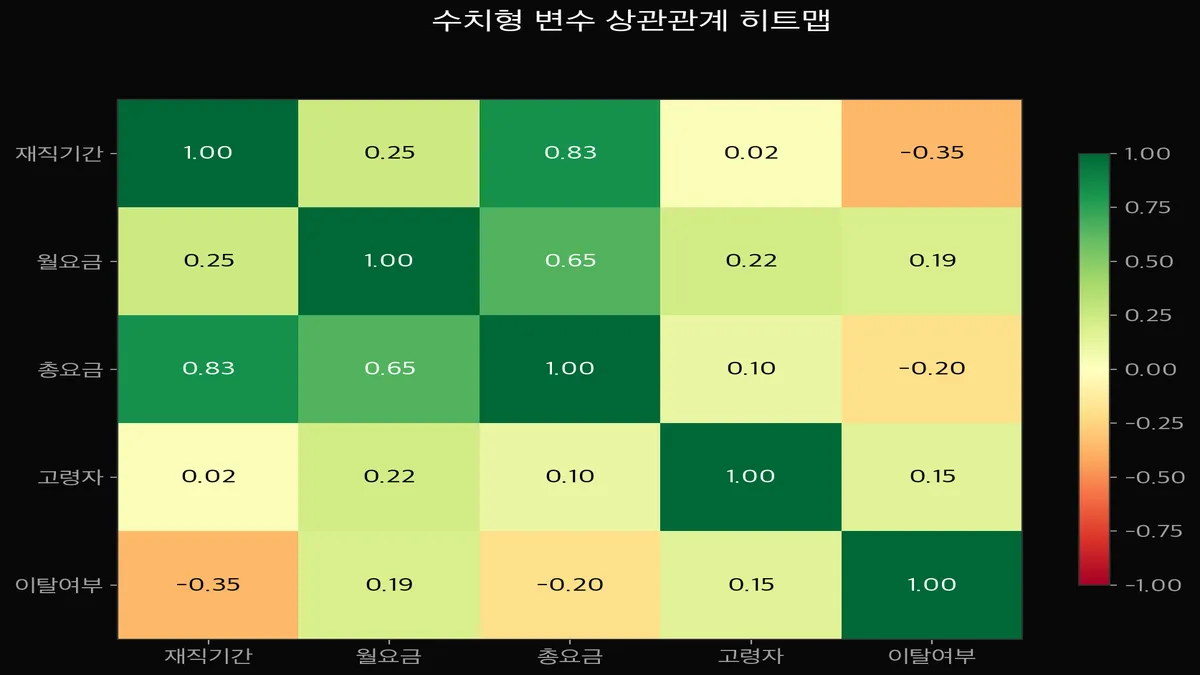
마지막으로 수치형 변수끼리의 상관관계를 히트맵으로 그려봤습니다.
여기서 앞에서 느낌적으로 봤던 패턴들이 숫자로 확인됩니다.
재직기간 ↔ 이탈: -0.35 — 오래 머물수록 이탈 확률 낮음 (가장 강한 음의 상관)
월요금 ↔ 이탈: +0.19 — 요금이 높을수록 이탈 확률 높음
재직기간 ↔ 총요금: +0.83 — 당연한 관계. 오래 있으면 총 지불액이 큼
월요금 ↔ 총요금: +0.65 — 다중공선성 주의 (중급 6편 PCA 참고)
# 상관관계 히트맵
df_num = df[['tenure', 'MonthlyCharges', 'TotalCharges', 'SeniorCitizen']].copy()
df_num['Churn'] = (df['Churn'] == 'Yes').astype(int)
corr = df_num.corr()
print(corr['Churn'].sort_values())
# tenure -0.352
# TotalCharges -0.198
# SeniorCitizen 0.151
# MonthlyCharges 0.193
그런데 여기서 하나 찝찝했던 게 있었습니다.
tenure와 TotalCharges의 상관관계가 0.83으로 매우 높습니다.
"이 두 변수를 그냥 같이 넣어도 되나..?" 싶었는데, 이건 3편(피처 엔지니어링)에서 다중공선성 처리할 때 다시 돌아올 내용입니다.
EDA에서 발견한 것들 — 정리

1. 이탈률 26.5% — 불균형 데이터. 정확도 대신 Recall/F1으로 평가해야 함
2. 핵심 이탈 변수 — 계약 유형, 재직 기간, 월 요금, 결제 방법, 인터넷 서비스
3. 데이터 문제 — TotalCharges에 결측치 11개 + 타입 변환 필요
이게 EDA입니다. 복잡한 통계 기법이 아니라,
데이터를 눈으로 확인하고, 문제와 패턴을 먼저 파악하는 과정입니다.
저처럼 이 단계를 건너뛰고 모델부터 돌리면.. 나중에 반드시 뒤통수를 맞습니다.ㅋㅋ
다음 편(2편)에서는 여기서 발견한 문제들을 직접 처리합니다.
TotalCharges 결측치 11개를 어떻게 할지, 이상치는 어떻게 다룰지 —
결측치와 이상치 실전 처리, 같이 확인해봅시다.