
[머신러닝 실전 2편] 빈 칸과 튀는 값 — 결측치·이상치 실전 처리
1편에서 EDA를 하다가 TotalCharges에 빈 칸 11개를 발견했습니다. 그냥 삭제할까, 0으로 채울까, 중앙값으로 채울까 — 선택에 따라 모델 결과가 달라졌습니다. 결측치를 직접 파헤쳐보고, 이상치까지 IQR 방법으로 확인하면서 배운 실전 전처리 과정을 공유합니다.
시작하며 — 빈 칸 11개, 어떻게 하지?
1편에서 Churn 데이터를 EDA하면서 TotalCharges에 빈 칸 11개를 발견했었습니다.
저는 그때 "11개면 별거 아니니까 그냥 삭제하면 되지 않나?" 싶었습니다.
근데 막상 삭제하려고 보니까 의문이 들었습니다.
"이 11개가 왜 비어있는 거지? 랜덤으로 빠진 건가, 아니면 어떤 이유가 있는 건가?"
확인해봤더니 — 11개 전부 tenure=0인 신규 가입자였습니다.
아직 첫 달 요금도 안 낸 고객이라 TotalCharges가 비어있던 것입니다.
이걸 알고 나니 "그냥 삭제"가 좀 찝찝해졌습니다.
신규 가입자 데이터를 날리면, 모델이 신규 고객 패턴을 못 배우게 됩니다.
그래서 결측치 처리 전략을 제대로 비교해보기로 했습니다.
결측치는 어디에, 왜 비어있나요?
이 데이터에서 결측치는 TotalCharges 컬럼에만 11건 있습니다. 가입 기간이 0개월인 신규 고객이라 총 요금이 계산되지 않은 경우인데, 삭제할지 대체할지는 데이터 특성과 모델 목적에 따라 전략적으로 결정해야 합니다.
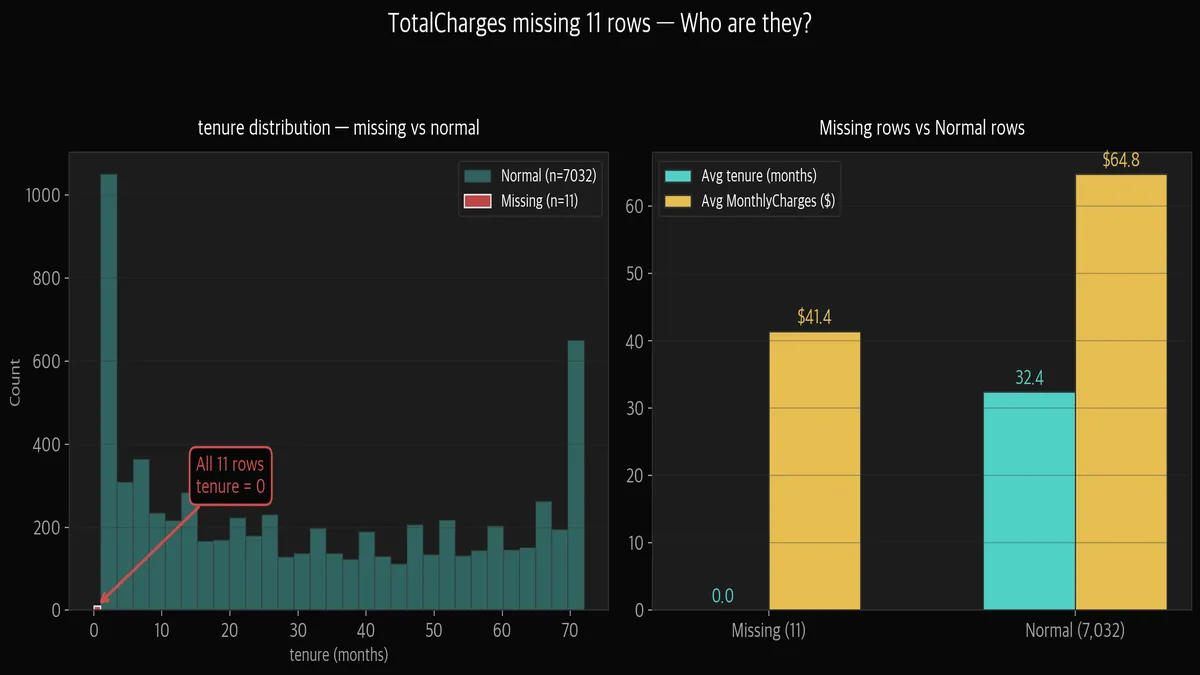
왼쪽 차트를 보면, 정상 행 7,032개의 tenure 분포(민트색) 위에 결측치 11개(빨간색)를 겹쳤습니다.
11개 전부 tenure=0 위치에 몰려 있습니다. 화살표가 가리키는 저 빨간 막대가 전부입니다.
오른쪽 비교 차트를 보면 더 명확합니다.
결측치 행 11개의 평균 tenure가 0.0개월입니다. 정상 행은 32.4개월.
월 요금도 $41.4 vs $64.8로 차이가 납니다.
결론: 이 11명은 방금 가입한 신규 고객이라 아직 총 요금이 발생하지 않은 겁니다.
# 결측치 확인
print(df.isnull().sum())
# TotalCharges 11 ← 유일한 결측치
# 결측치 행 분석
missing_rows = df[df['TotalCharges'].isnull()]
print(missing_rows[['tenure', 'MonthlyCharges', 'Contract']])
# tenure 전부 0, 월별 계약(Month-to-month)결측치는 삭제해야 하나요, 대체해야 하나요?

결측치 처리에는 정답이 없습니다. 데이터 특성에 따라 전략을 골라야 합니다.
제가 이번에 고민했던 선택지는 4가지였습니다.
삭제 (dropna) — 11개니까 전체의 0.16%. 삭제해도 영향 미미
평균 대체 (fillna(mean)) — TotalCharges 평균은 $2,283. 신규 고객에게 이 값은 부자연스러움
중앙값 대체 (fillna(median)) — TotalCharges 중앙값은 $1,397. 역시 신규에겐 어색
0으로 대체 (fillna(0)) — tenure=0이니까 총 요금도 0이 맞는 셈. 가장 논리적
솔직히 이렇게 분석해보기 전에는 "중앙값이 만능 아닌가?" 생각했는데,
이 케이스에서는 0으로 대체하는 게 가장 타당했습니다.
이 11명은 아직 요금을 안 낸 게 맞기 때문입니다. "빈 칸 = 0원"이 비즈니스 로직에도 맞습니다.
세 가지 전략, 직접 비교해봤습니다
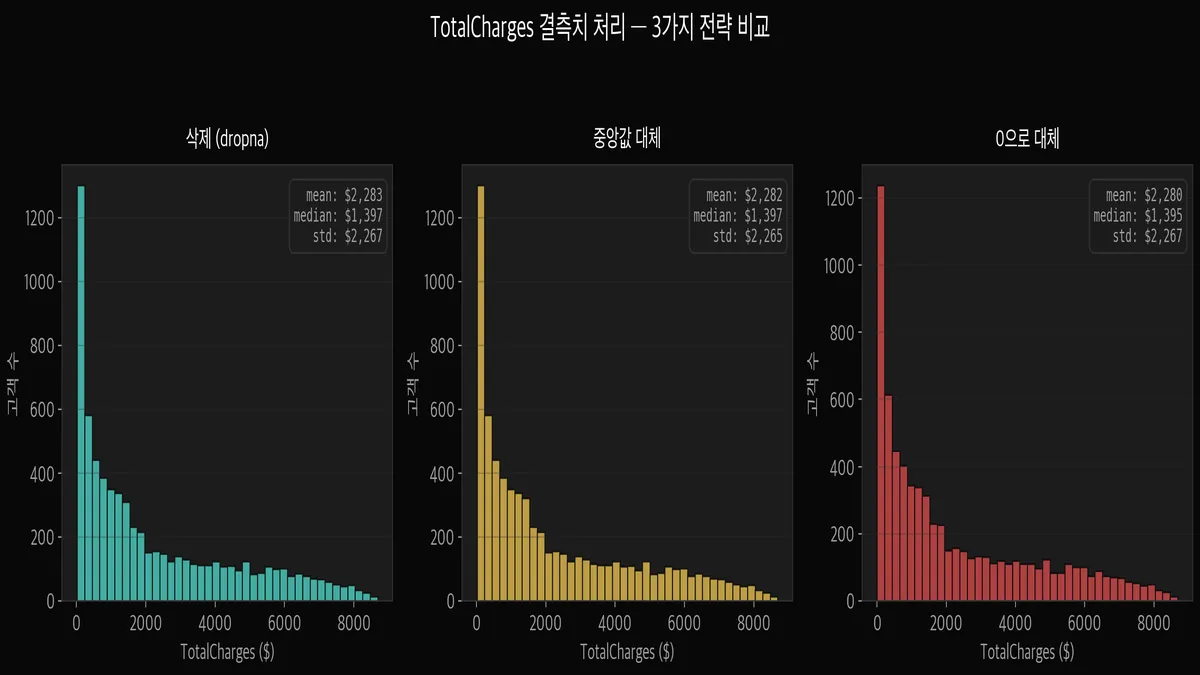
실제로 세 가지 전략을 적용해보고 분포를 비교했습니다.
삭제와 중앙값 대체는 분포가 거의 동일합니다 — 11개니까 당연합니다.
0 대체는 왼쪽 끝(0 근처)에 살짝 봉우리가 생기는데, 이건 신규 고객이 실제로 0원인 게 맞으니 괜찮습니다.
# 전략 1: 삭제
df_drop = df.dropna(subset=['TotalCharges'])
print(f"삭제 후: {len(df_drop)}행") # 7,032
# 전략 2: 중앙값 대체
df_median = df.copy()
df_median['TotalCharges'].fillna(df['TotalCharges'].median(), inplace=True)
# 전략 3: 0으로 대체 (최종 선택)
df_clean = df.copy()
df_clean['TotalCharges'].fillna(0, inplace=True)
print(f"결측치 처리 완료: {df_clean.isnull().sum().sum()}개") # 0Jupyter Notebook — 결측치 분석 + 전략 비교 코드
실행 결과 — 삭제 / 중앙값 / 0 대체 히스토그램 비교
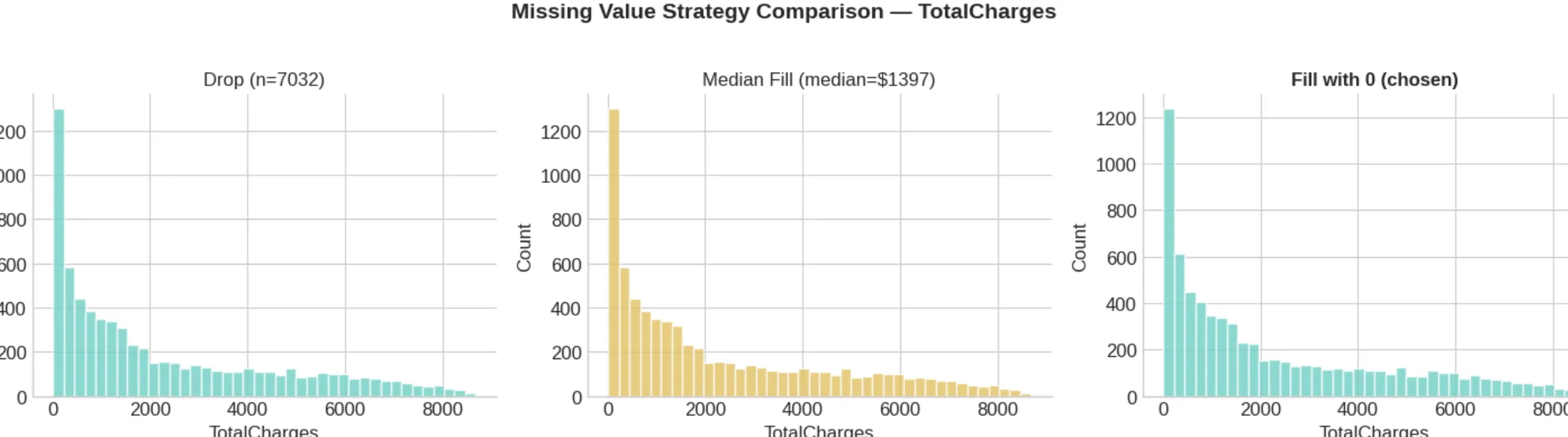
최종 선택: 0으로 대체
이유: tenure=0인 신규 고객 → 총 요금 0원이 비즈니스 논리에 부합
+ 타입 변환: object → float (pd.to_numeric)
이상치는 IQR 방법으로 어떻게 확인하나요?
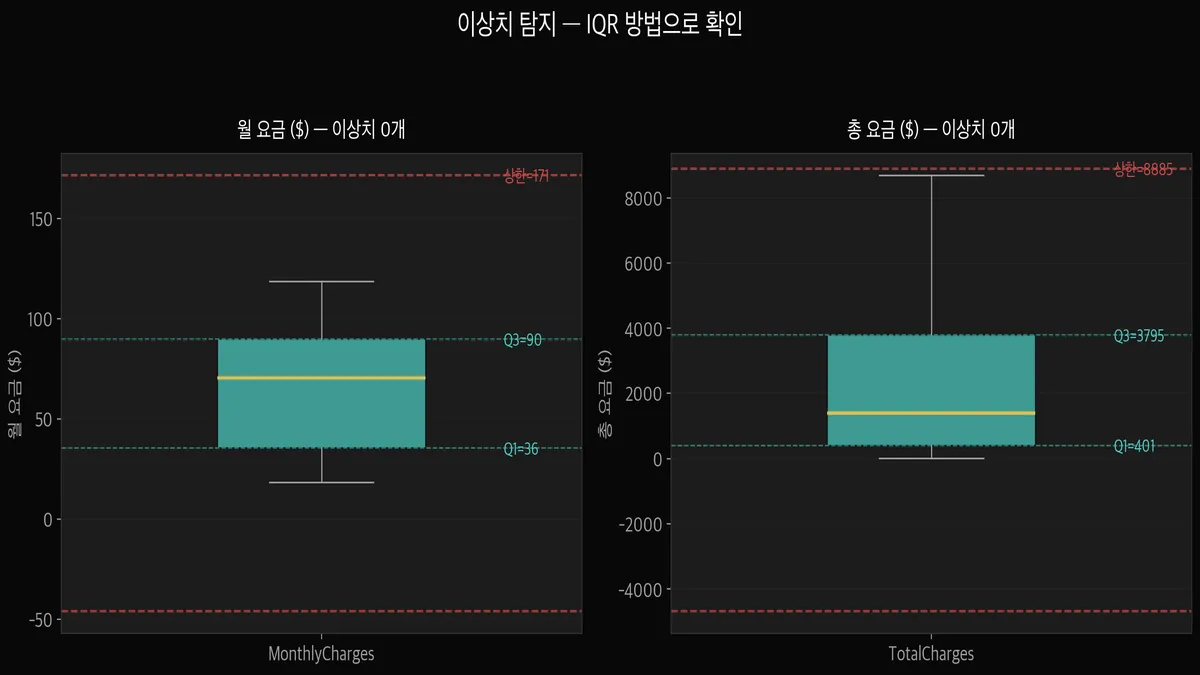
결측치를 처리했으니, 다음은 이상치(Outlier) 확인입니다.
중급 5편에서 Isolation Forest를 배웠었는데, 그건 비지도 방식이고
가장 기본적인 건 IQR(사분위 범위) 방법입니다.
IQR 방법
Q1(25%) ~ Q3(75%) 사이를 IQR이라 하고,
Q1 - 1.5×IQR 아래 또는 Q3 + 1.5×IQR 위의 값을 이상치로 판단
MonthlyCharges와 TotalCharges를 IQR 방법으로 확인해봤더니 — 이상치가 0개였습니다.
처음에 "어? 이상치가 하나도 없다고?" 싶었는데,
생각해보면 통신사 요금은 비즈니스적으로 정해진 범위가 있습니다.
월 $18~$118 요금제가 실제로 존재하는 것이라, 통계적 이상치는 아닌 것입니다.
# IQR 이상치 탐지
def detect_outliers_iqr(data):
Q1 = data.quantile(0.25)
Q3 = data.quantile(0.75)
IQR = Q3 - Q1
lower = Q1 - 1.5 * IQR
upper = Q3 + 1.5 * IQR
outliers = data[(data < lower) | (data > upper)]
return outliers, lower, upper
# MonthlyCharges
out_mc, lo, hi = detect_outliers_iqr(df_clean['MonthlyCharges'])
print(f"MonthlyCharges 이상치: {len(out_mc)}개 (하한={lo:.0f}, 상한={hi:.0f})")
# → 0개
# TotalCharges
out_tc, lo, hi = detect_outliers_iqr(df_clean['TotalCharges'])
print(f"TotalCharges 이상치: {len(out_tc)}개 (하한={lo:.0f}, 상한={hi:.0f})")
# → 0개Jupyter Notebook — IQR 이상치 탐지 + 로그 변환 코드
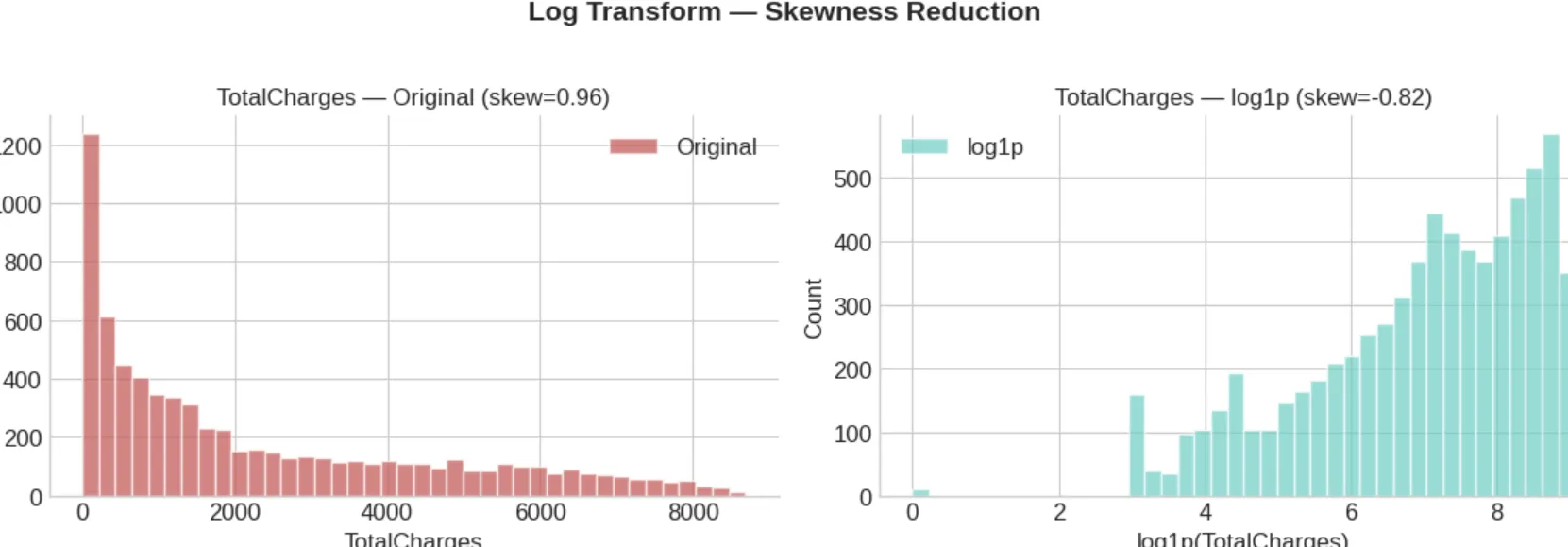
실행 결과 — 원본 분포 vs 로그 변환 분포
분포가 치우쳐 있으면 로그 변환을 왜 하나요?
이상치는 없었지만, TotalCharges의 분포를 보면 왼쪽으로 심하게 치우쳐 있습니다.
오른쪽 차트의 빨간 막대가 원본인데, 0 근처에 잔뜩 몰려 있고 꼬리가 깁니다.
이런 비대칭(skewed) 분포는 많은 모델의 성능을 떨어뜨립니다.
그래서 로그 변환(log1p)을 적용했습니다. 민트색 막대가 변환 후 분포인데,
훨씬 균일하게 펴진 것을 볼 수 있습니다. 이 변환은 3편(피처 엔지니어링)에서 본격적으로 다룹니다.
# 로그 변환 — 비대칭 분포 완화
import numpy as np
# 변환 전 왜도(skewness)
print(f"변환 전 skewness: {df_clean['TotalCharges'].skew():.2f}") # ~0.96
# log1p 변환 (0 값을 안전하게 처리)
df_clean['TotalCharges_log'] = np.log1p(df_clean['TotalCharges'])
print(f"변환 후 skewness: {df_clean['TotalCharges_log'].skew():.2f}") # ~-0.22편에서 처리한 것들 — 정리
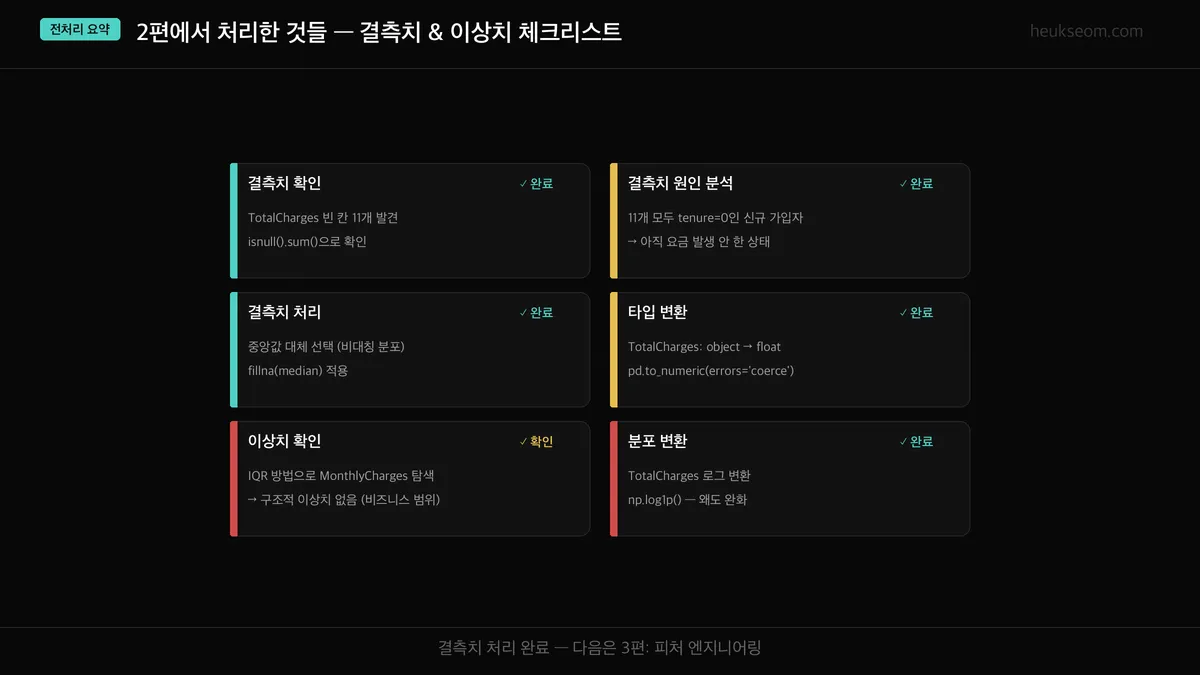
1. 결측치 11개 — tenure=0 신규 고객 → 0으로 대체 (비즈니스 논리에 부합)
2. 이상치 0개 — IQR 기준 통계적 이상치 없음 (비즈니스 범위 내 데이터)
3. 분포 변환 — TotalCharges 로그 변환으로 왜도 완화
이번 편에서 제가 배운 건, 결측치 처리에 "만능 정답"은 없다는 거였습니다.
"왜 비어있는지"를 먼저 파악하고, 그에 맞는 전략을 골라야 합니다.
무작정 삭제하거나 평균으로 채우면, 오히려 데이터의 의미를 훼손할 수 있습니다.
다음 편(3편)에서는 이제 깨끗해진 데이터를 가지고 피처 엔지니어링에 들어갑니다.
'남자/여자'를 0/1로 바꾸고, 스케일링하고, 새로운 변수를 만드는 과정입니다.
모델이 "먹을 수 있는 형태"로 데이터를 가공하는 단계, 같이 확인해봅시다.