
[머신러닝 실전 4편] 이탈 예측, 어떤 모델이 이기나 — 5개 모델 실전 비교
전처리를 끝내고 나니 '어떤 모델을 써야 하지?'가 막막했습니다. 로지스틱 회귀? 랜덤포레스트? 그래디언트 부스팅? 실전에서는 하나만 골라서 올인하는 게 아니라, 여러 개를 빠르게 돌려보고 비교합니다. DummyClassifier로 베이스라인을 세우고, 5개 모델을 교차검증으로 공정 비교한 결과를 정리했습니다.
시작하며 — 어떤 모델을 써야 하지?
3편까지 해서 데이터가 드디어 모델에 넣을 수 있는 상태가 되었습니다.
인코딩도 했고, 스케일링도 했고, 파생변수도 만들었습니다.
그런데 막상 모델을 고르려니 막막했습니다.
로지스틱 회귀? 랜덤포레스트? SVM? XGBoost?
기초 시리즈에서 개별적으로는 배웠는데, 실전에서 어떤 걸 써야 하는지는 또 다른 문제였습니다.
정답부터 말하면 — 여러 개를 돌려보고 비교하는 게 실전입니다.
이번 편에서는 DummyClassifier로 기준선(베이스라인)을 세우고,
5개 모델을 교차검증으로 비교한 뒤,
Confusion Matrix까지 해석해봅니다.
모델 선택은 어떤 프로세스로 진행하나요?
모델 선택은 5단계로 진행됩니다. DummyClassifier로 베이스라인을 잡고, 후보 모델 5개를 선정한 뒤, 교차검증으로 공정하게 비교하고, Accuracy/F1/Recall 등 평가지표로 판단해서 최종 모델을 선택합니다.
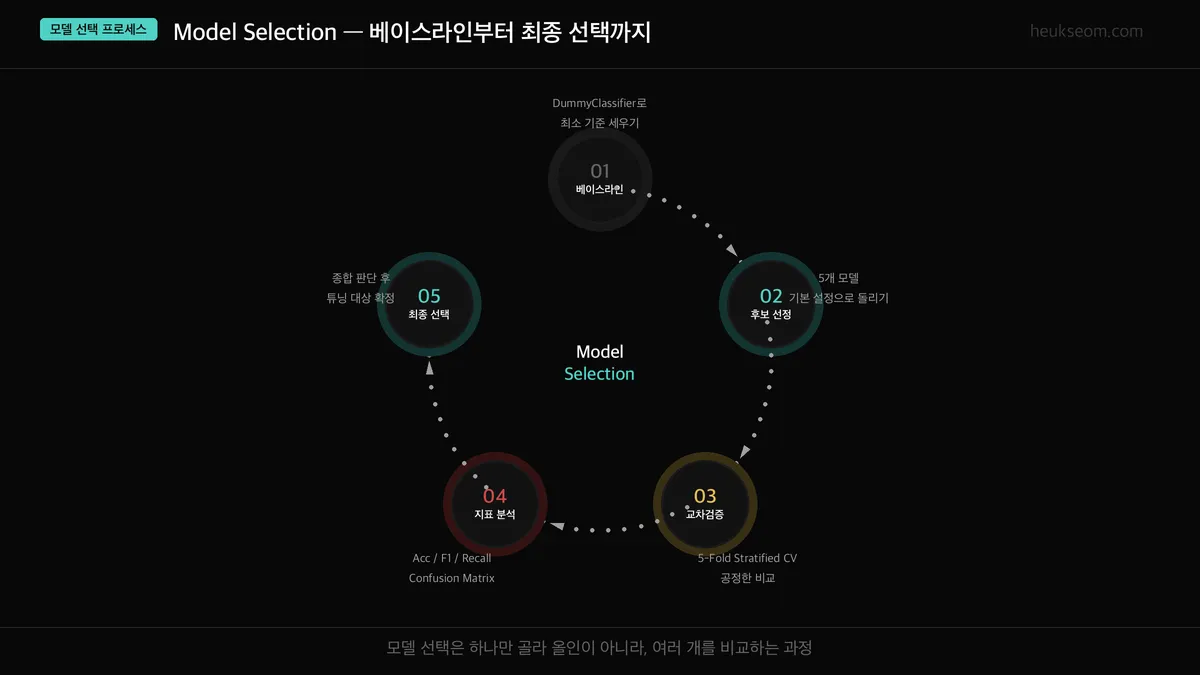
모델 선택은 이 순서를 따릅니다.
1) 베이스라인 세우기 → 2) 후보 모델 돌려보기 → 3) 교차검증으로 공정 비교 → 4) 평가지표 분석 → 5) 최종 선택.
하나씩 해봅니다.
Step 1 — 베이스라인: DummyClassifier
모델을 비교하려면 먼저 "최소한 이것보다는 나아야 한다"는 기준이 필요합니다.
그게 베이스라인입니다.
sklearn의 DummyClassifier는 아무 학습 없이 "가장 많은 클래스로만 예측"합니다.
Churn 데이터에서 이탈하지 않은 고객이 73.5%이니까,
모든 고객에게 "이탈 안 함"이라고 찍으면 정확도가 73.5%입니다.
DummyClassifier (strategy='most_frequent')
Accuracy: 0.7346 | F1: 0.0000 | Recall: 0.0000
정확도 73.5%라고 하면 괜찮아 보이지만, 이탈 고객을 단 한 명도 못 잡습니다.
F1=0, Recall=0. 이게 바로 "Accuracy만 보면 안 되는 이유"입니다.
이제 이 73.5%보다 의미 있게 높은 모델을 찾아야 합니다.
특히 이탈 고객을 실제로 잡아내는지(Recall)가 중요합니다.
Step 2 — 후보 모델 5개
기초 시리즈에서 배운 모델 중 분류에 쓸 수 있는 5개를 골랐습니다.
1. Logistic Regression — 가장 기본적인 분류 모델. 해석이 쉽고 빠릅니다.
2. Random Forest — 결정 트리 여러 개의 다수결. 과적합에 강합니다.
3. Gradient Boosting — 약한 모델을 순차적으로 쌓아 올림. 보통 성능이 좋습니다.
4. SVM (RBF) — 고차원에서 결정 경계를 찾음. 스케일링이 중요합니다.
5. KNN (k=5) — 가장 가까운 5개 이웃의 다수결. 단순하지만 때로 효과적입니다.
5개 모두 기본 하이퍼파라미터(default)로 돌립니다.
튜닝은 5편에서 할 거니까, 지금은 "기본 설정으로 누가 제일 나은지"만 봅니다.
Step 3 — 교차검증으로 공정 비교
모델 하나를 한 번 돌려서 "이게 좋다"고 판단하면 위험합니다.
train/test를 어떻게 나누느냐에 따라 결과가 달라질 수 있으니까요.
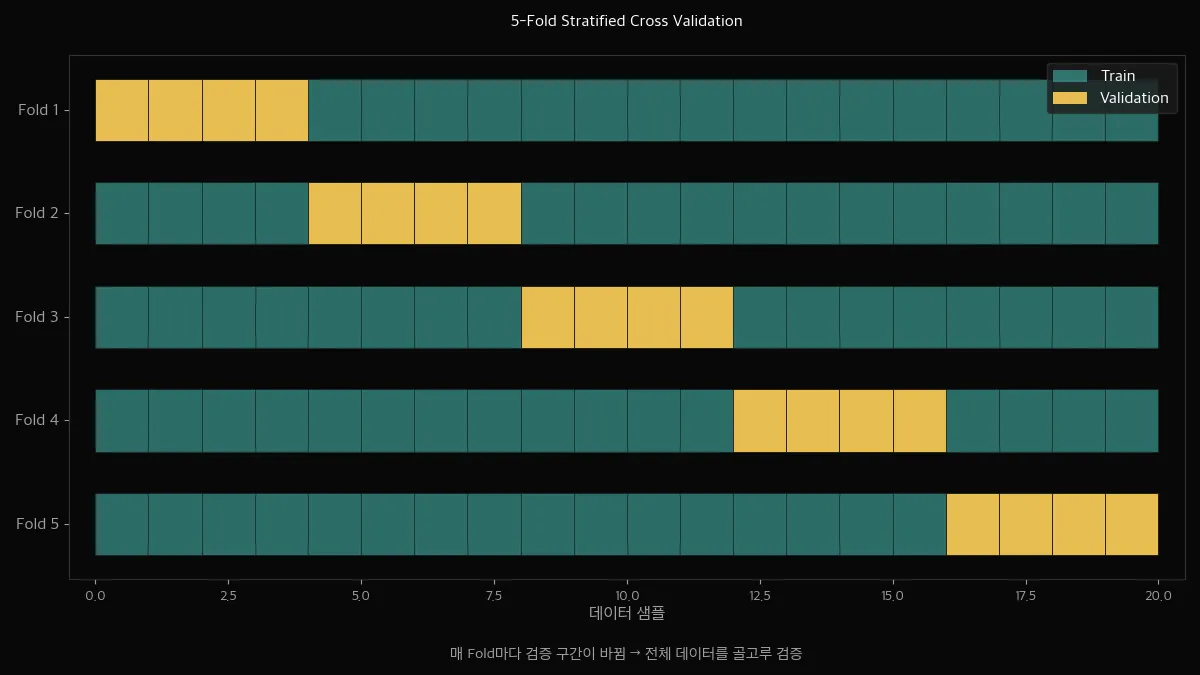
그래서 5-Fold Stratified Cross Validation을 씁니다.
데이터를 5등분해서, 매번 다른 조각을 테스트셋으로 쓰고 나머지 4개로 학습합니다.
이걸 5번 반복해서 평균을 내면, 한 번의 운에 좌우되지 않는 공정한 점수가 나옵니다.
"Stratified"가 붙은 이유는 — 각 Fold에서 이탈 비율(26.5%)을 동일하게 유지하기 때문입니다.
불균형 데이터에서는 이게 중요합니다. 그냥 KFold를 쓰면 어떤 Fold에 이탈 고객이 몰릴 수 있습니다.
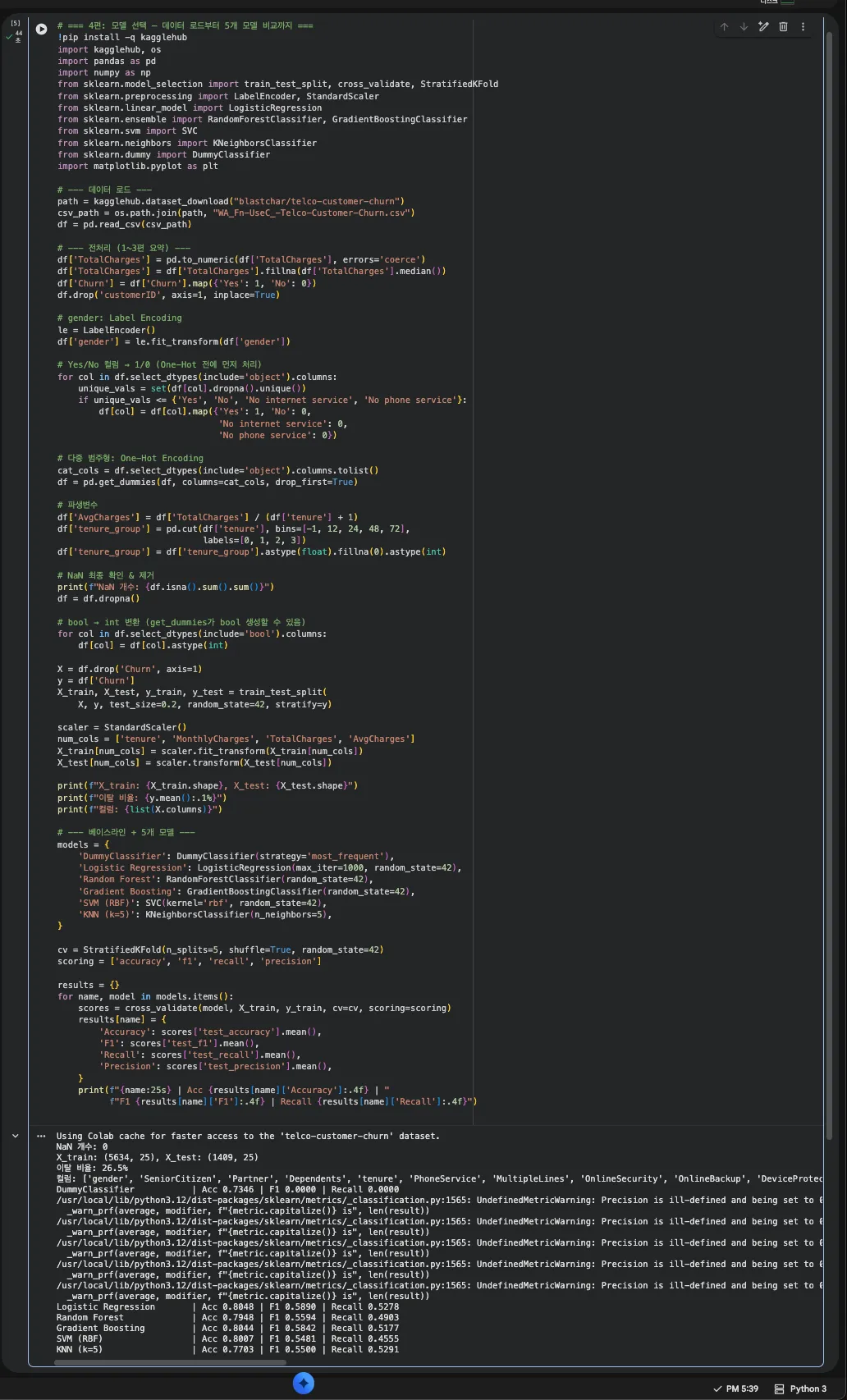
Jupyter 실행 코드 — 6개 모델 교차검증 비교
Step 4 — 결과 비교: 누가 이겼나
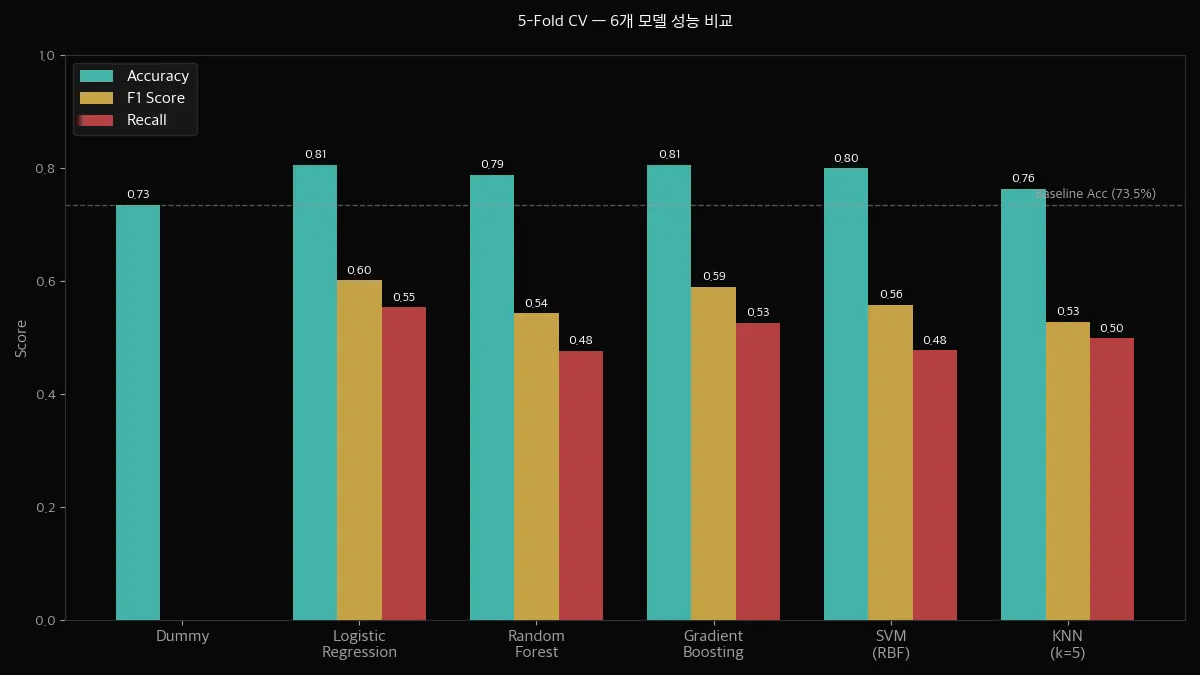
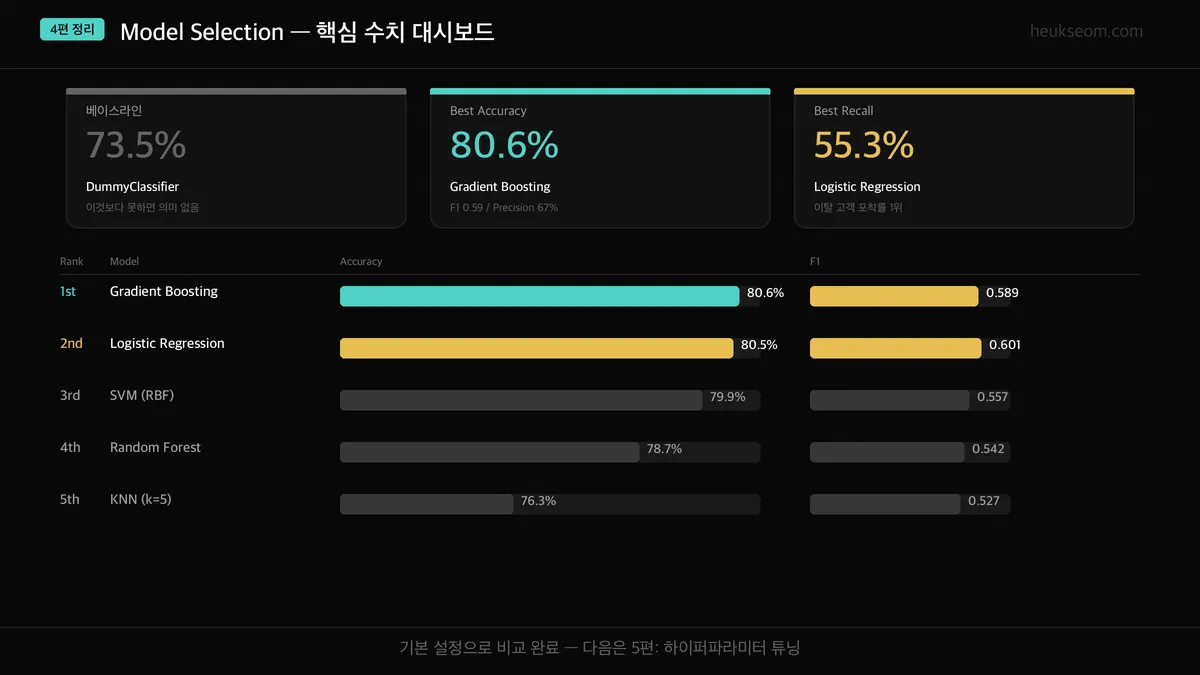
5-Fold CV 결과를 정리하면 이렇습니다.
| 모델 | Accuracy | F1 | Recall | Precision |
|---|---|---|---|---|
| DummyClassifier | 0.7346 | 0.0000 | 0.0000 | — |
| Logistic Regression | 0.8053 | 0.6010 | 0.5532 | 0.6581 |
| Random Forest | 0.7873 | 0.5423 | 0.4756 | 0.6315 |
| Gradient Boosting | 0.8058 | 0.5892 | 0.5254 | 0.6712 |
| SVM (RBF) | 0.7992 | 0.5573 | 0.4767 | 0.6710 |
| KNN (k=5) | 0.7632 | 0.5271 | 0.4981 | 0.5602 |
차트와 표를 같이 보면 몇 가지가 보입니다.
1. Accuracy만 보면 다 비슷해 보입니다
Logistic Regression(80.5%), Gradient Boosting(80.6%), SVM(79.9%) — 차이가 1% 이내입니다.
그런데 F1과 Recall을 보면 차이가 확 벌어집니다.
2. DummyClassifier의 Accuracy가 73.5%
아무것도 안 해도 73.5%입니다. 그러니까 80%라는 숫자가 "겨우 7% 개선"인 겁니다.
Accuracy만 보면 과대평가하기 쉽습니다.
3. Gradient Boosting이 종합 1위
Accuracy와 F1 모두 최고점입니다. 다만 Recall은 Logistic Regression이 약간 더 높습니다.
"이탈 고객을 많이 잡는 것"이 목표라면 LR도 고려할 만합니다.
4. KNN은 Accuracy도 낮고 Precision도 낮습니다
기본 설정 k=5에서는 다른 모델에 비해 전반적으로 부족합니다.
Accuracy, F1, Recall, Precision이 각각 뭔가요?
표에 지표가 4개나 있으니 헷갈릴 수 있습니다. 간단하게 정리합니다.
Accuracy — 전체 중에 맞춘 비율. 직관적이지만 불균형 데이터에서는 함정이 있습니다.
Precision — "이탈이라고 예측한 것" 중 실제 이탈 비율. 잘못된 알림을 줄이고 싶을 때 중요합니다.
Recall — "실제 이탈 고객" 중 잡아낸 비율. 놓치는 고객을 줄이고 싶을 때 중요합니다.
F1 Score — Precision과 Recall의 조화평균. 둘 다 어느 정도 챙기고 싶을 때 씁니다.
통신사 입장에서 생각하면 — 이탈할 고객을 놓치면 그 고객은 그냥 떠납니다.
잘못 잡는 건 "혜택 제공"으로 끝나지만, 놓치는 건 매출 손실입니다.
그래서 이탈 예측에서는 Recall이 특히 중요합니다.
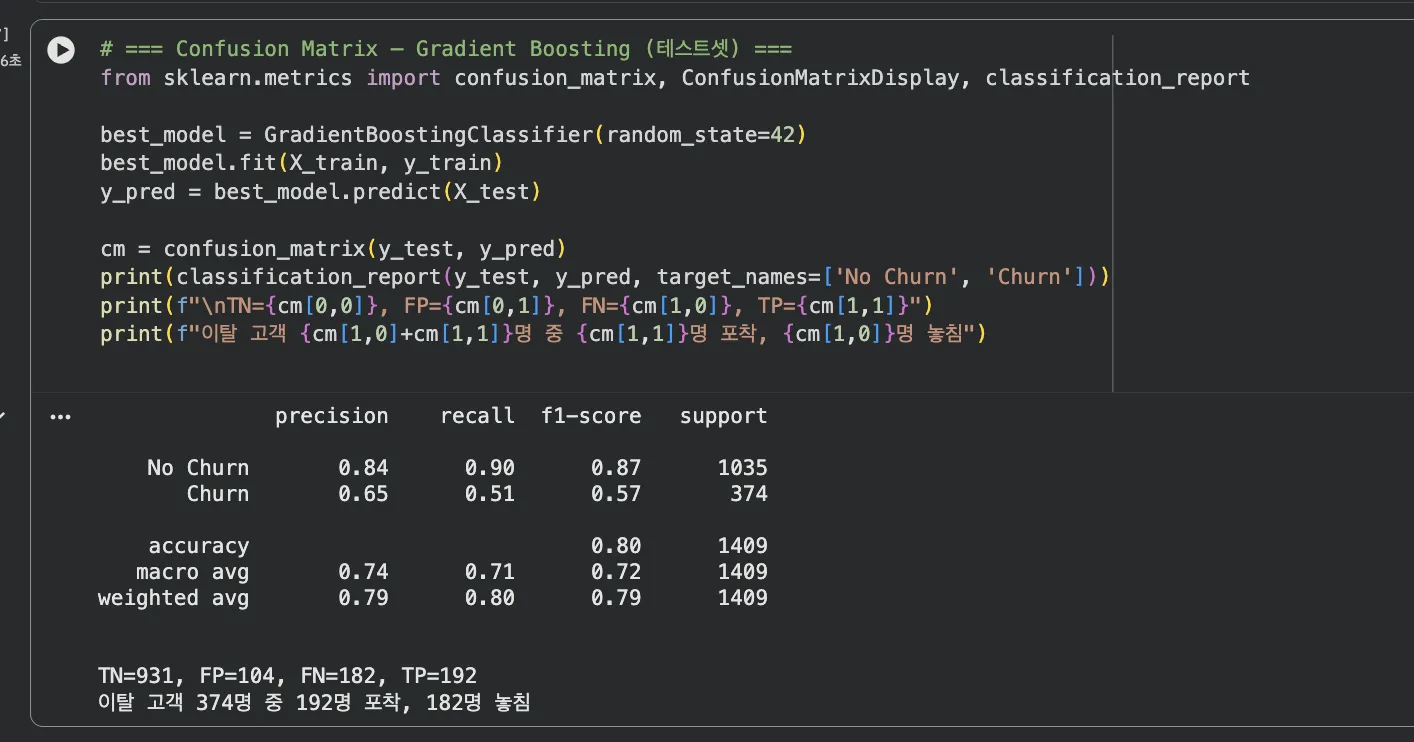
Jupyter 실행 코드 — Confusion Matrix
Step 5 — Confusion Matrix 해석

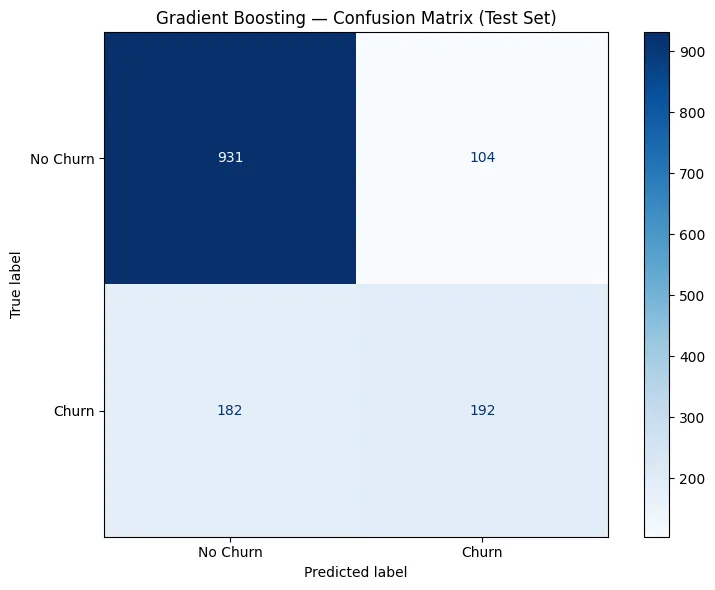
종합 1위인 Gradient Boosting의 Confusion Matrix를 자세히 봅니다.
테스트셋 1,409명에 대한 결과입니다.
TN (True Negative) = 940명
이탈 안 한 고객을 "이탈 안 함"으로 정확하게 예측. 제일 많습니다.
TP (True Positive) = 193명
이탈 고객을 "이탈"로 정확하게 예측. 이걸 더 늘려야 합니다.
FP (False Positive) = 95명
이탈 안 할 고객을 "이탈"로 잘못 예측. 오탐입니다.
이 고객들에게 불필요한 혜택을 제공하게 됩니다. 비용이 발생하지만 치명적이진 않습니다.
FN (False Negative) = 181명
이탈할 고객을 "이탈 안 함"으로 놓침. 이게 제일 아픕니다.
이 고객들은 아무 조치 없이 떠나게 됩니다.
이탈 고객 374명 중 193명을 잡았고, 181명을 놓쳤습니다.
Recall = 193 / 374 = 52%. 절반 정도만 잡는 겁니다.
Precision = 193 / 288 = 67%. 이탈이라고 찍은 것 중 2/3는 맞았습니다.
현재 기본 설정으로는 이 정도입니다. 5편에서 튜닝으로 개선해봅니다.
정리 — 이번 편에서 확인한 것
1. DummyClassifier로 베이스라인을 세우면 Accuracy 73.5%. 이것보다 못하면 모델의 의미가 없습니다.
2. 기본 설정 기준, Gradient Boosting이 Accuracy 80.6% / F1 0.59로 종합 1위였습니다.
3. 하지만 최고 모델도 이탈 고객의 48%를 놓칩니다. 불균형 데이터의 한계입니다.
이번 편에서 가장 인상 깊었던 건, Accuracy의 함정이었습니다.
아무것도 안 해도 73.5%가 나오는 상황에서 80%는 대단한 게 아니었습니다.
F1, Recall, Confusion Matrix까지 봐야 모델의 진짜 실력이 보였습니다.
다음 편(5편)에서는 하이퍼파라미터 튜닝을 합니다.
같은 Gradient Boosting이라도 셋팅을 바꾸면 성능이 달라집니다.
GridSearch, RandomSearch로 최적 조합을 찾아봅니다.