
[벡터#4 데이터 추출] 정규표현식으로 이메일 주소 찾기
100페이지 문서에서 이메일 빠르게 추출! 엑셀 '찾기'보다 강력한 정규표현식으로 반복 작업을 크게 줄이는 방법을 배웁니다.
워밍업: 이런 적 있으시죠?
회사에서 이런 상황 겪어보신 적 있나요?
- 고객 명단 엑셀 파일에 이메일 주소가 뒤죽박죽 섞여있어요
- PDF 계약서에서 연락처만 골라내야 하는데 페이지가 100장이에요
- "영문+숫자+특수문자 포함" 비밀번호 규칙을 자동으로 체크하고 싶어요
이럴 때 정규표현식이 유용하게 쓸 수 있어요.
정규표현식으로 이메일을 어떻게 찾나요?
정규표현식은 "이메일 주소처럼 생긴 패턴"을 컴퓨터에게 알려주는 방법이에요. Python re 모듈의 findall() 함수 하나면 100페이지 문서에서도 모든 이메일을 한 번에 추출할 수 있고, Ctrl+F로 일일이 찾는 것보다 훨씬 빠르고 정확합니다.
100페이지짜리 계약서에서 이메일 주소만 찾아내야 한다고 상상해보세요. Ctrl+F로 일일이 찾으면 1시간, 정규표현식을 쓰면? 빠르게 완료됩니다.
왜 정규표현식을 배워야 할까?
회사에서 이런 상황을 겪어본 적 있나요?
- 고객 명단 엑셀 파일에 이메일 주소가 뒤죽박죽 섞여있어요
- PDF 계약서에서 연락처만 골라내야 하는데 페이지가 100장이에요
- "영문+숫자+특수문자 포함" 비밀번호 규칙을 자동으로 체크하고 싶어요
이럴 때 정규표현식(Regular Expression, Regex)이 유용하게 쓸 수 있어요. 엑셀의 "찾기" 기능보다 강력하고, 반복 작업을 크게 줄여줄 수 있어요.

실생활에서 이렇게 써요
회사 업무:
- 영업팀: 고객 리스트 1,000건에서 이메일만 자동 추출
- 인사팀: 이력서 PDF에서 전화번호 수집
- 개발팀: 사용자 입력값이 형식에 맞는지 자동 검증
일상생활:
- 명함 사진에서 연락처만 골라내기
- 웹페이지에서 모든 링크 주소 한번에 수집
- 카드번호를 "1234-****-****-5678" 형식으로 마스킹
1. 정규표현식이 뭔가요?
일일이 찾기 vs 패턴으로 찾기
100페이지 문서에서 이메일을 찾는다고 해봐요.
방법 1: Ctrl+F로 일일이 찾기
1. "gmail.com" 검색 → 복사
2. "naver.com" 검색 → 복사
3. "daum.net" 검색 → 복사
...
→ 1시간 소요방법 2: 정규표현식으로 패턴 찾기
import re
pattern = r'[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}'
emails = re.findall(pattern, text)
→ 완료!정규표현식은 "이메일 주소처럼 생긴 것"이라는 패턴을 컴퓨터에게 알려주는 방법이에요. 그럼 컴퓨터가 자동으로 찾아줘요.
2. Python re 모듈 3총사
Python에는 정규표현식을 다루는 re 모듈이 있어요. 여기서 가장 자주 쓰는 함수 3개를 알아볼게요.

match() - "~로 시작하는가?"
텍스트가 처음부터 패턴과 일치하는지 확인해요.
import re
text1 = "010-1234-5678입니다"
text2 = "전화번호는 010-1234-5678"
pattern = r'd{3}-d{4}-d{4}'
# text1: 처음부터 전화번호로 시작 → 찾음!
result1 = re.match(pattern, text1)
print(result1) # <re.Match object> → 찾음!
# text2: 처음이 "전화번호는"으로 시작 → 못 찾음
result2 = re.match(pattern, text2)
print(result2) # None → 못 찾음언제 쓸까?
- 사용자 입력이 형식에 맞는지 처음부터 확인할 때
- 예: "010으로 시작하는 전화번호만 받을게요"
search() - "어딘가에 있는가?"
텍스트 전체에서 패턴을 찾아요. 처음 발견한 것만 반환합니다.
text = "제 번호는 010-1234-5678이고, 회사는 02-123-4567입니다"
# 첫 번째 전화번호만 찾음
result = re.search(pattern, text)
print(result.group()) # 010-1234-5678언제 쓸까?
- 긴 문서에서 첫 번째로 등장하는 패턴만 찾을 때
- 예: "이 문서에 이메일이 하나라도 있나요?"
findall() - "전부 찾아줘!"
텍스트에서 패턴과 일치하는 모든 것을 리스트로 반환해요.
text = "제 번호는 010-1234-5678이고, 회사는 02-123-4567입니다"
# 모든 전화번호 찾기
result = re.findall(pattern, text)
print(result) # ['010-1234-5678', '02-123-4567']언제 쓸까?
- 문서에서 모든 패턴을 한번에 수집할 때
- 예: "고객 리스트에서 모든 이메일 주소 뽑아줘"
3. 이메일 주소 패턴 만들기
이메일 주소는 어떻게 생겼나요?
[email protected]크게 3부분으로 나눠요:
- 사용자명 (user.name)
- @ 기호
- 도메인 (company.co.kr)
이걸 정규표현식으로 표현하면?
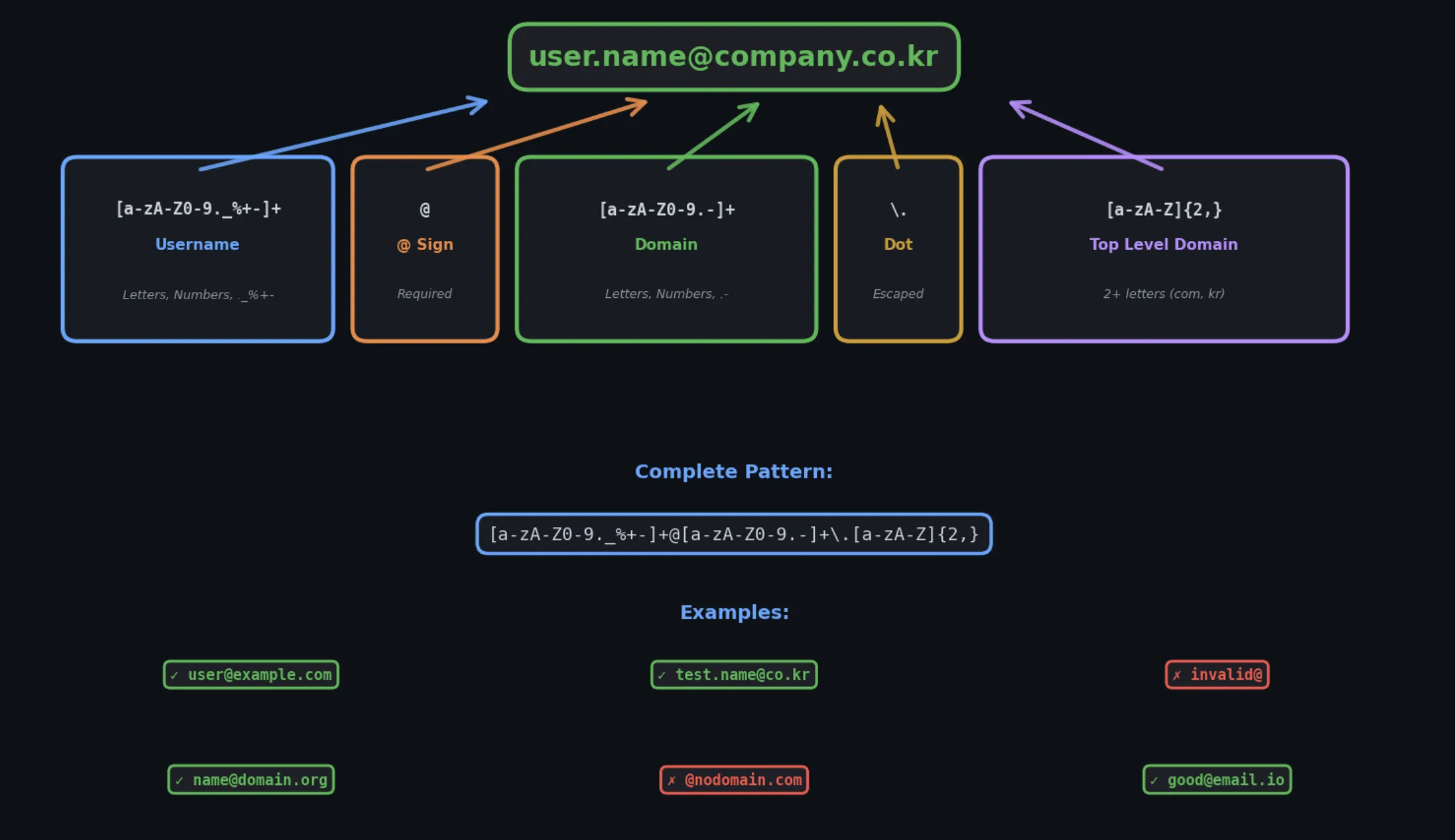
패턴 뜯어보기
pattern = r'[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}'1부분: 사용자명 [a-zA-Z0-9._%+-]+
[...]: 이 안의 문자 중 하나a-zA-Z: 영문 소문자, 대문자0-9: 숫자._%+-: 특수문자 (점, 밑줄, 퍼센트, 플러스, 하이픈)+: 1개 이상 반복
2부분: @ 기호 @
- 그냥 @ 있어야 해요
3부분: 도메인 [a-zA-Z0-9.-]+
- 영문, 숫자, 점, 하이픈 조합
4부분: 최상위 도메인 .[a-zA-Z]{2,}
.: 점 (.는 특수문자라서로 이스케이프)[a-zA-Z]{2,}: 영문 2글자 이상 (com, kr, net 등)
4. 실전 예제 1: 이메일 주소 추출하기
이제 진짜 써볼게요!
import re
# 여러 이메일이 섞인 텍스트
text = """
연락처 정보:
- 대표 이메일: [email protected]
- 고객센터: [email protected]
- 잘못된 형식: notanemail@
- 개인 메일: [email protected]
- 또 잘못된 것: @nodomain.com
"""
# 이메일 패턴
pattern = r'[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}'
# 모든 이메일 찾기
emails = re.findall(pattern, text)
print("찾은 이메일:")
for email in emails:
print(f" {email}")
print(f"
총 {len(emails)}개 이메일 발견!")실행 결과:
찾은 이메일:
[email protected]
[email protected]
[email protected]
총 3개 이메일 발견!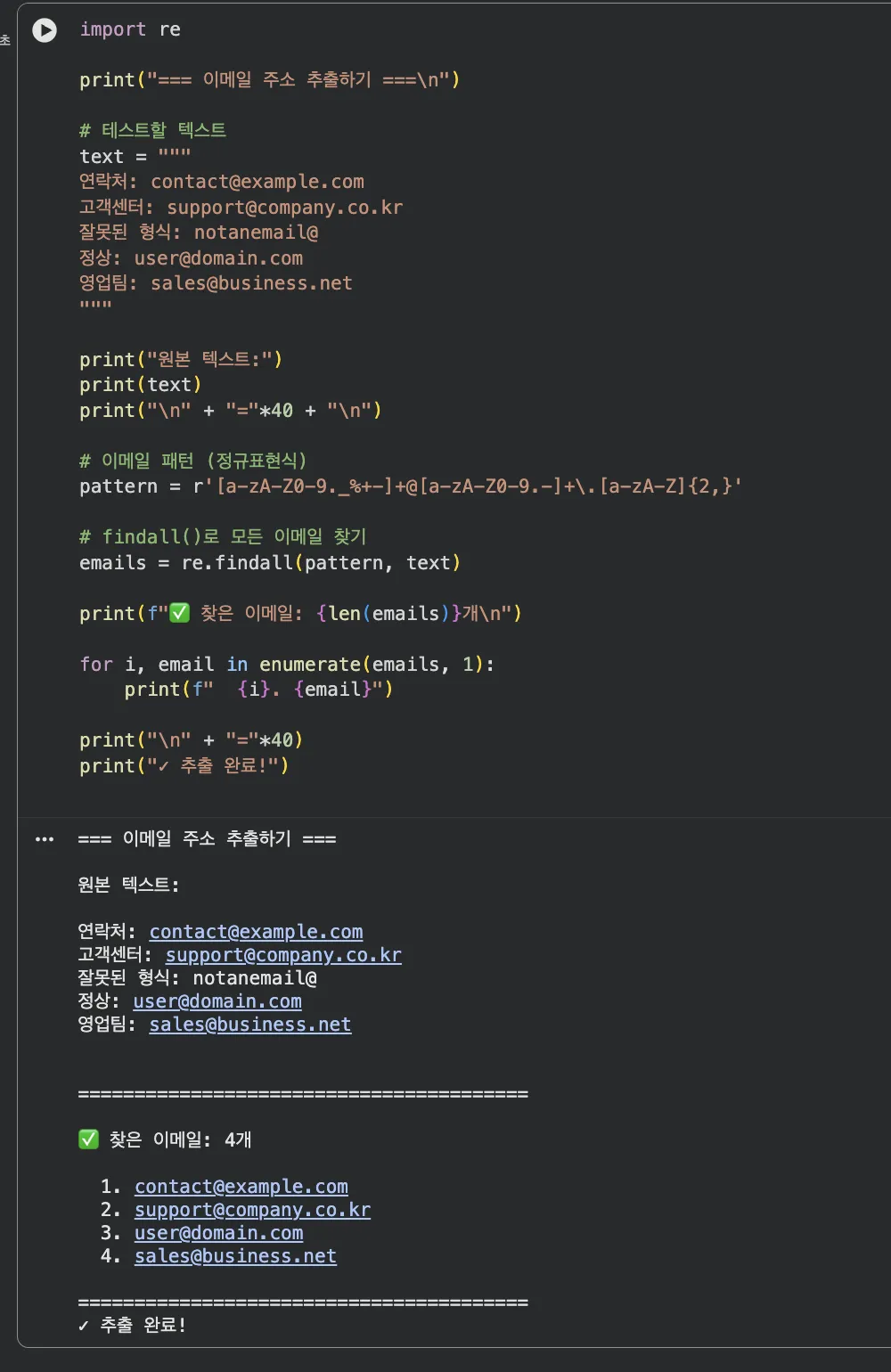
Q. 잘못된 형식은 왜 안 잡혔나요?
notanemail@→ 도메인이 없어서 제외@nodomain.com→ 사용자명이 없어서 제외
패턴이 정확히 "이메일처럼 생긴 것"만 찾아내요!
5. 실전 예제 2: 도메인별로 그룹화하기
회사별로 이메일을 분류하고 싶다면?
import re
from collections import defaultdict
text = """
고객 리스트:
- 홍길동: [email protected]
- 김철수: [email protected]
- 이영희: [email protected]
- 박민수: [email protected]
- 최지훈: [email protected]
- 정수진: [email protected]
- 강태양: [email protected]
"""
# 1단계: 모든 이메일 찾기
pattern = r'[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}'
emails = re.findall(pattern, text)
# 2단계: 도메인별로 그룹화
domain_groups = defaultdict(list)
for email in emails:
domain = email.split('@')[1] # @ 뒤가 도메인
domain_groups[domain].append(email)
# 3단계: 결과 출력
print("도메인별 이메일 그룹")
print("=" * 50)
for domain, email_list in sorted(domain_groups.items()):
print(f"
{domain} ({len(email_list)}개)")
for email in email_list:
print(f" {email}")
print(f"
총 {len(emails)}개 이메일, {len(domain_groups)}개 도메인")실행 결과:
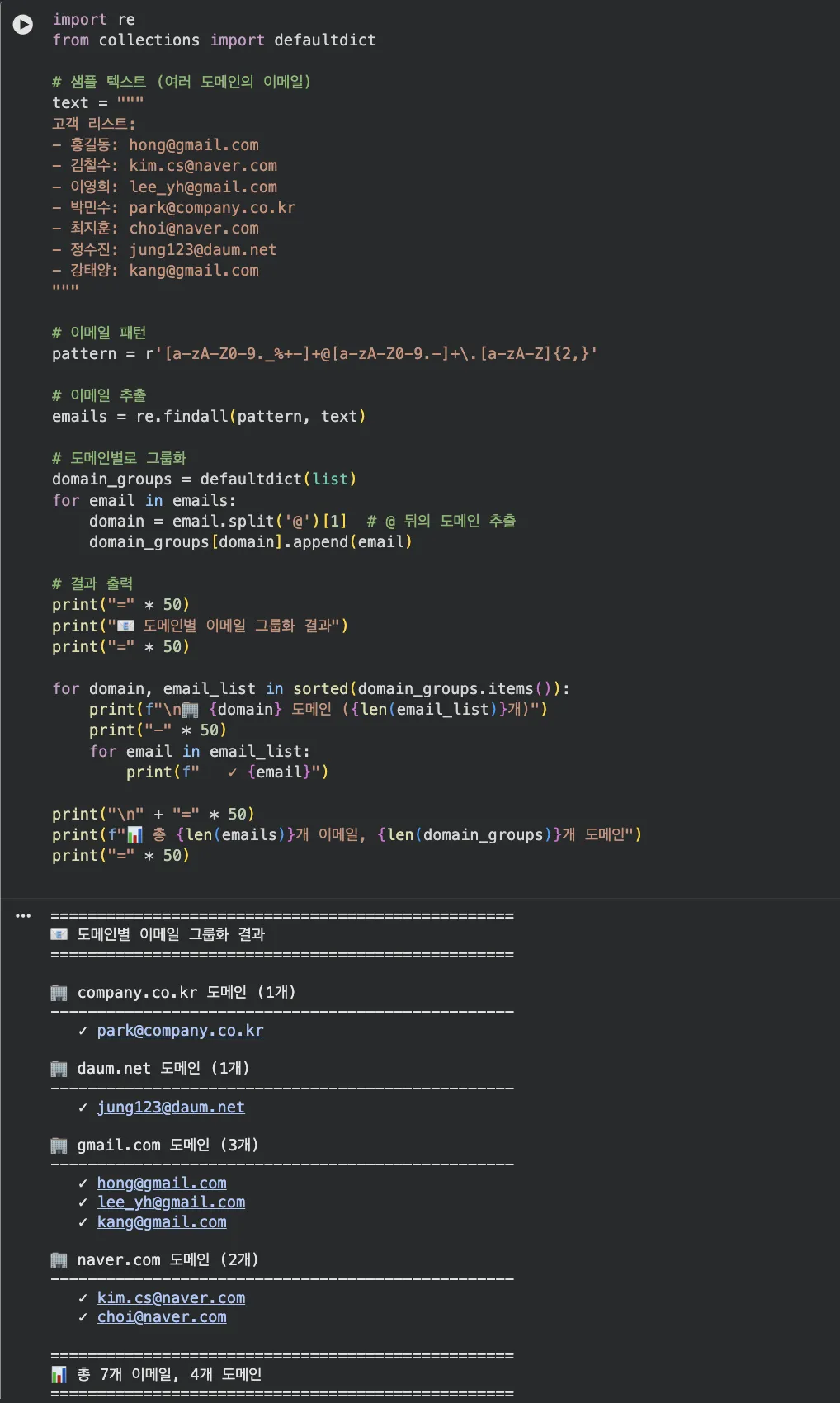
실무에서는?
- 고객 리스트를 회사별로 분류
- Gmail 사용자에게만 따로 메일 발송
- 도메인별 통계 집계 (gmail이 가장 많네요!)
6. 보너스 예제: 전화번호 찾기
이메일을 배웠으니 전화번호도 찾을 수 있어요!
한국 전화번호는 여러 형식이 있죠?
010-1234-5678(하이픈)010.1234.5678(점)010 1234 5678(공백)01012345678(형식 없음)
모든 형식을 한번에 찾는 통합 패턴:
import re
text = """
고객 연락처:
- 김철수: 010-1234-5678 (개인)
- 이영희: 010.9876.5432 (회사)
- 박민수: 02-123-4567 (사무실)
- 최지훈: 031-456-7890 (집)
- 정수진: 01012345678 (형식 없음)
- 강태양: 010 1111 2222 (공백)
"""
# 통합 패턴: 하이픈, 점, 공백 모두 허용
pattern = r'd{2,3}[-.s]?d{3,4}[-.s]?d{4}'
phones = re.findall(pattern, text)
print("찾은 전화번호:")
for phone in phones:
print(f" {phone}")
print(f"
총 {len(phones)}개 전화번호 추출!")실행 결과:

패턴 설명:
d{2,3}: 숫자 2~3개 (지역번호 02, 010, 031 등)[-.s]?: 하이픈, 점, 공백 중 0개 또는 1개 (?는 선택)d{3,4}: 숫자 3~4개 (중간번호)[-.s]?: 또 구분자 (선택)d{4}: 숫자 4개 (마지막번호)
7. 이제 할 수 있어요!
이 글을 읽고 나면 이런 걸 할 수 있어요:
1. 자동 데이터 추출
- 100페이지 PDF에서 이메일 1초 만에 추출
- 명함 사진에서 전화번호 자동 수집
- 계약서에서 URL 주소만 골라내기
2. 입력 검증
- "이메일 형식이 맞나요?" 자동 확인
- 비밀번호 규칙 체크 (영문+숫자+특수문자)
- 전화번호 형식 통일 (모두 010-1234-5678로 변환)
3. 데이터 정제
- 카드번호 마스킹 (1234-****-****-5678)
- 개인정보 비식별화
- 불필요한 공백, 특수문자 제거
정리하며
정규표현식은 처음엔 암호처럼 보이지만, 익숙해지면 엑셀보다 훨씬 강력한 도구가 됩니다.
이 글에서 배운 것:
- 정규표현식 기본 개념
- 패턴으로 찾기 vs 일일이 찾기
- 1시간 작업을 1초로 단축
- re 모듈 3총사
match(): 처음부터 일치하나?search(): 어딘가에 있나?findall(): 전부 찾아줘!
- 실전 패턴 만들기
- 이메일:
[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,} - 전화번호:
d{2,3}[-.s]?d{3,4}[-.s]?d{4}
- 이메일:
- 실무 활용
- 데이터 추출, 입력 검증, 정보 마스킹
다음 시리즈 예고:
지금까지 벡터 수학과 데이터 처리를 배웠어요. 다음에는 이 데이터들을 멋진 그래프로 시각화하는 방법을 알아볼 거예요.
막대 그래프, 꺾은선 그래프, 히트맵까지! Python으로 엑셀보다 더 예쁜 차트 만드는 법, 기대해주세요!
연습 과제:
- 자신의 이메일 받은편지함에서 모든 발신자 주소 추출하기
- 웹페이지 HTML에서 모든 링크(URL) 찾기
- 주민등록번호 패턴 만들기 (단, 실제 번호는 절대 수집하지 마세요!)
정규표현식, 생각보다 어렵지 않죠? 이제 정규표현식을 사용할 수 있어요!