
[벡터DB·지식그래프 RAG 1편] 의미 검색 — 키워드를 넘어서
RAG·GraphRAG의 출발점인 의미 검색을 기초부터 다룹니다. 키워드 검색의 한계 → 임베딩으로 문장을 벡터(좌표)로 → sentence-transformers로 직접 임베딩 → 코사인 의미 검색 → 벡터를 그래프로 보기까지. 레오파드게코 사육 FAQ로 실제 돌려보고, 2D 임베딩 지도·유사도 히트맵·의미 이웃 네트워크로 시각화했습니다. 지식그래프 RAG 5부작의 1편.
이 시리즈가 향하는 곳 — GraphRAG
요즘 AI 챗봇한테 "내 문서 기반으로 답해줘" 하는 거, 그게 RAG(검색 증강 생성)입니다.
그 RAG의 심장이 검색이고, 그 검색의 뿌리가 벡터(임베딩)예요.
그리고 이걸 한 단계 더 끌어올린 게 요즘 화두인 GraphRAG(지식그래프 기반 RAG)입니다.
근데 GraphRAG를 제대로 이해하려면 밑바닥부터 쌓아야 하더라고요.
그래서 이걸 5부작으로 천천히 가보려 합니다. 이번 1편은 그 출발점인 의미 검색이에요.

1편에서 다루는 것: 키워드 검색의 한계 → 임베딩으로 '뜻'을 좌표로 → 문장 임베딩 실습(sentence-transformers) → 의미 검색 → 벡터를 그래프로 보기.
Neo4j·벡터DB 본격 실습은 2편부터입니다. 1편은 개념과 시각화에 집중해요.

임베딩은 의미를 좌표로 — 별처럼 공간에 흩어진 점들이 된다. (사진: Wikimedia Commons, Public Domain)
키워드 검색은 왜 부족한가요?
키워드 검색은 글자가 똑같이 들어간 문서만 찾습니다. 그래서 뜻은 같은데 표현이 다른 문서를 놓칩니다. 예를 들어 "겨울에 히터 켜야 하나요?"로 검색하면 '히터'라는 단어가 든 문서만 걸리고, '추위', '보온', '적정 온도'처럼 같은 의미의 다른 표현은 빠집니다. 의미 검색은 이 문제를 '뜻이 가까운지'로 풀어서, 표현이 달라도 찾아냅니다.
쇼핑몰에서 "노트북" 검색했는데 "랩탑"이라고 적힌 글이 안 나온 경험, 다들 있으시죠?
컴퓨터는 글자만 보거든요. '노트북'과 '랩탑'이 같은 뜻이라는 걸 모릅니다.
제 게코 사육 메모로 예를 들어볼게요. "겨울에 히터 꼭 켜야 하나요?"라고 물었을 때,
키워드 검색은 '히터'가 든 문서 하나만 찾고 "적정 온도 유지", "야간 18도 이하 주의" 같은 핵심 문서를 놓칩니다.
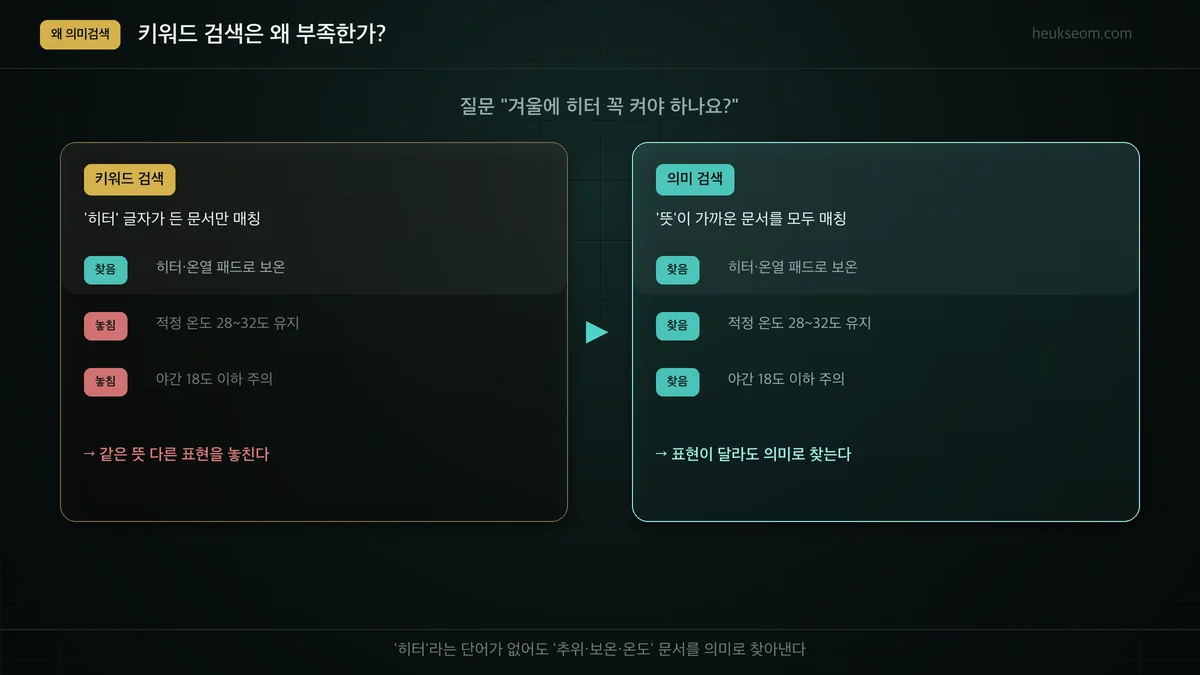
의미 검색은 '히터'라는 단어가 없어도 "추위·보온·온도"에 관한 문서를 다 찾아냅니다.
어떻게 그게 가능할까요? 핵심은 임베딩입니다.
의미를 어떻게 숫자로 바꾸나요?
임베딩은 단어나 문장을 '의미가 담긴 숫자 벡터(좌표)'로 바꾸는 기술입니다. 뜻이 비슷한 문장은 벡터 공간에서 가까운 좌표에, 다른 문장은 먼 좌표에 놓입니다. 그래서 두 문장의 거리(또는 각도)를 재면 '의미가 얼마나 비슷한지'를 숫자로 알 수 있습니다.
단어를 벡터로 바꾸는 건 예전 글에서 다뤘어요. Word2Vec으로 '왕 - 남자 + 여자 = 여왕'까지 해봤었죠.
(딥러닝 기초 1편 — 단어 임베딩에서 복습할 수 있어요.)
이번엔 한 걸음 더 나갑니다. 단어가 아니라 문장 전체를 하나의 벡터로 바꿉니다.
"적정 온도를 유지하세요"와 "따뜻하게 보온해 주세요"는 단어가 거의 안 겹치지만, 뜻이 비슷하니 벡터도 가깝게 나옵니다.
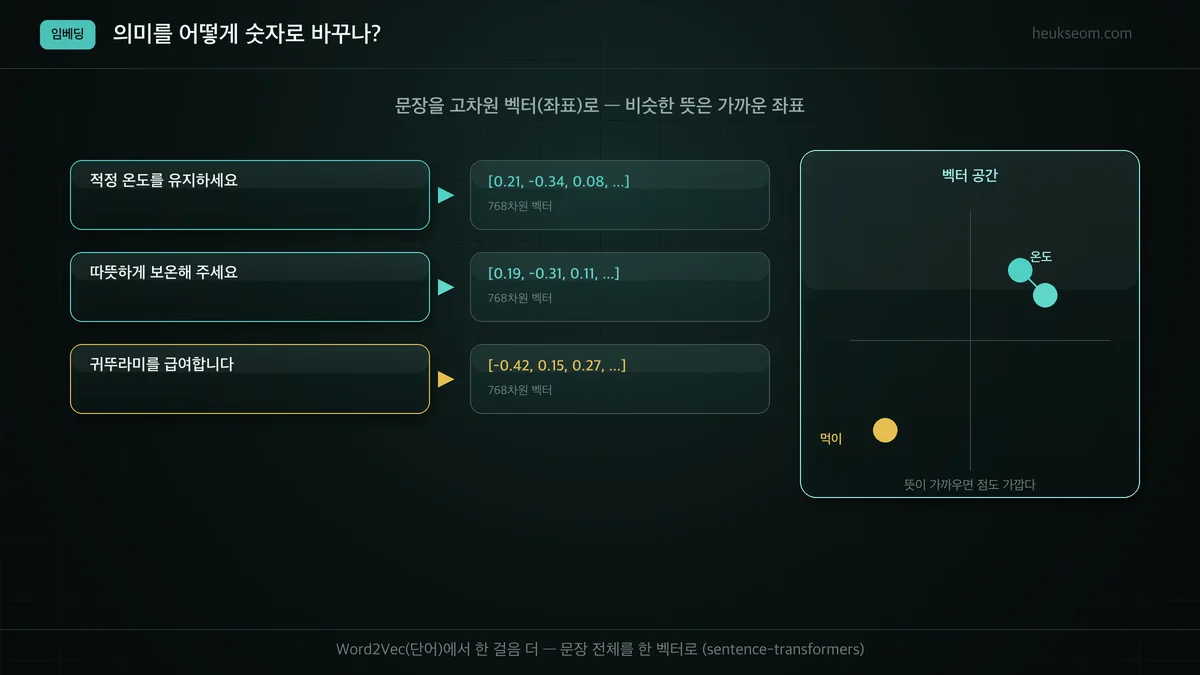
이런 문장 임베딩은 sentence-transformers 라이브러리로 쉽게 만들 수 있습니다.
바로 실습해볼게요.
문장 임베딩, 직접 만들어볼까요?
sentence-transformers로 문장을 벡터로 바꾸는 건 몇 줄이면 됩니다. 모델을 불러오고 encode()에 문장 리스트를 넣으면, 각 문장이 고정 길이 벡터(여기선 768차원)로 나옵니다. 한국어 문서라면 한국어로 학습된 모델을 쓰는 게 품질이 훨씬 좋습니다.
데이터는 제가 직접 적은 레오파드게코 사육 상식 22개를 썼습니다(온도·먹이·탈피·습도·행동 등).
Colab이나 로컬에서 그대로 따라 할 수 있어요.
실습 — 설치 + 문장 임베딩 (셀 1)
!pip install sentence-transformers -q
from sentence_transformers import SentenceTransformer
# 한국어 특화 모델 (KorNLU/KorSTS 학습) — 한국어 의미검색 품질이 좋다
model = SentenceTransformer('jhgan/ko-sroberta-multitask')
texts = [d['text'] for d in docs] # FAQ 문장 22개
emb = model.encode(texts, normalize_embeddings=True)
print('임베딩 shape:', emb.shape)문장 22개가 각각 768개 숫자로 된 벡터가 됐습니다. normalize_embeddings=True로 길이를 1로 맞추면 나중에 코사인 유사도 계산이 깔끔해집니다.
사실 저는 처음에 다국어 모델(paraphrase-multilingual-MiniLM)로 했다가 좀 헤맸어요.
뒤에 나올 "눅눅하다 → 습도" 검색이 엉뚱한 문서를 1등으로 뽑더라고요. 한국어 모델(ko-sroberta)로 바꾸니 바로 정상이 됐습니다. ㅎㅎ
한국어 데이터면 한국어 모델, 이게 은근 중요하더라고요.
벡터 공간은 어떻게 생겼나요?
768차원 벡터는 사람이 볼 수 없으니, t-SNE나 UMAP으로 2차원으로 줄여서 그려봅니다. 그러면 의미가 비슷한 문장들이 서로 가까운 영역에 모이는 걸 눈으로 확인할 수 있습니다. 온도 이야기는 온도끼리, 먹이 이야기는 먹이끼리 뭉치는 경향이 보입니다.
벡터가 768차원이라는데, 그게 도대체 어떻게 생겼는지 감이 안 오시죠?
차원을 2개로 확 줄여서 점으로 찍어보면 느낌이 옵니다. 아래는 실제로 돌린 결과예요.

완벽하게 칼로 자르듯 나뉘진 않지만, 주제별로 가까운 영역에 모이는 경향이 보입니다.
온도(0·1·2)는 우상단에, 먹이(3·4·5)는 좌하단에 몰리는 식이죠. 의미가 좌표로 표현됐다는 증거예요.
평면(2D)으로는 겹쳐 보이는 점들도, 축을 하나 더 줘서 3D(x·y·z축)로 보면 공간감이 확 삽니다.
벡터DB가 실제로 다루는 건 이런 '좌표 공간'이에요. 차원이 768개라 우리가 못 볼 뿐, 원리는 똑같습니다.
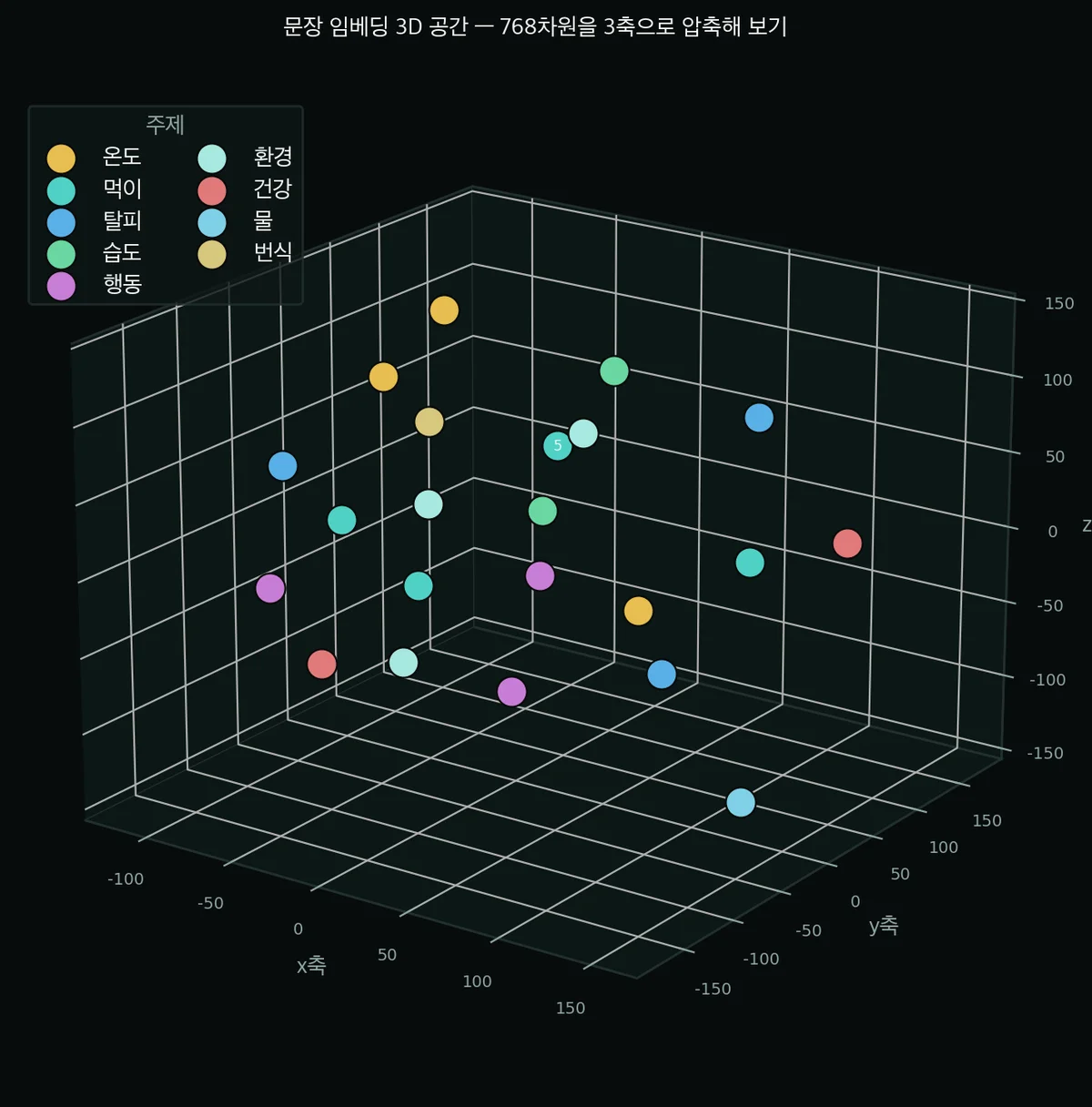
같은 데이터를 3개의 축(x·y·z)으로 펼친 모습입니다. 점 하나가 문장 하나, 색이 주제예요.
벡터DB는 결국 이 공간에 흩어진 점들 중에서 '질문 점과 가장 가까운 점'을 찾아주는 도구입니다.
실습 — 2D / 3D로 줄여서 그리기 (셀 2)
from sklearn.manifold import TSNE
xy = TSNE(n_components=2, perplexity=8, init='pca',
random_state=42).fit_transform(emb)
# xy[i] = i번째 문장의 2D 좌표 → 주제별 색으로 산점도
# 3D로 보려면 n_components=3 (x·y·z축)
xyz = TSNE(n_components=3, perplexity=8, random_state=42).fit_transform(emb)
# ax = fig.add_subplot(projection='3d'); ax.scatter(*xyz.T, c=colors)t-SNE는 고차원 벡터의 '가까움'을 최대한 보존하면서 2D로 줄여줍니다. 데이터가 적으면 결과가 조금씩 흔들리니 random_state로 고정했어요.
유사도로 검색하면 진짜 의미로 찾아지나요?
질문도 같은 모델로 벡터화한 뒤, 모든 문서 벡터와 코사인 유사도를 계산해 점수가 높은 순으로 뽑으면 그게 의미 검색입니다. 코사인 유사도는 두 벡터가 이루는 각도를 보는 값으로, 1에 가까울수록 의미가 비슷합니다. 키워드가 하나도 안 겹쳐도 뜻이 가까우면 상위에 올라옵니다.
이제 핵심입니다. 질문을 똑같이 벡터로 바꾼 다음, 문서 벡터들과 각도를 재서 가까운 순으로 줄 세우면 끝이에요.

실습 — 코사인 의미 검색 (셀 3)
import numpy as np
def search(query, k=3):
qv = model.encode([query], normalize_embeddings=True)[0]
sims = emb @ qv # 정규화돼 있어 내적 = 코사인 유사도
top = np.argsort(-sims)[:k]
for rank, i in enumerate(top, 1):
print(f'{rank}위 [{topics[i]}] {sims[i]:.3f} {texts[i][:32]}...')
search('겨울에 히터를 꼭 켜야 하나요?')
search('밥을 안 먹어요 왜 그럴까요?')
search('케이지가 너무 눅눅한 것 같아요')"눅눅하다"는 '습도'와 글자가 하나도 안 겹치는데 습도 문서를 1등으로 찾아냈죠? 이게 의미 검색의 힘입니다.
보세요. "눅눅하다"엔 '습도'라는 단어가 없는데도 습도 문서를 1등으로 골랐어요.
"밥"이라고 물었는데 '먹이·사료' 문서를 찾은 것도 마찬가지고요. 키워드 검색은 절대 못 하는 일입니다.
문서끼리 서로 얼마나 가까운지 전부 재서 히트맵으로 그려보면 이렇게 나옵니다.
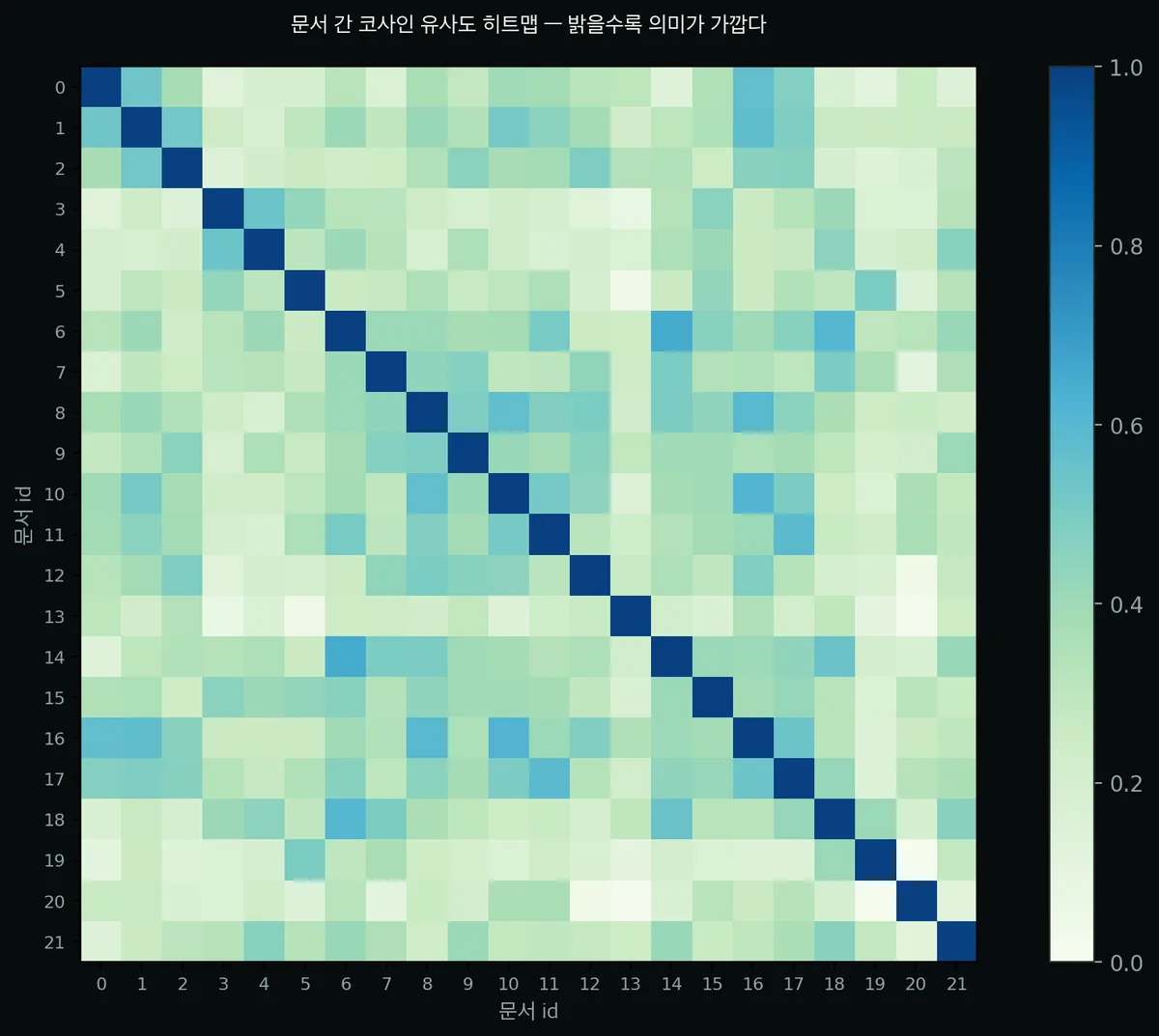
대각선(자기 자신)이 가장 밝고, 가까운 번호(같은 주제)끼리 밝은 블록을 이룹니다.
이 '유사도'라는 숫자가 바로 다음 이야기의 씨앗이에요.
벡터를 그래프로 보면 무엇이 보이나요?
각 문장에서 '의미가 가장 가까운 이웃 몇 개'를 선으로 이으면, 노드(문장)와 엣지(유사 관계)로 이뤄진 그래프가 됩니다. 이 '의미 이웃 그래프'가 바로 지식그래프의 씨앗입니다. 여기에 사람이 정의한 '관계'(예: 원인-결과, 상위-하위)를 더하면 지식그래프가 되고, 그 위에서 도는 검색이 GraphRAG입니다.
유사도를 그냥 표로 두면 밋밋하죠. 각 문장마다 '제일 비슷한 이웃 3개'를 선으로 이어볼게요.
그러면 점과 선으로 된 그래프가 나타납니다.
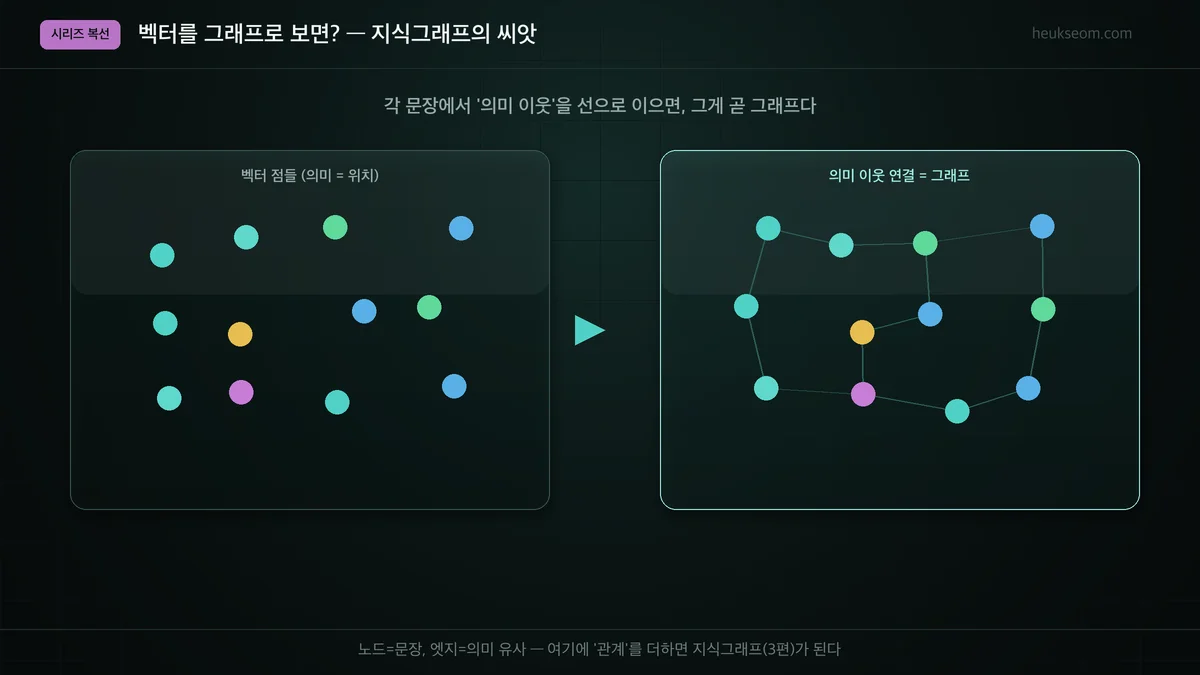
실제 데이터로 만든 의미 이웃 그래프는 이렇게 생겼습니다(노드=문장, 엣지=의미 유사, 색=주제).

실습 — 의미 이웃 그래프 만들기 (셀 4)
import networkx as nx
S = emb @ emb.T # 모든 문서쌍 코사인 유사도
G = nx.Graph()
for i in range(len(texts)):
nbrs = np.argsort(-S[i])[1:4] # 자기 자신 빼고 가까운 이웃 3개
for j in nbrs:
G.add_edge(i, int(j), weight=float(S[i, j]))
# spring_layout으로 그리면 가까운 노드끼리 뭉쳐서 배치된다이게 핵심 복선입니다. 벡터의 '가까움'을 '연결'로 바꾸면 곧 그래프예요. 여기에 의미 있는 관계를 더하는 게 3편 지식그래프, 그 위에서 답을 만드는 게 5편 GraphRAG입니다.
같은 주제 문장끼리 자연스럽게 뭉쳐서 연결되죠?
"벡터의 이웃 = 그래프"라는 이 감각이, 시리즈 내내 따라올 핵심입니다.
그런데 데이터가 많아지면 어떻게 되나요?
지금처럼 질문마다 모든 문서와 일일이 유사도를 계산하면, 문서가 N개일 때 비용이 N에 비례해서 늘어납니다(O(N)). 문서 22개면 순식간이지만, 수백만 개가 되면 질문 한 번에 수백만 번 비교라 너무 느려집니다. 그래서 벡터를 효율적으로 저장하고 근사적으로 빠르게 찾아주는 '벡터DB + ANN 인덱스'가 필요해집니다.
지금 우리 코드는 질문이 들어올 때마다 22개 문서랑 전부 비교했어요. 22개니까 눈 깜짝할 새죠.
근데 문서가 100만 개라면? 질문 한 번에 100만 번 비교입니다. 그것도 매 질문마다요.
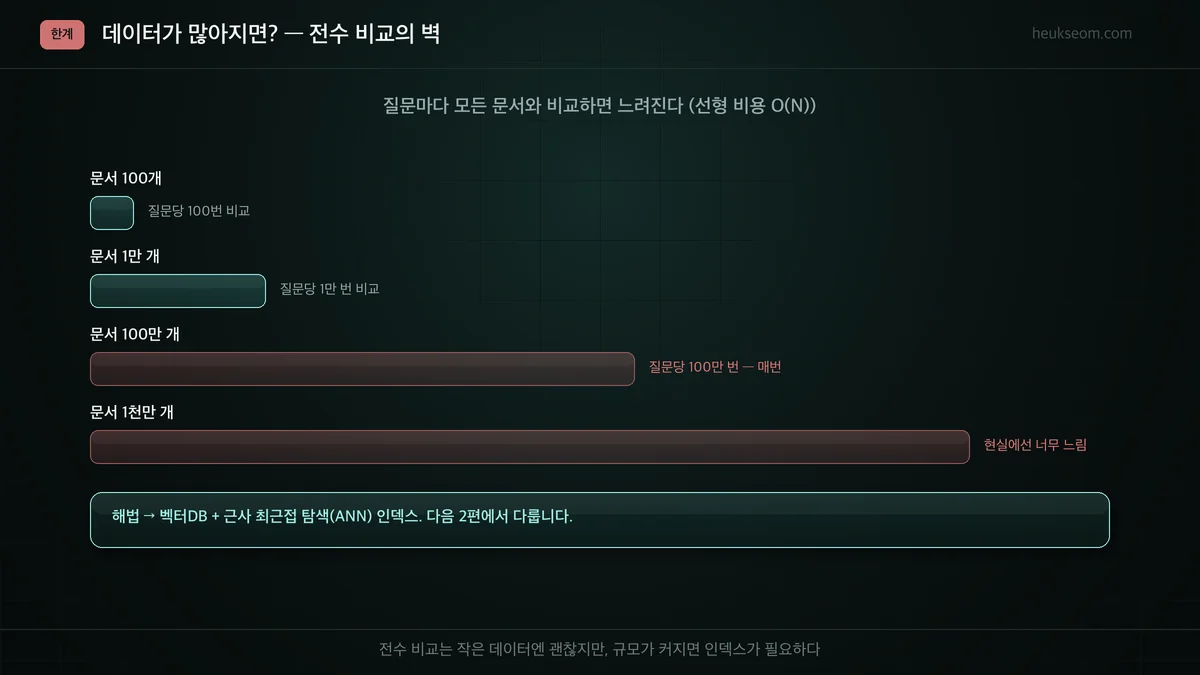
이걸 해결하는 게 벡터DB입니다. 벡터를 미리 인덱싱해두고, 전부 비교하는 대신 '거의 가까운 것들'만 빠르게 추려내는 ANN(근사 최근접 탐색)을 씁니다.
다음 2편에서 벡터DB가 정확히 무엇이고, 우리가 쓸 Neo4j를 docker로 띄워서 직접 의미 검색을 돌려봅니다.
정리
1편에서 다룬 핵심만 짧게 정리해봅니다.
- 키워드 검색은 글자가 같아야 찾습니다. 의미 검색은 '뜻'이 가까우면 찾습니다.
- 임베딩은 문장을 의미가 담긴 벡터(좌표)로 바꿉니다. 비슷한 뜻은 가까운 좌표예요.
- 질문도 벡터로 바꿔 코사인 유사도로 줄 세우면, 키워드가 안 겹쳐도 의미로 검색됩니다.
- 벡터의 '의미 이웃'을 선으로 이으면 그래프가 됩니다 — 지식그래프의 씨앗.
- 데이터가 커지면 전수 비교는 느려집니다(O(N)). 그래서 벡터DB와 ANN 인덱스가 필요합니다.
검색이 RAG의 심장이고, 그 검색의 뿌리가 벡터라는 걸 직접 만져봤습니다.
한국어 데이터엔 한국어 모델을 써야 한다는 것도 삽질하며 배웠고요. ㅋㅋ
다음 2편에서는 이 벡터들을 제대로 보관하고 빠르게 찾는 벡터DB로 넘어갑니다.
Neo4j를 docker로 직접 띄워서, 벡터를 저장하고 의미 검색을 돌려볼 거예요. 여기서부터 진짜 실전입니다.