
[벡터DB·지식그래프 RAG 2편] 벡터DB 도입 — Neo4j에 벡터를 심다
1편의 의미 검색을 진짜 벡터DB로 옮깁니다. 전수 비교의 한계(O(N)) → ANN/HNSW 원리 → 벡터DB 생태계(Chroma·Qdrant·pgvector·Neo4j) → docker로 Neo4j 5.26 기동 → 임베딩을 노드에 저장 → 벡터 인덱스 생성 → queryNodes 의미검색까지. Neo4j Browser와 SHOW VECTOR INDEXES 실제 캡처로 확인했습니다. 지식그래프 RAG 5부작 2편.
1편은 됐는데, 왜 또 DB가 필요할까요?
1편에서 임베딩으로 의미 검색을 만들었습니다. "눅눅하다"로 물어도 '습도' 문서를 찾아냈죠.
근데 그때 코드는 질문이 올 때마다 모든 문서랑 일일이 유사도를 쟀어요. 문서 22개니까 순식간이었고요.
문제는 규모입니다. 문서가 100만 개면 질문 한 번에 100만 번 비교. 그것도 매번요.
이걸 해결하는 게 벡터DB입니다. 이번 2편에서는 Neo4j를 docker로 직접 띄워서, 벡터를 저장하고 인덱스로 빠르게 찾는 데까지 해봅니다.
2편에서 하는 것: 벡터DB가 왜 필요한지(전수 비교의 한계) → 생태계 비교 → ANN/HNSW 원리 → docker로 Neo4j 기동 → 벡터 저장 → 벡터 인덱스 + 의미검색까지. 전부 실제로 돌려서 캡처했습니다.
그 많은 벡터를 어디에 저장하고 빠르게 찾나 — 벡터DB의 몫. (사진: Wikimedia Commons, Public Domain)
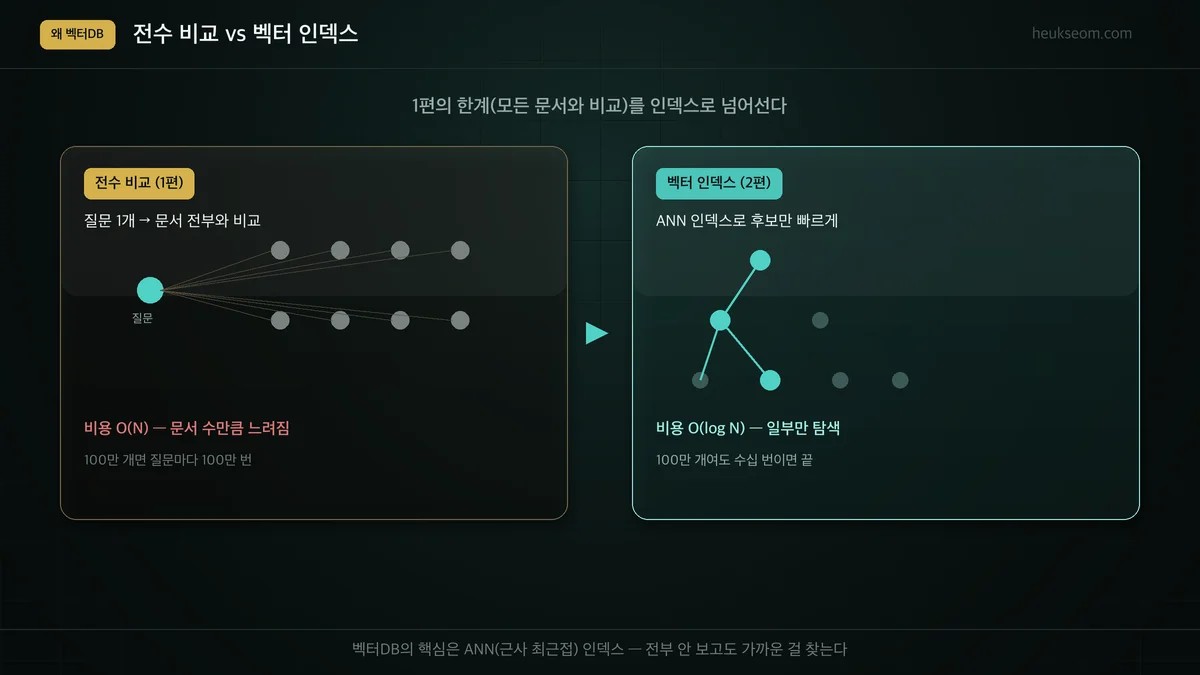
전수 비교는 뭐가 문제인가요?
1편 방식은 질문 하나에 모든 문서를 비교하므로 문서 수 N에 비례해 느려집니다(O(N)). 벡터DB는 미리 만들어 둔 ANN(근사 최근접) 인덱스로 전부 보지 않고도 가까운 후보만 빠르게 찾아, 문서가 수백만 개여도 한 질문을 수십 번의 비교로 끝냅니다(대략 O(log N)).
검색 한 번에 전부 비교하느냐, 일부만 보느냐 — 이 차이가 규모가 커질수록 결정적입니다.
핵심은 ANN(Approximate Nearest Neighbor)입니다. '정확히 가장 가까운'이 아니라 '거의 가까운'을 빠르게 찾는 거예요.
약간의 정확도를 내주고 속도를 크게 얻는 거래죠. 검색엔 보통 이 거래가 훨씬 이득입니다.
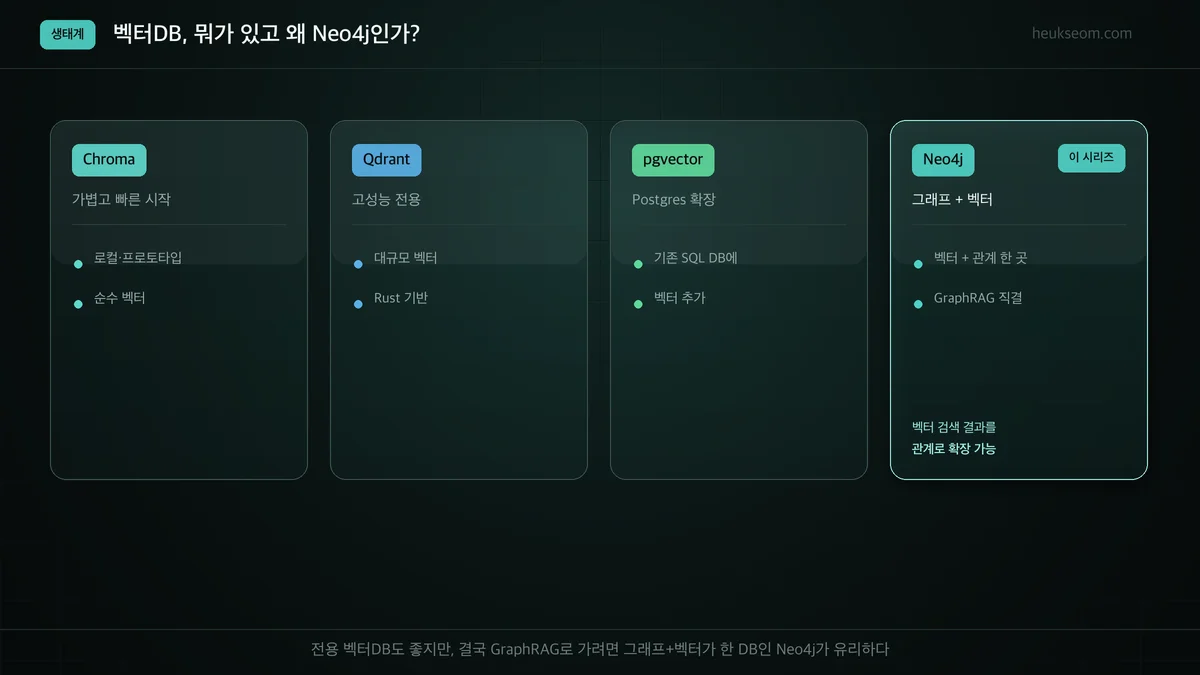
벡터DB는 뭐가 있고, 왜 Neo4j인가요?
벡터DB는 Chroma(가벼운 시작), Qdrant(고성능 전용), pgvector(Postgres 확장), Neo4j(그래프+벡터) 등이 있습니다. 순수 의미검색만 필요하면 전용 벡터DB가 편하지만, 이 시리즈의 목표인 GraphRAG로 가려면 벡터와 '관계'를 한 DB에서 다루는 Neo4j가 유리합니다.
벡터DB는 종류가 꽤 많아요. 각자 장점이 다릅니다.
우리가 Neo4j를 고른 이유는 단순해요. 벡터 검색 결과를 '관계'로 더 확장할 수 있거든요.
예를 들어 "이 문서와 비슷한 문서"를 찾은 다음, "그 문서가 참조하는 다른 문서"까지 그래프로 따라갈 수 있습니다. 이게 3편부터 진짜 힘을 발휘합니다.
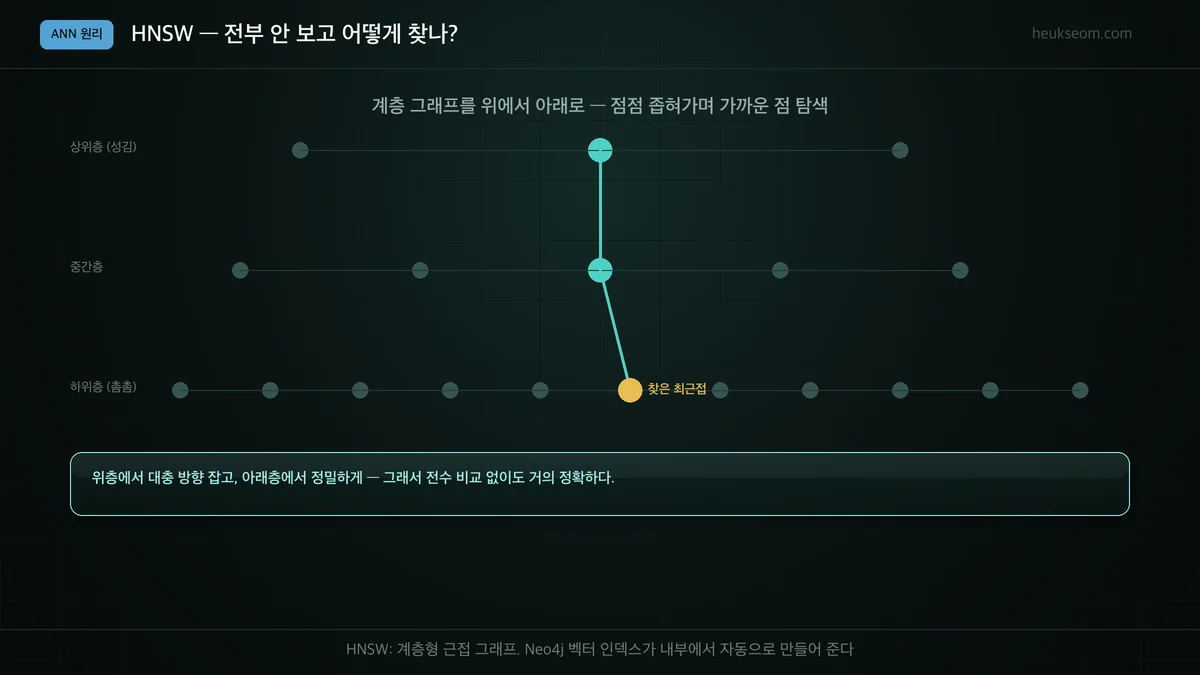
전부 안 보고 어떻게 빨리 찾나요? (HNSW)
대표적인 ANN 알고리즘이 HNSW(계층형 근접 그래프)입니다. 위쪽 성긴 층에서 대략적인 방향을 빠르게 잡고, 아래로 내려가며 점점 촘촘한 층에서 정밀하게 좁혀 가까운 점을 찾습니다. 덕분에 전수 비교 없이도 거의 정확한 결과를 매우 빠르게 얻습니다. Neo4j 벡터 인덱스가 이 HNSW를 내부에서 자동으로 만들어 줍니다.
ANN이 '어떻게' 빠른지 궁금하시죠? 가장 많이 쓰이는 HNSW로 감을 잡아볼게요.
지도 볼 때 전국 지도로 도시 찾고, 그 다음 시내 지도로 동네 찾고, 골목 지도로 집 찾는 거랑 비슷해요.
다행히 우리가 HNSW를 직접 구현할 필요는 없습니다. Neo4j가 알아서 해주거든요. 우리는 인덱스만 만들면 됩니다.
Neo4j, docker로 어떻게 띄우나요?
Neo4j는 docker run 한 줄이면 띄울 수 있습니다. 포트 7474(웹 브라우저 UI)와 7687(Bolt, 파이썬 드라이버 연결)을 열고 비밀번호만 정하면 됩니다. 5.11 버전부터 벡터 인덱스가 코어 기능이라, 추가 플러그인 없이 바로 벡터를 다룰 수 있습니다.
설치 안 하고 컨테이너로 갑니다. docker만 깔려 있으면 5분이면 끝나요.
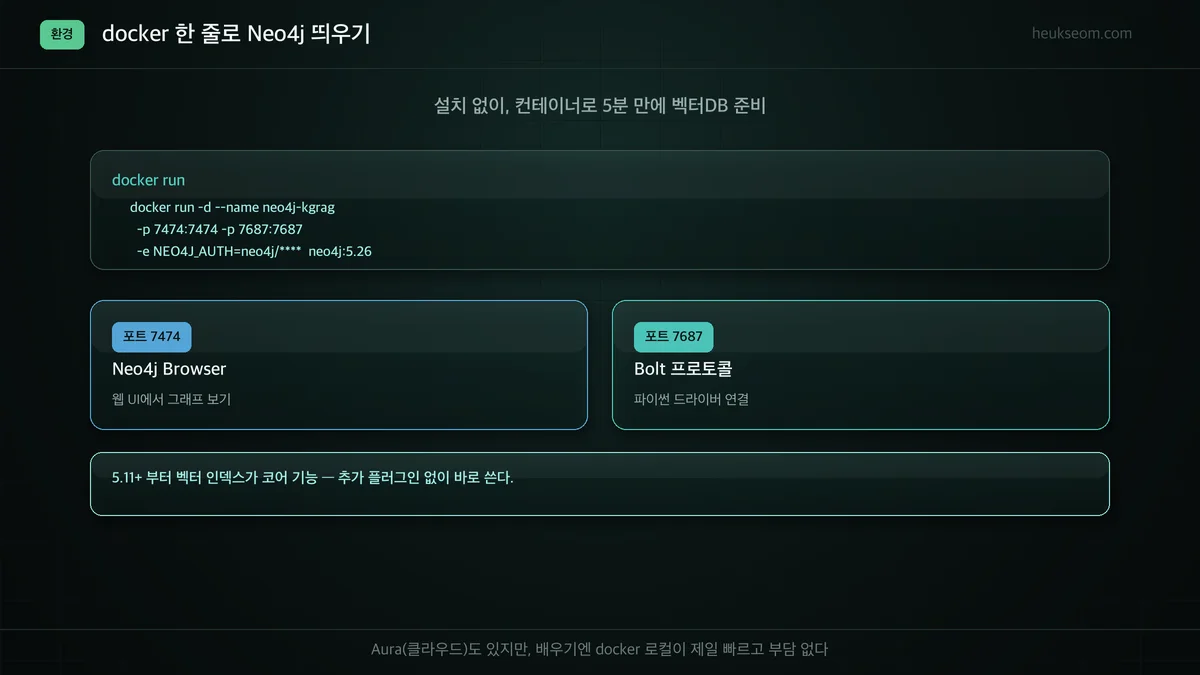
실습 — docker로 Neo4j 띄우기 (셀 1)
# 터미널에서 (docker 필요)
docker run -d --name neo4j-kgrag \
-p 7474:7474 -p 7687:7687 \
-e NEO4J_AUTH=neo4j/your-password \
neo4j:5.26
# 7474 = 웹 브라우저 UI, 7687 = 파이썬 드라이버용 Bolt
# 비밀번호는 8자 이상이어야 한다 (안 그러면 컨테이너가 조용히 죽음)잠깐 기다리면 http://localhost:7474 에서 Neo4j Browser가 열립니다. 처음에 비밀번호를 너무 짧게 줬더니 컨테이너가 바로 꺼지길래 로그 보고서야 알았어요. 8자 이상으로 주세요. ㅎㅎ
컨테이너가 잘 떴는지 docker ps로 확인해봤습니다. 포트 두 개(7474·7687)가 열려 있으면 준비 끝이에요.
벡터를 Neo4j에 어떻게 저장하나요?
각 문서를 노드(:Doc)로 만들고, 임베딩 벡터는 db.create.setNodeVectorProperty로 노드 속성에 저장합니다. 파이썬에서는 neo4j 드라이버로 Bolt(7687)에 연결해 Cypher를 실행하면 됩니다. 이렇게 하면 텍스트·주제 같은 일반 속성과 768차원 벡터가 한 노드에 함께 담깁니다.
1편에서 만든 게코 FAQ 22개를 그대로 씁니다. 임베딩해서 노드로 넣어볼게요.
실습 — Neo4j에 노드 + 벡터 저장 (셀 2)
from neo4j import GraphDatabase
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('jhgan/ko-sroberta-multitask')
driver = GraphDatabase.driver("bolt://localhost:7687",
auth=("neo4j", "your-password"))
with driver.session() as s:
s.run("MATCH (d:Doc) DETACH DELETE d") # 초기화
for d in docs:
vec = model.encode(d['text'], normalize_embeddings=True).tolist()
s.run("""
CREATE (n:Doc {id:$id, text:$text, topic:$topic})
WITH n CALL db.create.setNodeVectorProperty(n, 'embedding', $vec)
""", id=d['id'], text=d['text'], topic=d['topic'], vec=vec)setNodeVectorProperty는 벡터를 일반 리스트보다 공간 효율적으로 저장하는 Neo4j 코어 함수입니다. 그냥 SET n.embedding = $vec 로도 되지만, 벡터 전용 함수를 쓰는 게 권장이에요.
진짜 들어갔는지 Neo4j Browser(localhost:7474)에서 MATCH (d:Doc) RETURN d로 확인해봤습니다.
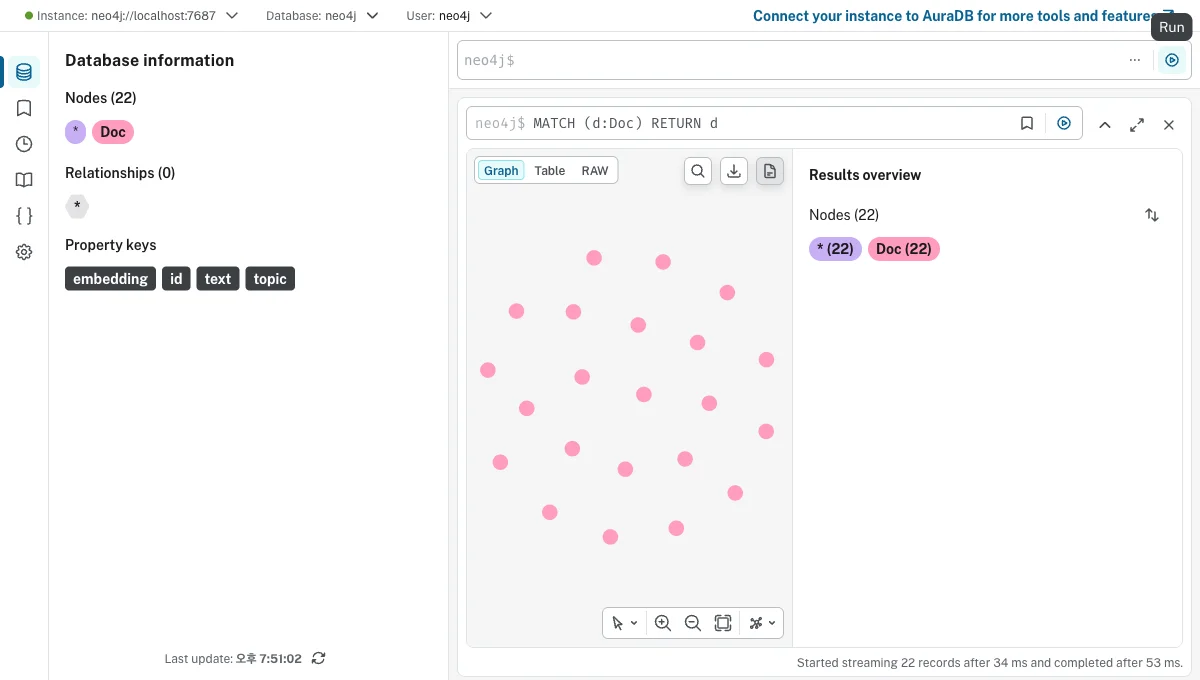
노드 22개가 들어갔고(분홍 점들), 왼쪽 Property keys에 embedding이 보이죠?
텍스트·주제·id에 더해 벡터까지 한 노드에 같이 저장된 겁니다. 아직 노드끼리 관계(선)는 없습니다 — 그건 3편에서 잇습니다.
표(Table) 뷰로 보면 저장된 내용이 더 확실합니다. d.embedding[0..4]로 벡터 앞부분만 꺼내봤어요.
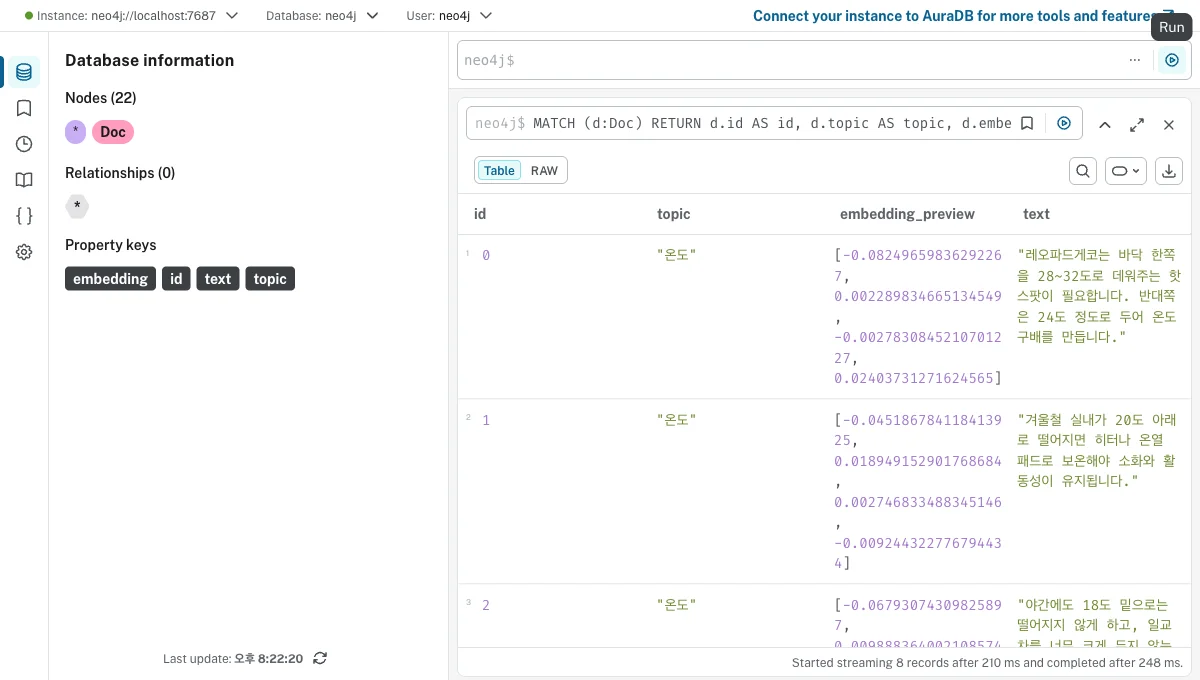
embedding_preview 칸에 실제 벡터 값([-0.082, 0.0022, ...])이 보이죠? 768개 숫자 중 앞 5개만 꺼낸 거예요.
텍스트·주제와 함께 벡터가 같은 노드에 들어가 있는 게 한눈에 보입니다. 이게 '벡터DB'의 실체예요.
벡터 인덱스로 의미검색, 진짜 되나요?
CREATE VECTOR INDEX로 차원(768)과 거리 함수(cosine)를 지정해 인덱스를 만들면, Neo4j가 내부적으로 HNSW 인덱스를 구성합니다. 그 다음 db.index.vector.queryNodes에 질문 벡터를 넣으면 가까운 노드를 점수와 함께 빠르게 돌려줍니다. 1편의 numpy 전수 비교가 이제 DB 인덱스 위에서 돕니다.

실습 — 벡터 인덱스 생성 (셀 3)
with driver.session() as s:
s.run("""
CREATE VECTOR INDEX doc_embedding IF NOT EXISTS
FOR (d:Doc) ON d.embedding
OPTIONS { indexConfig: {
`vector.dimensions`: 768,
`vector.similarity_function`: 'cosine'
}}
""")
s.run("CALL db.awaitIndexes(30)") # 인덱스 준비 대기차원(768)은 임베딩 모델 출력과 똑같아야 합니다. 거리 함수는 정규화된 임베딩엔 cosine이 자연스러워요.
만든 인덱스를 SHOW VECTOR INDEXES로 확인하면, Neo4j가 HNSW로 구성한 게 보입니다.
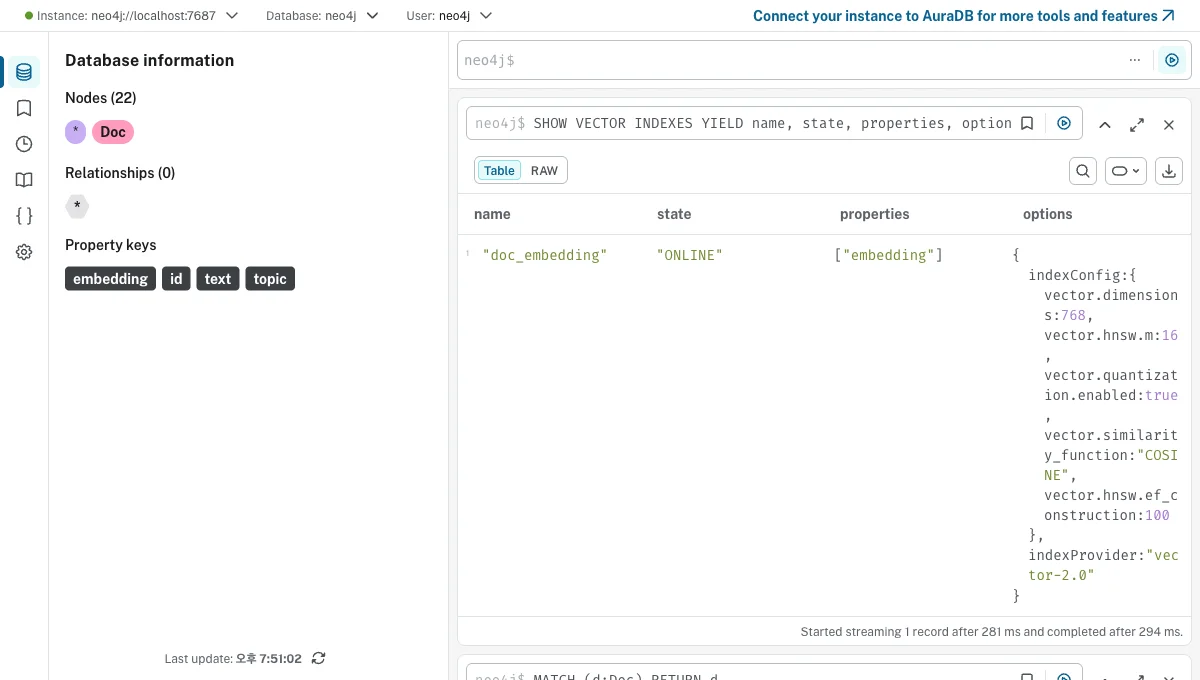
options를 보면 vector.dimensions: 768, similarity_function: COSINE, 그리고 vector.hnsw.m, ef_construction 같은 HNSW 파라미터가 자동으로 설정돼 있어요. 우리가 신경 안 써도 ANN 인덱스가 만들어진 겁니다.
실습 — 벡터 인덱스로 의미검색 (셀 4)
def search(question, k=3):
qv = model.encode(question, normalize_embeddings=True).tolist()
with driver.session() as s:
return s.run("""
CALL db.index.vector.queryNodes('doc_embedding', $k, $qv)
YIELD node, score
RETURN node.topic AS topic, node.text AS text, score
ORDER BY score DESC
""", k=k, qv=qv).data()
for q in ['겨울에 히터를 꼭 켜야 하나요?', '케이지가 너무 눅눅한 것 같아요']:
print('질문:', q)
for r in search(q):
print(f" [{r['topic']}] {r['score']:.3f} {r['text'][:30]}...")1편 numpy 검색과 똑같이 잘 찾습니다. 재밌는 건 점수예요. 1편에선 0.64였는데 여기선 0.82로 나오죠? Neo4j 코사인 점수는 0~1 범위로 다시 스케일해서 그렇습니다. 랭킹(순서)은 똑같으니 걱정 안 해도 돼요.
됐습니다. 이제 22개든 100만 개든, 같은 queryNodes 한 줄로 의미검색이 끝납니다.
1편의 numpy 루프가 진짜 데이터베이스 인덱스 위로 올라온 거예요.
정리
2편에서 다룬 핵심만 정리합니다.
- 전수 비교는 O(N)이라 규모가 커지면 느려집니다. 벡터DB는 ANN 인덱스로 일부만 보고 빠르게 찾습니다.
- 벡터DB는 여러 종류가 있지만, GraphRAG로 가려면 그래프+벡터가 한 DB인 Neo4j가 유리합니다.
- HNSW는 계층 그래프를 위에서 아래로 좁혀가며 탐색합니다. Neo4j가 자동으로 만들어 줍니다.
- docker run 한 줄로 Neo4j를 띄우고, setNodeVectorProperty로 벡터를 노드에 저장했습니다.
- CREATE VECTOR INDEX + queryNodes로, DB 위에서 도는 진짜 의미검색을 완성했습니다.

그런데 지금 우리 그래프엔 점(노드)만 있고 선(관계)이 없어요. 사실상 '벡터 창고'로만 쓴 거죠.
Neo4j의 진짜 힘은 노드를 관계로 잇는 데 있습니다.
다음 3편에서는 이 문서 노드들 사이에 의미 있는 관계를 연결해서 지식그래프를 만듭니다.
벡터로 '비슷한 것'을 찾고, 그래프로 '연결된 것'을 따라가는 — GraphRAG의 두 축이 거기서 만납니다.