
[벡터DB·지식그래프 RAG 3편] Neo4j 지식그래프 — 노드를 관계로 잇다
벡터 창고였던 Neo4j를 진짜 지식그래프로 만듭니다. ABOUT(문서→주제) 구조 관계와 SIMILAR_TO(의미 유사) 관계를 잇고 — 유사도는 vector.similarity.cosine으로 DB 안에서 자동 계산 — Cypher 패턴 매칭으로 구조 질의·의미 이웃·멀티홉을 탐색합니다. '비슷하지만 다른 주제' 같은 조건 결합 질의로 벡터검색의 한계를 넘습니다. Neo4j Browser의 관계 그래프 실캡처 포함. 지식그래프 RAG 5부작 3편.
지금까지는 사실 '벡터 창고'였어요
2편에서 Neo4j에 문서 22개를 벡터로 넣고 의미검색까지 했습니다. 잘 됐죠.
근데 그때 그래프를 보면 점(노드)만 둥둥 떠 있고 선(관계)이 하나도 없었어요. Neo4j를 그냥 벡터 저장소로만 쓴 거예요.
Neo4j의 진짜 힘은 노드를 관계로 잇는 데 있습니다.
이번 3편에서는 문서 노드들 사이에 의미 있는 관계를 연결해서 지식그래프를 만들고, Cypher로 그래프를 탐색해봅니다.
3편에서 하는 것: 왜 관계가 필요한가 → 그래프 모델(ABOUT·SIMILAR_TO) → 관계 만들기 실습 → Cypher 패턴 매칭 → 멀티홉(벡터×그래프)까지. 2편에서 쓰던 Neo4j 컨테이너를 그대로 이어서 씁니다.

노드를 관계로 잇는 지식그래프 — 거미줄 같은 관계망. (사진: Wikimedia Commons, Public Domain)
벡터만으론 뭐가 부족한가요?
벡터 검색은 '무엇과 비슷한가'는 잘 답하지만, '무엇과 어떻게 연결됐는가'는 모릅니다. 점들이 얼마나 가까운지는 알아도, 그 점들 사이의 관계(같은 주제다, 원인-결과다 등)는 담지 못합니다. 노드에 관계를 더하면, 단순 유사 검색을 넘어 연결을 따라가는 추론이 가능해집니다.
벡터 공간에선 "이 문서와 비슷한 문서"까지는 쉽게 찾습니다.
근데 "이 문서와 비슷한 것 중에서, 주제는 다른 것만" 같은 조건은 벡터만으론 엮기 어려워요. 관계 정보가 없으니까요.

점들 사이에 선을 그어 '관계'를 명시하면, 그 선을 따라 이동하며 질문할 수 있게 됩니다.
이게 지식그래프이고, GraphRAG의 토대예요.
문서를 어떤 관계로 이으면 좋을까요?
두 종류의 관계로 엮습니다. ABOUT은 문서가 어떤 주제에 속하는지를 나타내는 구조적 관계이고(예: 문서→온도), SIMILAR_TO는 의미가 가까운 문서끼리 잇는 관계입니다. SIMILAR_TO는 1편의 벡터 유사도를 그대로 관계로 만든 것으로, 사람이 일일이 잇지 않아도 자동으로 생성됩니다.
관계 설계가 지식그래프의 핵심입니다. 우리 게코 FAQ엔 두 가지가 자연스러워요.
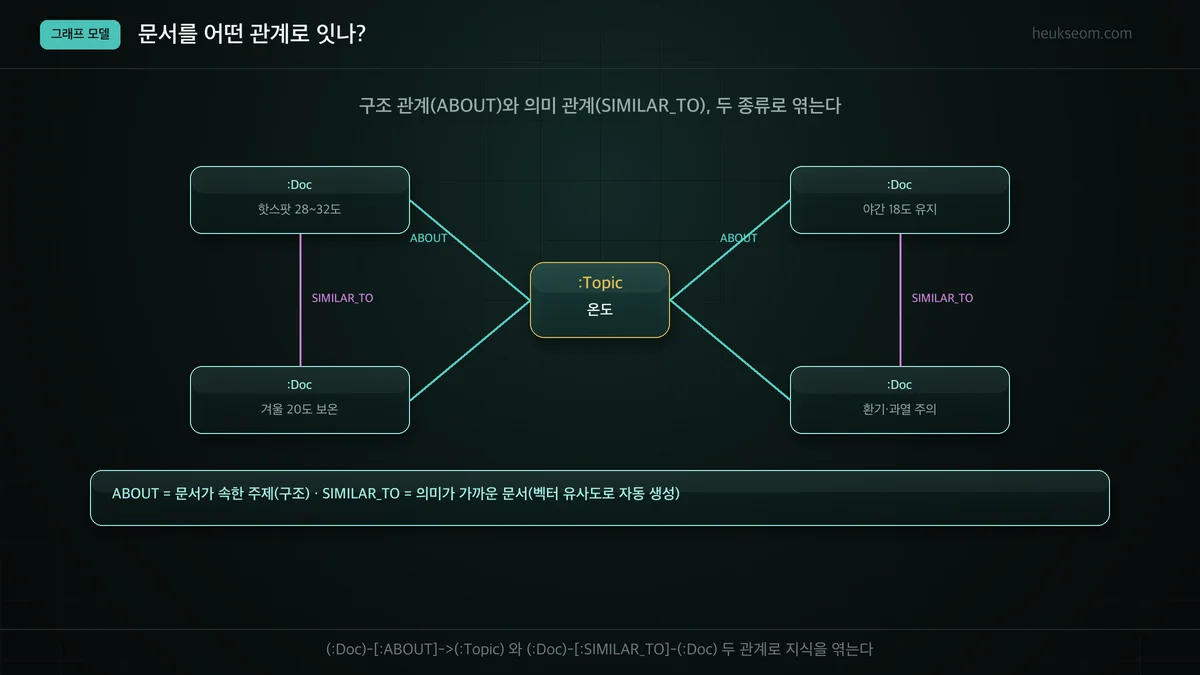
ABOUT은 우리가 정한 구조예요. 각 문서가 어떤 주제(온도·먹이·탈피…)에 속하는지 잇습니다.
SIMILAR_TO는 1편에서 본 '의미 이웃'을 관계로 박은 거예요. 재밌는 건, 이 유사도 계산을 Neo4j 안에서 할 수 있다는 점입니다.
관계, 어떻게 만드나요?
ABOUT 관계는 문서의 topic 속성을 보고 Topic 노드에 MERGE로 잇습니다. SIMILAR_TO 관계는 Neo4j의 vector.similarity.cosine 함수로 모든 문서쌍의 코사인 유사도를 DB 안에서 계산해, 임계값을 넘는 쌍만 자동으로 연결합니다. 임베딩을 밖으로 꺼내지 않고 DB가 직접 유사도를 재는 게 포인트입니다.
실습 — Topic 노드 + ABOUT 관계 (셀 1)
# 각 Doc의 topic으로 Topic 노드를 만들고 ABOUT으로 잇기
s.run("""
MATCH (d:Doc)
MERGE (t:Topic {name: d.topic})
MERGE (d)-[:ABOUT]->(t)
""")MERGE는 "있으면 재사용, 없으면 생성"이라 중복 없이 안전합니다. 같은 주제의 문서들이 한 Topic 노드로 모여요.
실습 — SIMILAR_TO 관계 (DB 안에서 유사도 계산, 셀 2)
# vector.similarity.cosine 으로 모든 문서쌍 유사도를 Neo4j가 직접 계산
s.run("""
MATCH (a:Doc), (b:Doc) WHERE a.id < b.id
WITH a, b, vector.similarity.cosine(a.embedding, b.embedding) AS score
WHERE score > 0.55
MERGE (a)-[r:SIMILAR_TO]->(b) SET r.score = score
""")a.id < b.id로 같은 쌍을 한 번만 잇고, 0.55 넘는 유사한 쌍만 연결합니다. 임계값을 낮추면 선이 빽빽해지고, 높이면 강한 관계만 남아요.
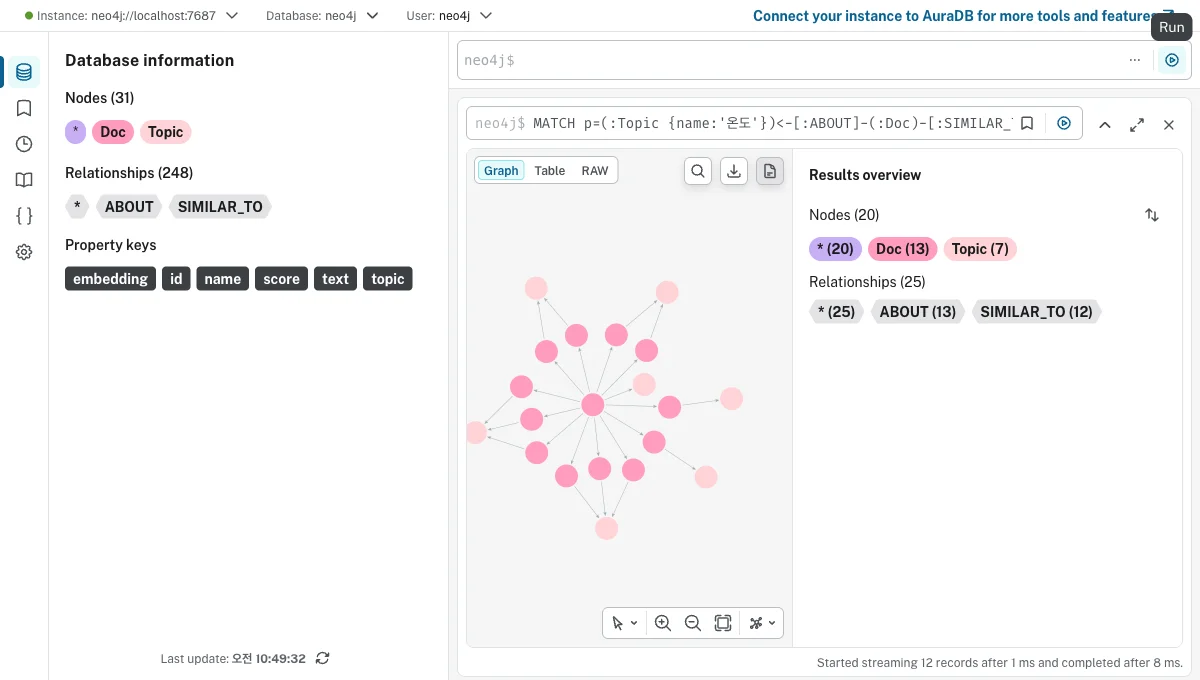
진짜 관계가 생겼는지 Neo4j Browser에서 MATCH (d:Doc)-[r:ABOUT]->(t:Topic) RETURN d, r, t로 봤습니다.
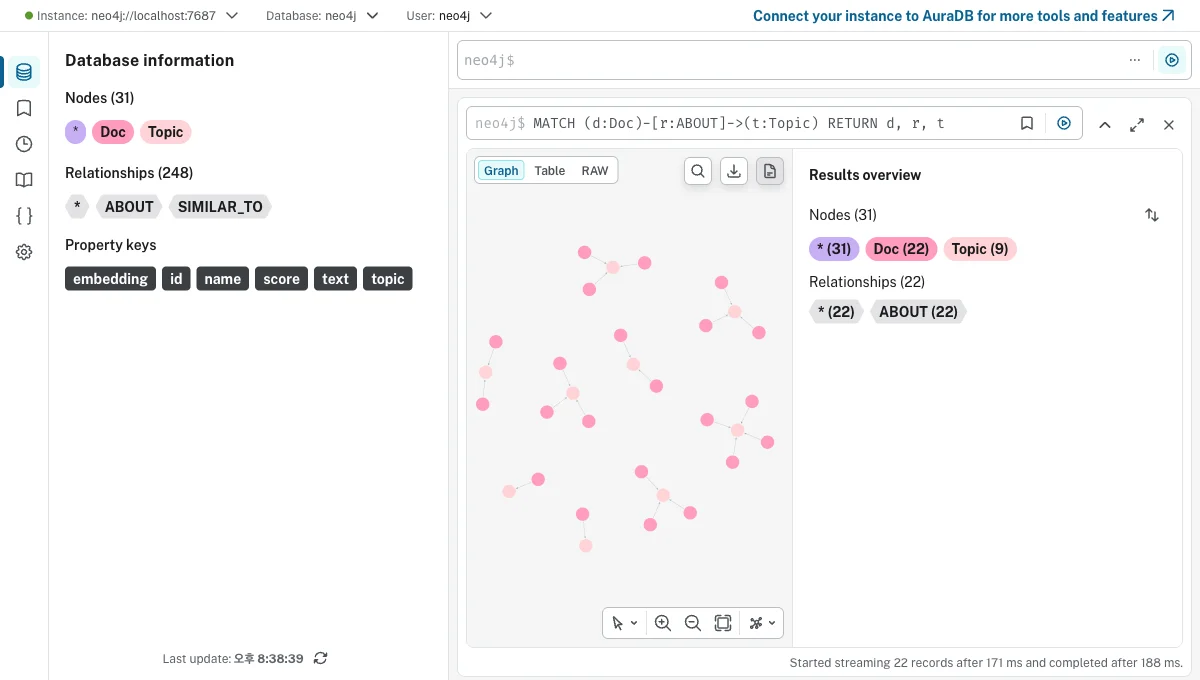
주제 노드(Topic) 9개를 중심으로 문서들이 모인 구조가 보이죠? 드디어 선이 생겼어요.
여기서 한 가지 삽질담. 처음엔 RETURN d, t로만 했더니 점만 뜨고 선이 안 보이더라고요. 알고 보니 RETURN에 관계 변수 r도 넣어줘야 Browser가 선을 그려줍니다. ㅎㅎ
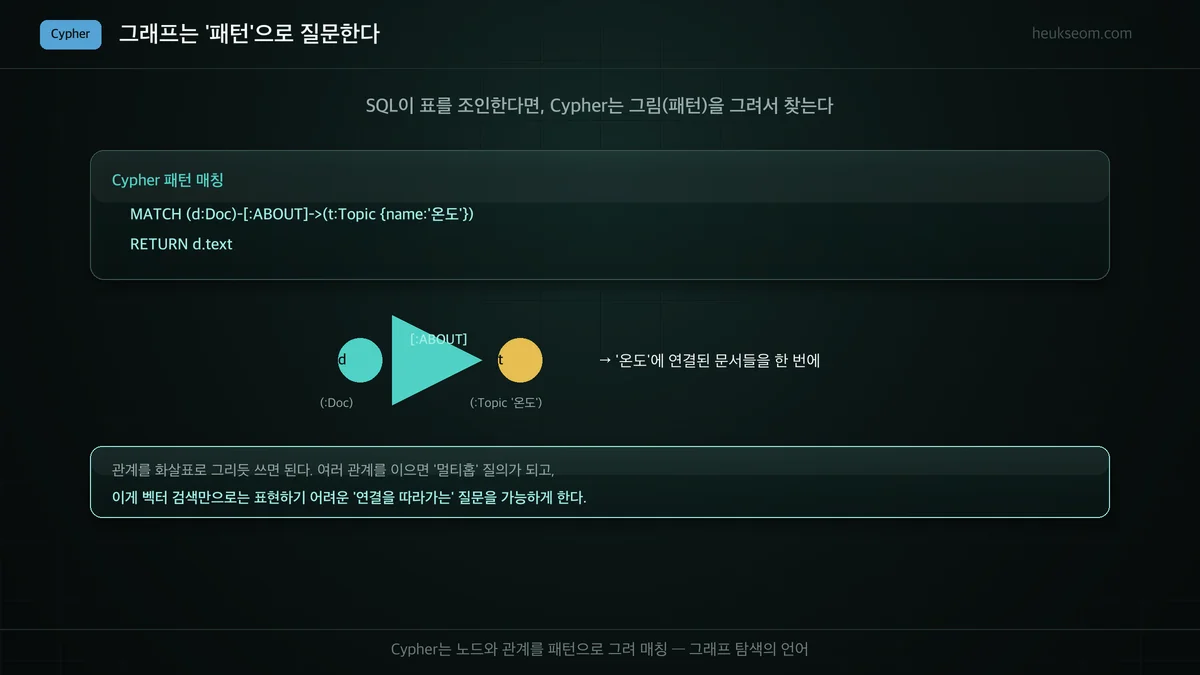
그래프는 어떻게 질문하나요? (Cypher)
Cypher는 노드와 관계를 그림(패턴)으로 그려서 질의하는 언어입니다. (d:Doc)-[:ABOUT]->(t:Topic) 처럼 화살표로 관계를 표현하면, 그 패턴에 맞는 데이터를 찾아줍니다. SQL이 표를 조인한다면 Cypher는 관계를 따라가며 매칭합니다.
실습 — Cypher 그래프 탐색 (셀 3)
# A) 구조 질의 — '온도' 주제 문서
s.run("""
MATCH (d:Doc)-[:ABOUT]->(:Topic {name:'온도'})
RETURN d.id, d.text ORDER BY d.id
""")
# B) 의미 유사 이웃 — 0번 문서와 비슷한 문서
s.run("""
MATCH (d:Doc {id:0})-[r:SIMILAR_TO]-(m:Doc)
RETURN m.id, m.topic, r.score, m.text
ORDER BY r.score DESC LIMIT 4
""")A는 '온도'에 ABOUT으로 연결된 문서를 정확히, B는 SIMILAR_TO 관계를 따라 의미 이웃을 score 순으로 가져옵니다.
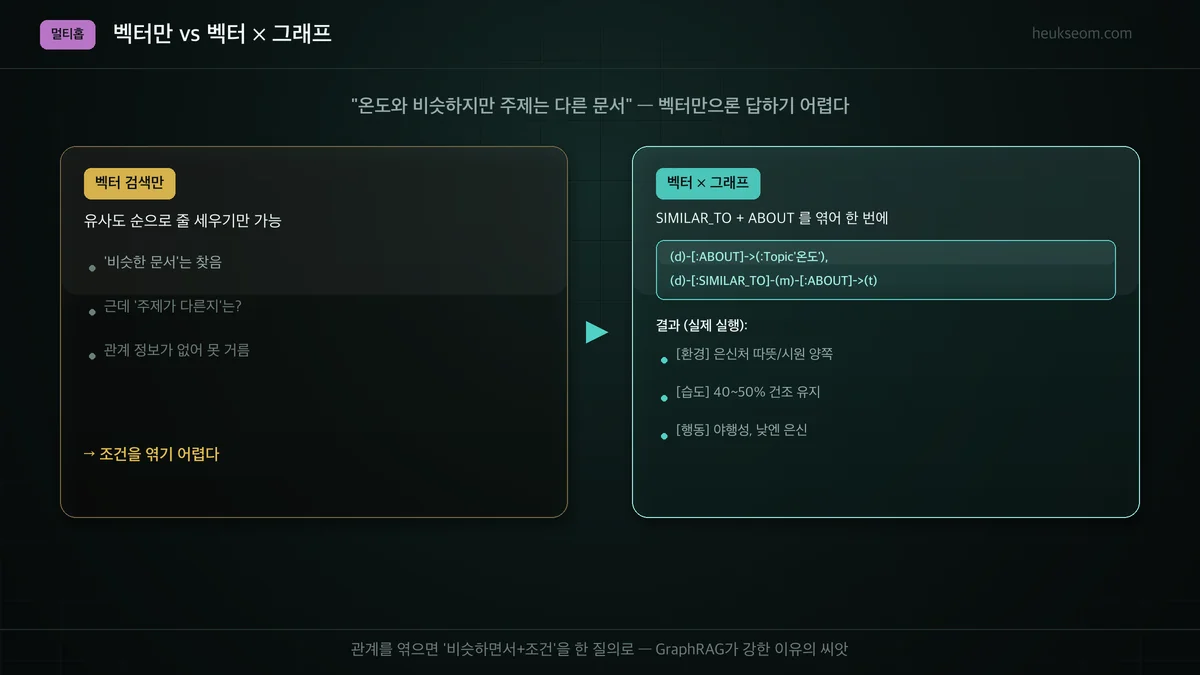
벡터와 그래프를 엮으면 뭐가 되나요? (멀티홉)
관계를 여러 개 이어 붙이면 '멀티홉' 질의가 됩니다. 예를 들어 "온도 문서와 의미가 비슷하면서, 주제는 온도가 아닌 문서"는 SIMILAR_TO(의미)와 ABOUT(구조)을 함께 엮어야 답할 수 있습니다. 벡터 검색만으로는 표현하기 어려운, 조건을 결합한 질문입니다. 이게 GraphRAG가 강한 이유의 핵심입니다.
실습 — 멀티홉: 비슷하지만 다른 주제 (셀 4)
# C) 온도 문서와 비슷하지만 '주제는 다른' 문서
s.run("""
MATCH (d:Doc)-[:ABOUT]->(:Topic {name:'온도'}),
(d)-[r:SIMILAR_TO]-(m:Doc)-[:ABOUT]->(t:Topic)
WHERE t.name <> '온도'
RETURN m.id, t.name, max(r.score) AS score, m.text
ORDER BY score DESC LIMIT 4
""")온도와 의미는 가깝지만 주제는 환경·습도·행동인 문서가 나왔어요. 벡터 유사도(SIMILAR_TO)와 주제 구조(ABOUT)를 한 패턴에 엮은 결과입니다.
이 멀티홉 경로를 그림으로 그리면 더 분명해집니다. Neo4j에서 실제 경로 데이터를 꺼내서 그려봤어요.
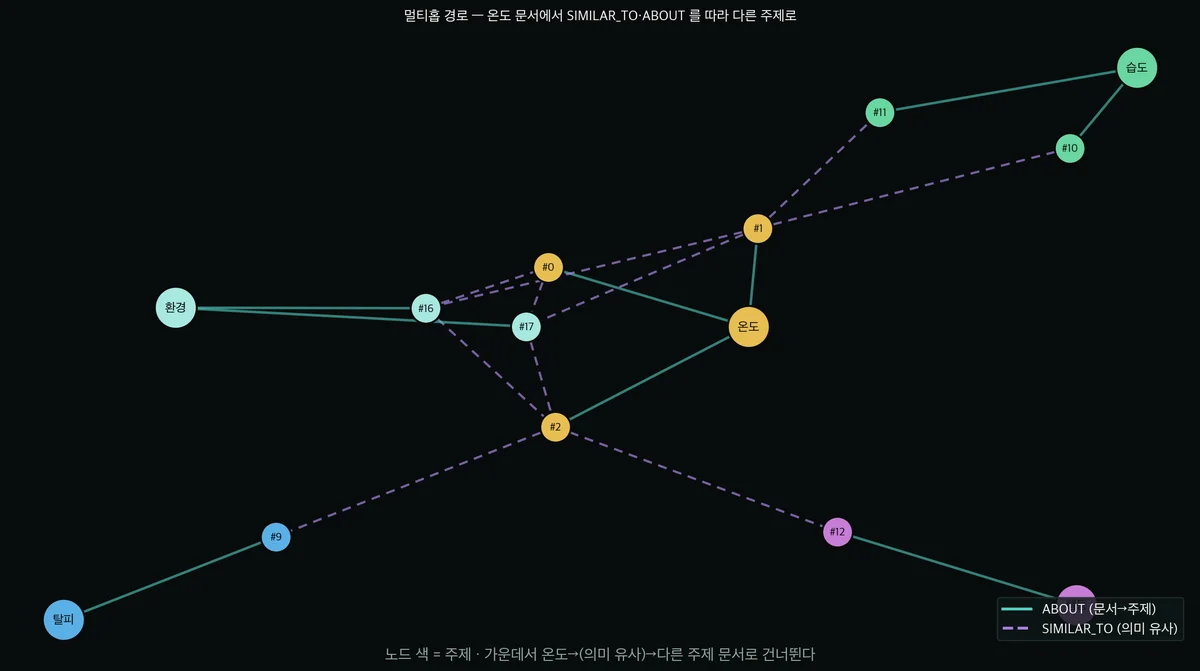
가운데 '온도' 주제(골드)에서 온도 문서(#0·#1·#2)로 내려간 뒤, 보라색 점선(SIMILAR_TO)을 타고
환경·습도·행동 같은 다른 주제 문서로 건너뛰는 게 보이죠. 구조(ABOUT)와 의미(SIMILAR_TO)를 한 경로에서 엮은 결과예요.
Neo4j Browser에서 같은 경로(RETURN p)를 실제로 그려보면 이렇게 나옵니다.
SIMILAR_TO 관계만 따로 그려보면, 1편에서 봤던 '의미 이웃 네트워크'가 이제 진짜 Neo4j 그래프로 들어와 있습니다.
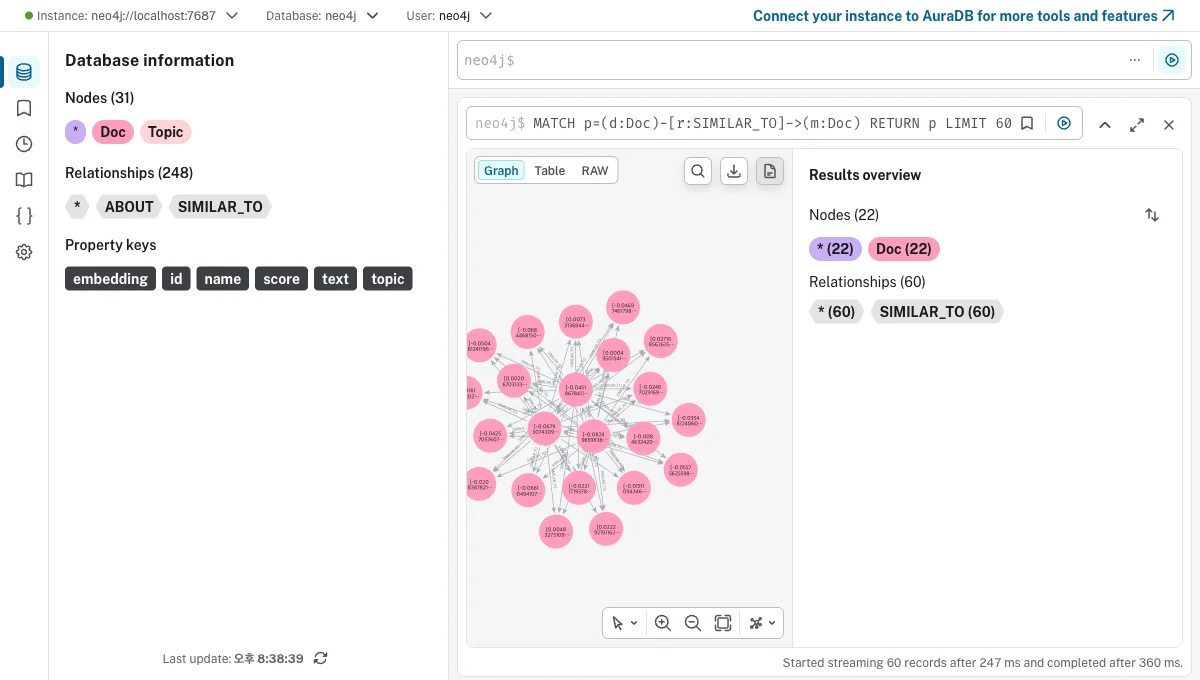
1편에선 matplotlib로 그려본 그림이었는데, 이제 DB 안의 진짜 관계가 된 거예요. 여기에 Cypher로 질문을 던질 수 있고요.
그래서 벡터랑 그래프, 뭘 언제 쓰나요?
벡터 검색은 '무엇과 비슷한가'를 잘 찾고, 그래프 탐색은 '무엇과 연결됐는가'를 잘 따라갑니다. 둘은 경쟁이 아니라 보완 관계입니다. GraphRAG는 벡터로 진입점을 찾은 뒤, 그래프로 그 주변 맥락을 끌어오는 방식으로 둘을 합칩니다.
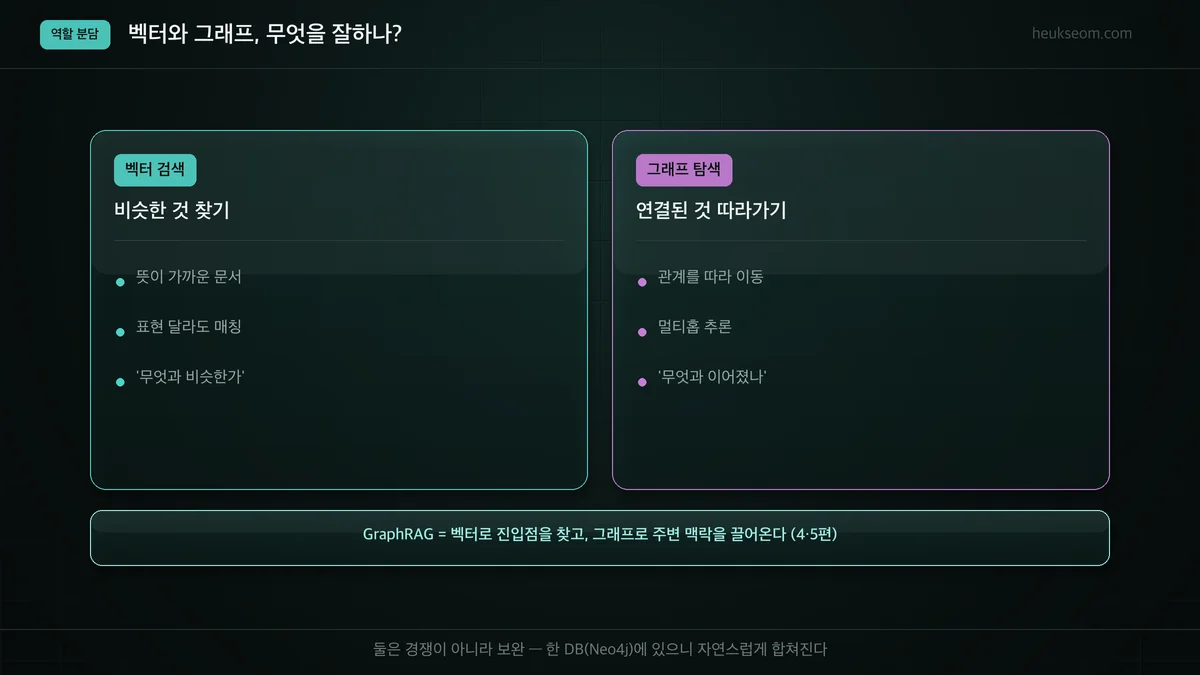
벡터로 "비슷한 것"을 찾고, 그래프로 "연결된 것"을 따라간다 — 이 두 축을 한 DB(Neo4j)에 두니 자연스럽게 합쳐집니다.
4편에서 이 둘을 하나의 검색으로 묶는 하이브리드 검색을 다룹니다.
실전 지식그래프는 얼마나 풍부해지나요?
이번 데모는 관계가 ABOUT·SIMILAR_TO 두 종류뿐이지만, 실제 도메인 지식그래프는 인과(CAUSES)·예방(PREVENTS)·치료(TREATED_BY)·징후(INDICATES) 같은 의미 있는 관계로 훨씬 정교해집니다. 관계가 풍부할수록 그래프 탐색으로 답할 수 있는 질문이 많아지고, 이게 GraphRAG가 강력해지는 근본 이유입니다.
감을 더 주려고, 제가 따로 만들어 본 레오파드게코 사육 지식그래프를 가져왔습니다.
앞의 데모처럼 단순 유사 관계가 아니라, 사육 지식의 인과·치료 관계를 직접 모델링한 거예요.
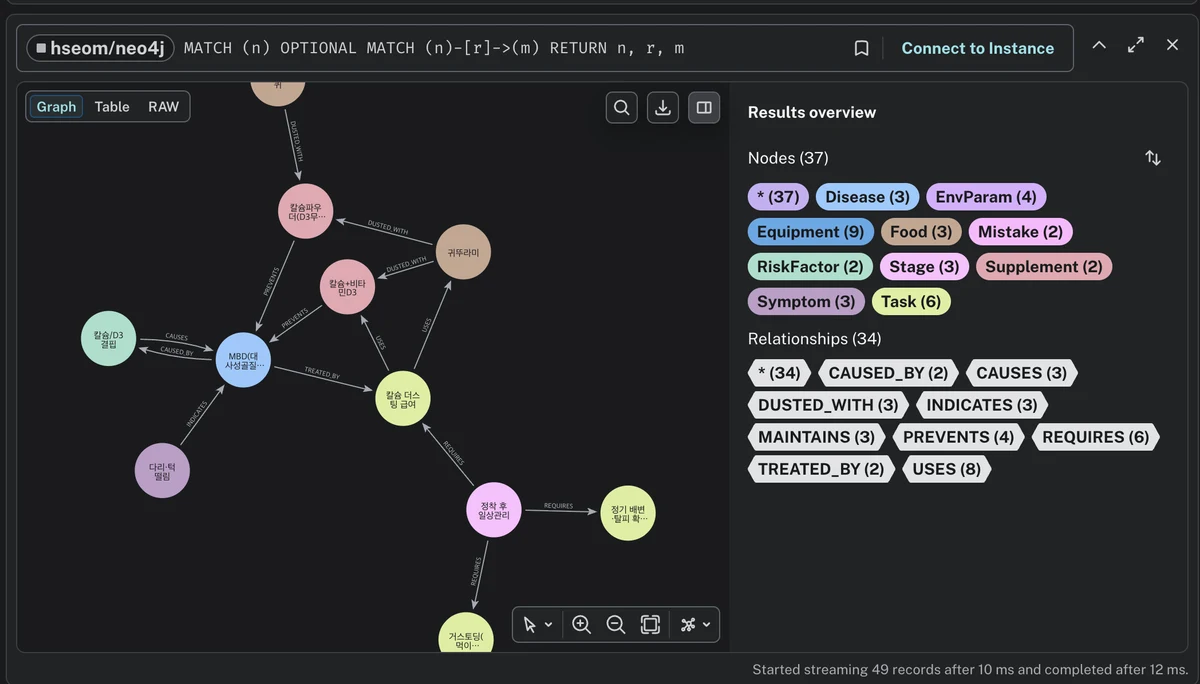
가운데 MBD(대사성 골질환)를 중심으로 보면 관계가 읽힙니다.
'칼슘/D3 결핍 →CAUSES→ MBD', '다리 떨림 →INDICATES→ MBD', '칼슘 더스팅 →TREATED_BY', '귀뚜라미 →DUSTED_WITH→ 칼슘 파우더' 처럼요.
관계 타입만 9종(CAUSES·PREVENTS·TREATED_BY·INDICATES·REQUIRES·USES·MAINTAINS·DUSTED_WITH·CAUSED_BY)입니다.
전체를 한 화면에 띄우니 노드가 빽빽해서 라벨이 잘 안 보이더라고요. 그래서 'MBD 예방' 갈래만 확대해봤습니다.
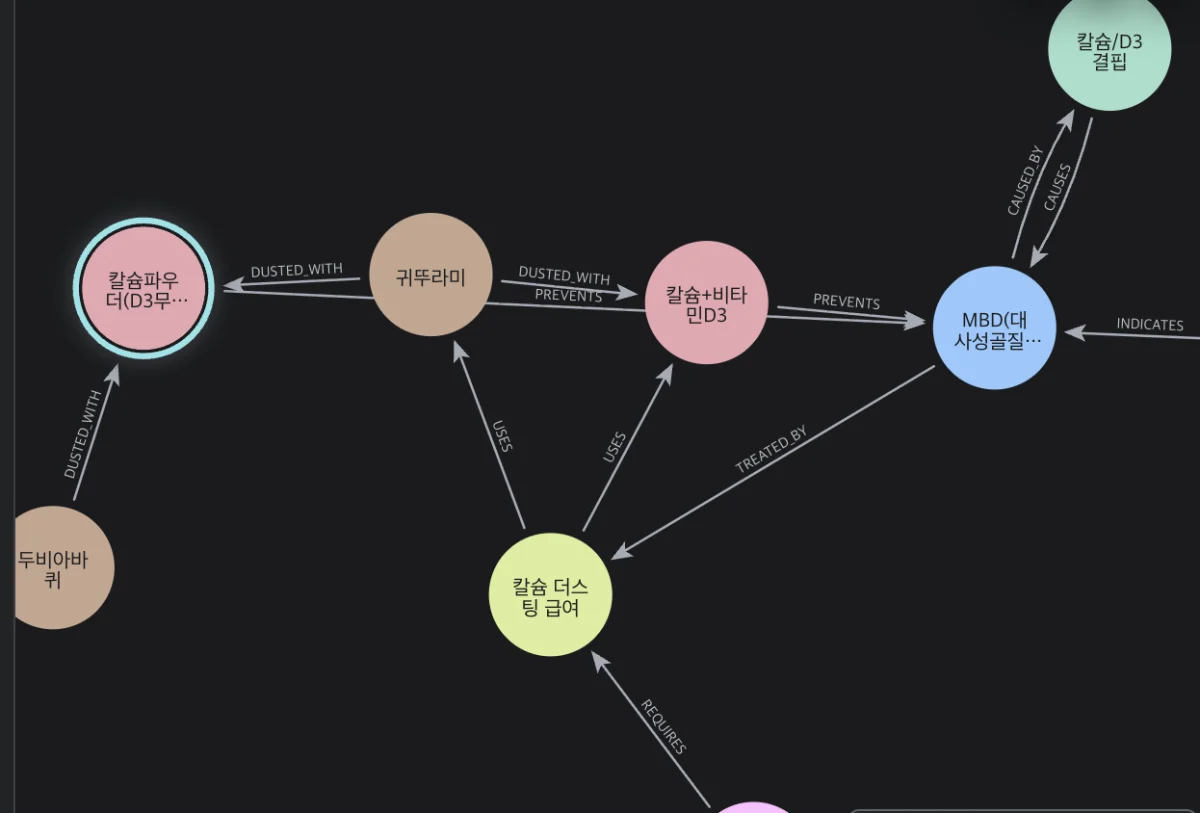
확대하니 관계가 이야기처럼 읽힙니다. 제가 읽은 한 갈래는 이래요.
'두비아바퀴 →DUSTED_WITH→ 칼슘파우더(D3무)', '귀뚜라미 →DUSTED_WITH→ 칼슘+비타민D3', 그리고 그 '칼슘+비타민D3 →PREVENTS→ MBD'.
반대편을 보면 'MBD ←CAUSES→ 칼슘/D3 결핍'(서로 원인·결과로 물려 있죠), 'MBD →INDICATES'(다리 떨림 같은 징후로 드러남), '칼슘 더스팅 급여 →TREATED_BY→ MBD'(치료), 그리고 그 더스팅 급여가 '→USES→ 귀뚜라미·칼슘+비타민D3'를 쓰고요.
여기서 '칼슘 부족하면 어떻게 되고, 어떻게 막지?'를 물으면 — 결핍이 MBD를 부르고(CAUSES), 그 MBD는 칼슘+비타민D3가 막아주며(PREVENTS), 그 칼슘+비타민D3는 귀뚜라미에 더스팅해서 먹인다(DUSTED_WITH) — 이렇게 한 갈래가 쭉 따라옵니다.
관계 이름이 의미를 담고 있으니, 노드만 잔뜩인 그래프와는 답할 수 있는 질문의 깊이가 다른 것 같아요.
이런 관계망 위에서는 "MBD의 원인이 뭐고, 어떻게 예방하고, 무슨 장비가 필요한가?" 같은 질문이
한 번의 그래프 탐색으로 줄줄이 따라와집니다. 벡터 유사도만으론 절대 못 하는 일이죠.
우리 데모의 ABOUT·SIMILAR_TO는 그 출발점이고, 5편 GraphRAG에서 이런 풍부한 그래프에 LLM을 붙입니다.
정리
3편에서 다룬 핵심만 정리합니다.
- 2편까지는 노드만 있는 '벡터 창고'였습니다. 3편에서 관계를 이어 지식그래프로 만들었습니다.
- ABOUT(문서→주제, 구조)과 SIMILAR_TO(의미 유사)를 두 축으로 엮었습니다.
- SIMILAR_TO는 Neo4j의 vector.similarity.cosine으로 DB 안에서 자동 생성했습니다.
- Cypher 패턴 매칭으로 구조 질의·의미 이웃·멀티홉을 탐색했습니다.
- "비슷하면서 다른 주제" 같은 조건 결합 질의는 벡터만으론 어렵고, 그래프가 있어야 됩니다.

이제 우리 DB엔 벡터도 있고 관계도 있습니다. 재료가 다 모인 거예요.
다음 4편에서는 벡터로 진입점을 찾고 그 주변을 그래프로 확장하는 하이브리드 검색을 만듭니다. GraphRAG(5편)가 코앞이에요.