
[벡터DB·지식그래프 RAG 5편] GraphRAG 완성 — 검색에 LLM을 붙이다
지식그래프 RAG 5부작의 마지막 편. 4편까지 완성한 하이브리드 검색(벡터 진입 + 그래프 확장) 위에 LLM(Claude)을 얹어 GraphRAG를 완성합니다. RAG가 검색+생성인 이유, baseline RAG(벡터검색만)의 한계, neo4j-graphrag의 GraphRAG 클래스로 검색기와 LLM을 묶는 법을 다룹니다. 같은 질문에 baseline RAG vs GraphRAG 답변을 실제로 생성해 비교 — 그래프로 넓힌 맥락이 답에 어떻게 반영되는지 실데이터로 확인합니다.
검색은 끝났습니다 — 이제 LLM이 답할 차례
4편까지 오면서 검색 엔진을 완성했습니다. 벡터로 진입점을 찾고, 그래프로 주변 맥락을 넓히는 구조였죠.
근데 검색은 '관련 문서'를 모아줄 뿐, 사람이 원하는 건 결국 정리된 답변입니다.
그래서 마지막 5편에서는 이 검색 위에 LLM(Claude)을 얹습니다.
찾아온 맥락을 LLM에게 건네 근거 있는 답을 만들게 하는 것, 이게 바로 GraphRAG입니다. 그리고 평범한 RAG와 실제로 답이 얼마나 달라지는지 같은 질문으로 돌려서 비교해봅니다.
5편에서 하는 것: RAG가 검색+생성인 이유 → baseline RAG(벡터검색만)의 한계 → neo4j-graphrag의 GraphRAG 클래스로 하이브리드 검색 + LLM 연결 → 같은 질문에 두 방식의 답변을 실제로 생성해 비교. 2·3·4편의 Neo4j(벡터+관계)를 그대로 씁니다.

검색이 LLM을 근거 있는 답으로 안내하는 GraphRAG — 등대처럼. (사진: Wikimedia Commons, Public Domain)
RAG가 정확히 뭐였죠?
RAG(검색 증강 생성)는 두 단계입니다. 먼저 질문과 관련된 문서를 DB에서 검색(retrieval)하고, 그 문서를 근거로 LLM이 답을 생성(generation)합니다. LLM이 '아는 대로' 답하지 않고 '찾아온 자료'를 근거로 답하게 만드는 게 핵심입니다. 그래서 답 품질은 결국 검색이 어떤 맥락을 가져오느냐에 달려 있습니다.

보면 LLM은 마지막 한 칸일 뿐이에요. 앞의 '검색'이 엉뚱한 문서를 가져오면, 아무리 좋은 LLM도 엉뚱하게 답합니다.
우리가 4편까지 검색 엔진을 공들여 만든 이유가 바로 이거였습니다.
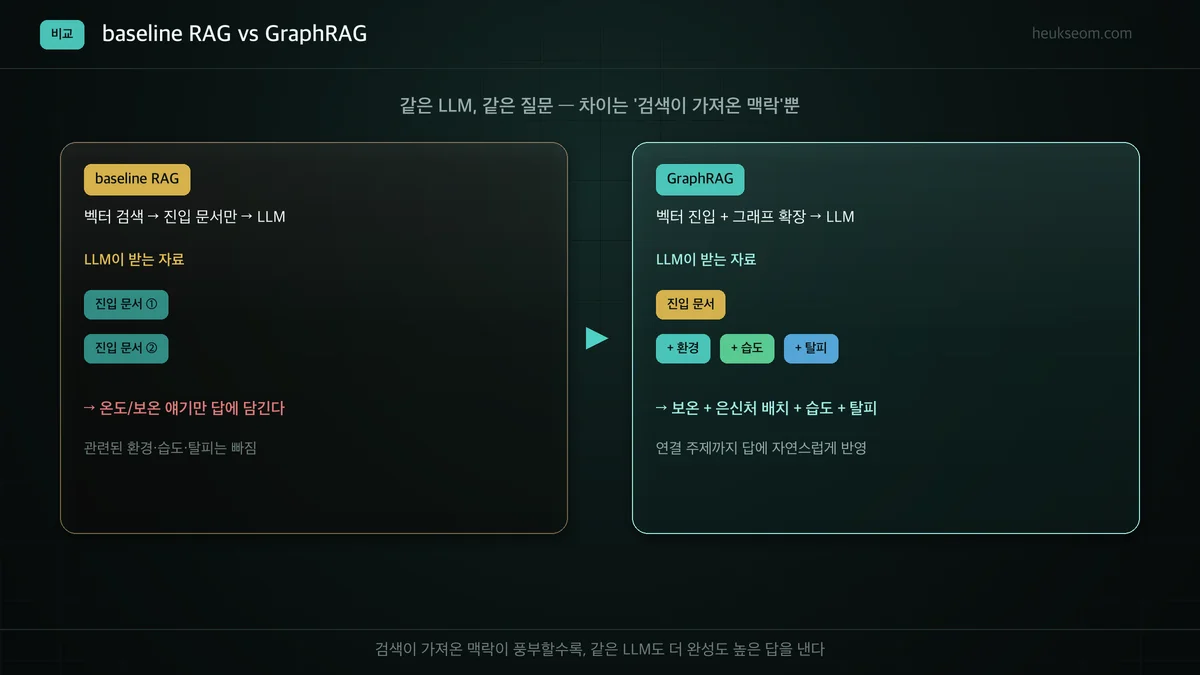
그냥 벡터 검색만 쓰면 답이 왜 얕을까요?
baseline RAG는 벡터 검색으로 진입 문서 몇 개만 찾아 LLM에 줍니다. 그러면 LLM은 그 진입 문서 안의 내용만으로 답하게 됩니다. 진입 문서가 '온도' 얘기뿐이면 답도 온도 얘기뿐이고, 정작 관련된 환경·습도·탈피 같은 맥락은 답에서 빠집니다. 검색이 좁으면 답도 좁아집니다.
실습 — baseline RAG (벡터 검색 → LLM) (셀 1)
from neo4j import GraphDatabase
from neo4j_graphrag.retrievers import VectorRetriever
from neo4j_graphrag.embeddings.sentence_transformers import SentenceTransformerEmbeddings
driver = GraphDatabase.driver("bolt://localhost:7687", auth=("neo4j", "***"))
embedder = SentenceTransformerEmbeddings(model="jhgan/ko-sroberta-multitask")
# 벡터로 진입 문서 2개만 검색
vr = VectorRetriever(driver, index_name="doc_embedding",
embedder=embedder, return_properties=["text"])
docs = [it.content for it in vr.search(query_text="겨울에 너무 추울 때 어떻게 관리하죠?",
top_k=2).items]
# 검색한 문서만 근거로 LLM에 질문 (claude CLI 사용)
context = "\n".join(f"- {d}" for d in docs)
prompt = f"아래 자료만 근거로 답해라.\n{context}\n질문: 겨울에 너무 추울 때?"
# subprocess.run(["claude", "-p", prompt]) → 진입 문서 범위 안에서만 답LLM에 주는 자료가 진입 문서 2개뿐입니다. 답도 딱 그 범위 안에서만 나옵니다.
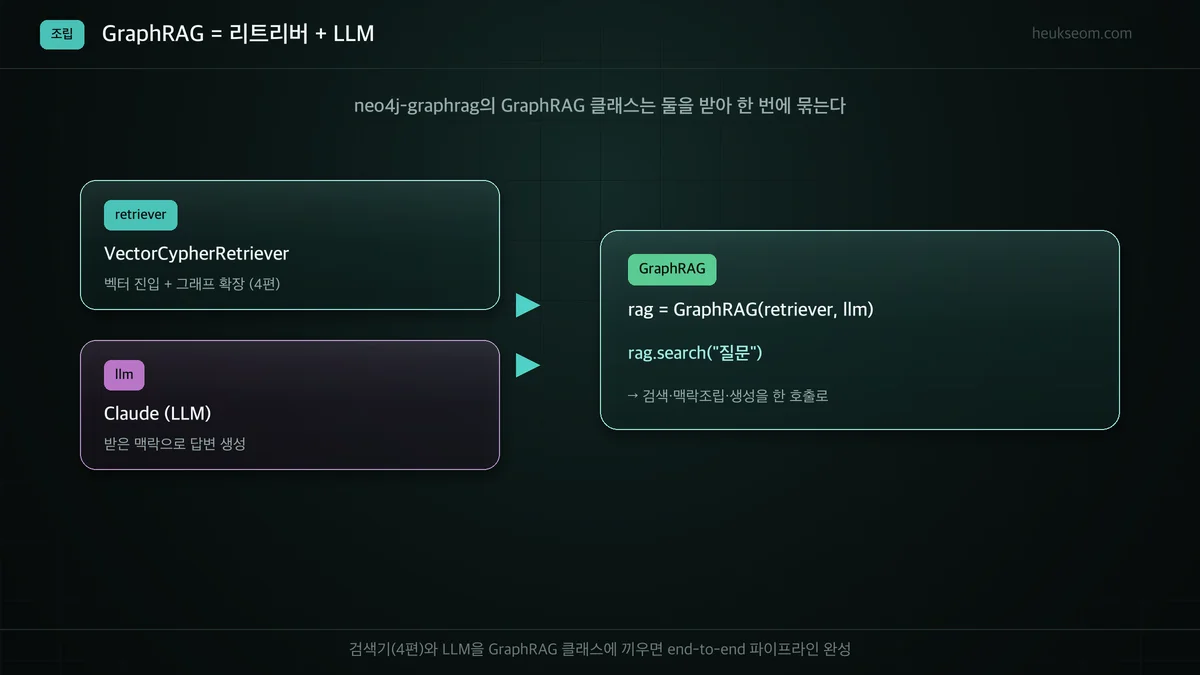
GraphRAG는 어떻게 조립하나요?
neo4j-graphrag의 GraphRAG 클래스는 리트리버와 LLM을 받아 하나로 묶습니다. 리트리버로 4편의 VectorCypherRetriever(벡터 진입 + 그래프 확장)를 넣으면, 검색·맥락 조립·답변 생성이 rag.search("질문") 한 호출로 끝납니다. 검색은 4편에서 만들었으니, 5편은 거기에 LLM만 끼우면 됩니다.
실습 — GraphRAG 클래스 (검색 + LLM) (셀 2)
from neo4j_graphrag.retrievers import VectorCypherRetriever
from neo4j_graphrag.generation import GraphRAG
from neo4j_graphrag.llm import AnthropicLLM
# 4편의 검색기: 벡터 진입 + 그래프 확장
retrieval_query = """
MATCH (node)-[:ABOUT]->(seedTopic:Topic)
OPTIONAL MATCH (node)-[s:SIMILAR_TO]-(nb:Doc)-[:ABOUT]->(nbTopic:Topic)
WHERE s.score > 0.7
RETURN node.text AS entry, seedTopic.name AS topic,
collect(DISTINCT nbTopic.name) AS linked_topics,
collect(DISTINCT nb.text)[0..3] AS expanded
"""
retriever = VectorCypherRetriever(driver, index_name="doc_embedding",
retrieval_query=retrieval_query, embedder=embedder)
# 검색기 + LLM = GraphRAG (공식 방식)
llm = AnthropicLLM(model_name="claude-haiku-4-5")
rag = GraphRAG(retriever=retriever, llm=llm)
print(rag.search(query_text="겨울에 너무 추울 때 어떻게 관리하죠?").answer)GraphRAG(retriever, llm) 한 줄로 검색·맥락조립·생성이 묶입니다. 이 글의 캡처는 API 키 없이 로컬 Claude CLI로 LLM을 대신했지만, 원리는 같습니다.
말로만 하면 와닿지 않으니, LLM에 넘기기 직전에 검색기가 실제로 어떤 서브그래프를 끌어오는지 Neo4j Browser에서 그대로 돌려봤습니다.
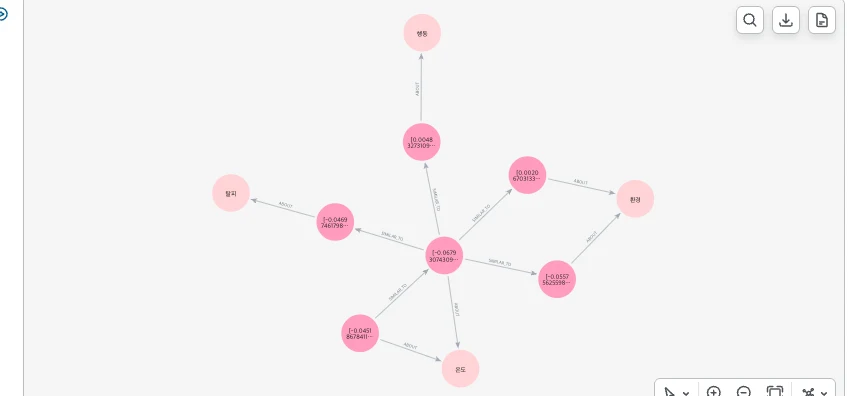
가운데 진한 노드가 벡터로 찾은 진입 문서입니다. 거기서 SIMILAR_TO로 이웃 문서들이 뻗고, 다시 ABOUT으로 온도·환경·탈피·행동 같은 주제까지 이어지죠.
문서 노드의 캡션이 숫자 배열로 보이는데, 그게 바로 각 문서의 임베딩 벡터예요. 벡터로 진입해 그래프로 넓힌다는 게 화면에 그대로 찍힙니다. ㅎㅎ
같은 질문, 두 답변 — 진짜로 달라질까?
같은 LLM(Claude)에 같은 질문을 주되, 검색이 가져온 맥락만 다르게 해서 답을 비교했습니다. baseline은 진입 문서 2개만, GraphRAG는 진입 문서에 그래프로 연결된 환경·습도·탈피 문맥까지 줬습니다. 결과는 아래처럼 답의 폭이 확연히 달라졌습니다.
[B]의 풍부한 맥락이 어디서 왔는지는 검색 화면을 보면 분명합니다. 같은 검색기를 Neo4j Browser에서 돌려, 진입 문서가 어떤 경로로 확장되는지 쿼리·그래프·경로 표를 한 화면에 펼쳤습니다.
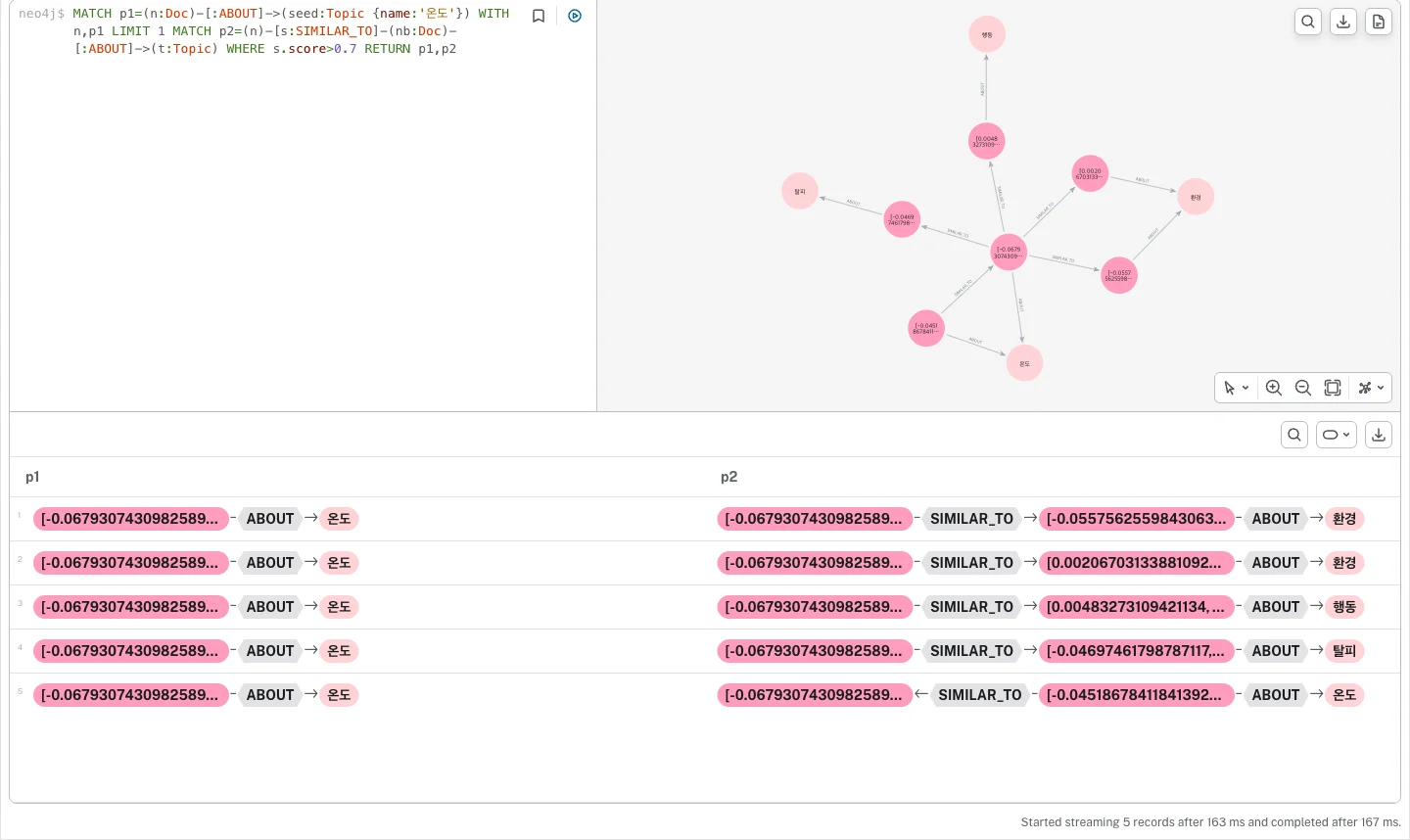
아래 표의 한 줄 한 줄이 곧 LLM에 넘어간 맥락입니다. p1은 진입 문서가 ABOUT으로 온도 주제에 닿는 경로, p2는 같은 문서가 SIMILAR_TO 이웃을 거쳐 환경·행동·탈피 주제로 번지는 경로예요.
맨 왼쪽 칸이 전부 같은 임베딩 벡터로 시작하는 게 보이죠? 벡터로 한 점을 잡고, 거기서 그래프로 가지를 친 결과가 이 표입니다.
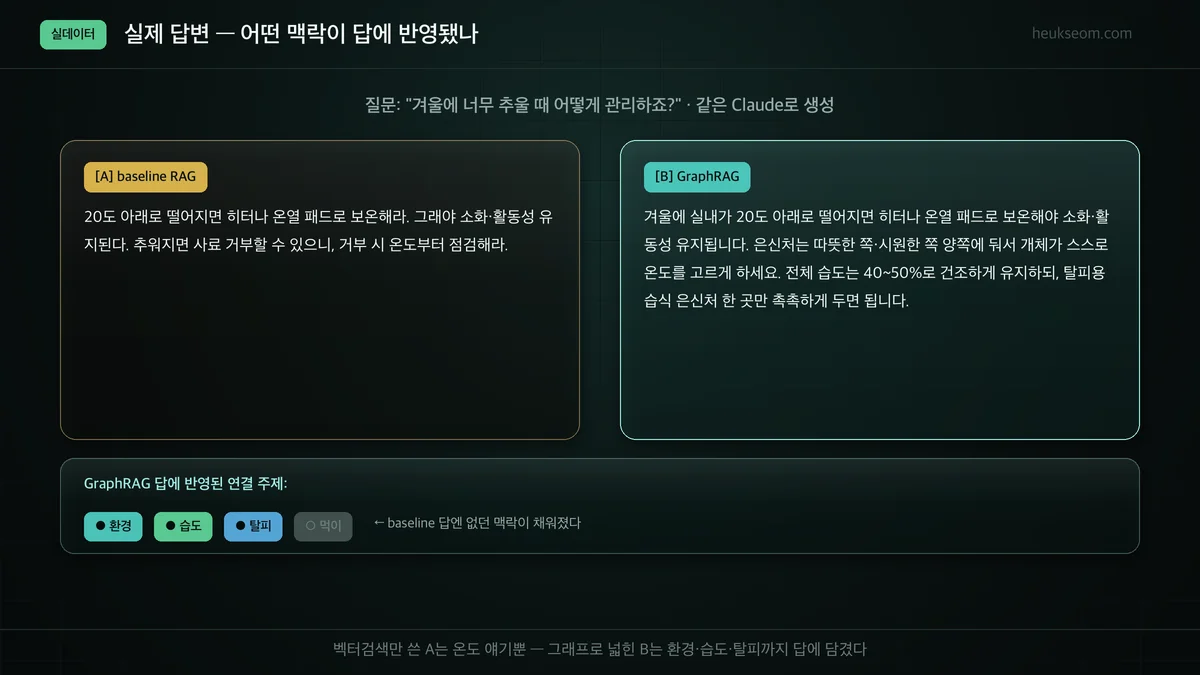
[A]는 온도·보온 얘기로 끝납니다. 진입 문서가 그것뿐이었으니까요.
[B]는 같은 보온 얘기에 더해 은신처 배치(환경)·습도 40~50%·탈피용 습식 은신처까지 답에 들어왔습니다. 그래프로 끌어온 연결 주제가 답에 그대로 반영된 거죠.
솔직히 처음엔 LLM이 받은 맥락을 다 안 쓰고 흘릴 줄 알았는데, 막상 돌려보니 연결 주제를 꽤 알뜰하게 답에 녹이더라고요. ㅎㅎ
그리고 한 가지, 검색을 욕심내서 너무 많이 끌어오면 LLM 답이 산만해지기도 했습니다. 4편에서 score > 0.7로 걸러둔 게 여기서 답을 깔끔하게 만들어준 셈이라 ㅋㅋ, 검색 품질이 곧 답 품질이라는 말이 체감됐어요.
정리 — 그리고 5부작을 마치며
5편 핵심부터 정리합니다.
- RAG는 검색(retrieval) + 생성(generation). 답 품질은 검색이 가져온 맥락이 가릅니다.
- baseline RAG는 진입 문서만 LLM에 줘서 답이 좁아집니다.
- GraphRAG는 4편의 하이브리드 검색(벡터 진입 + 그래프 확장)을 LLM에 연결합니다.
- neo4j-graphrag의 GraphRAG(retriever, llm)로 검색·맥락조립·생성을 한 호출로 묶습니다.
- 같은 LLM·같은 질문이라도, 그래프로 넓힌 맥락을 주면 답에 연결 주제까지 담깁니다.
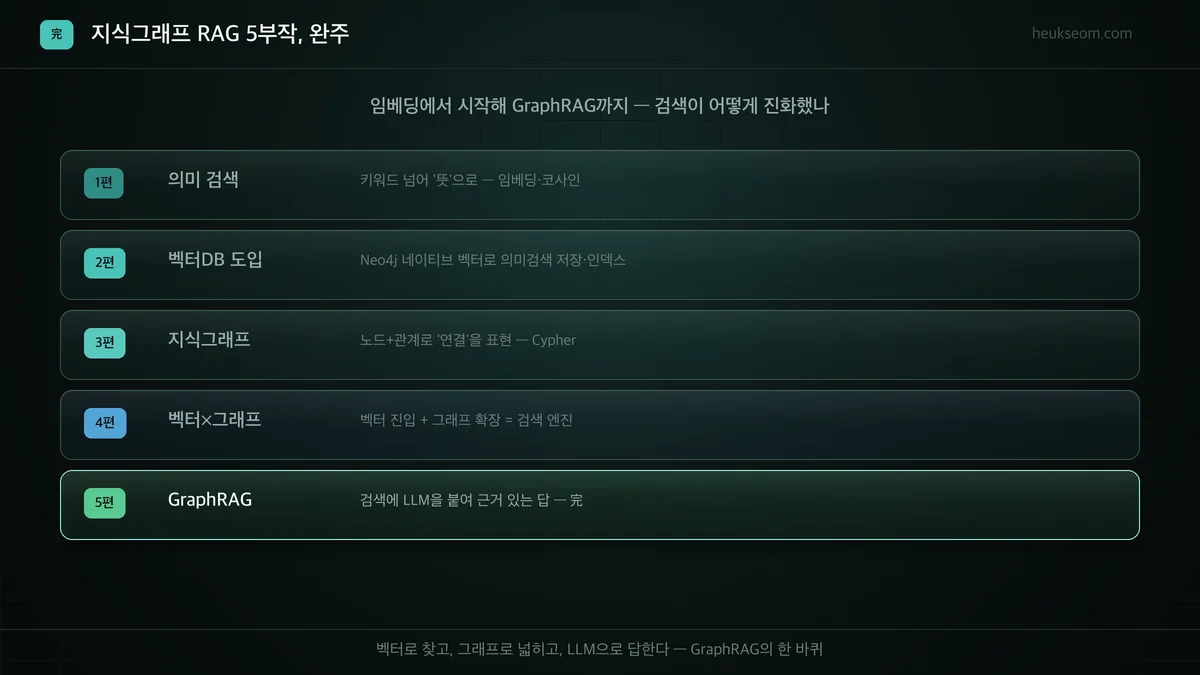
1편에서 키워드를 넘어 '뜻'으로 검색하는 임베딩으로 시작했습니다. 2편에서 Neo4j 벡터DB에 담고, 3편에서 노드·관계로 지식그래프를 그렸고, 4편에서 벡터와 그래프를 한 검색으로 합쳤죠. 그리고 5편에서 그 위에 LLM을 얹어 근거 있는 답까지 만들었습니다.
제가 생각하는 이 시리즈의 핵심은, '벡터로 찾고, 그래프로 넓히고, LLM으로 답한다'는 한 바퀴를 직접 돌려본 것 같습니다. 작은 게코 FAQ로 해봤지만, 데이터가 무엇이든 구조는 그대로예요.
여기까지 따라오느라 고생 많으셨습니다. 다음엔 이 GraphRAG를 실제 문서 묶음에 붙여 더 큰 규모로 굴려보는 이야기를 들고 올 수 있으면 좋겠네요. ㅎㅎ