
[Step 2] 산점도로 데이터 관계 파악하기 - matplotlib scatter
운동 시간과 체중 감량, 공부 시간과 성적... 두 데이터 사이에 관계가 있을까요? Step 2에서는 산점도로 데이터 간 상관관계를 한눈에 파악하는 방법을 배웁니다.
두 데이터 사이에 관계가 있는지 어떻게 알 수 있나요?
산점도(Scatter Plot)를 그려보면 돼요. 두 변수를 X축과 Y축에 점으로 찍으면, 점들이 특정 방향으로 모이는지 흩어지는지를 보고 상관관계가 있는지 한눈에 파악할 수 있습니다.
Step 1에서는 시간에 따른 변화를 선 그래프로 그렸습니다. 이번엔 조금 다른 질문을 해볼게요. "두 데이터 사이에 관계가 있을까?"
이런 상황들을 생각해보세요:
- 운동 시간이 늘어나면 체중이 줄어들까?
- 공부 시간과 성적은 비례할까?
- 광고비를 늘리면 매출이 오를까?
- 먹이량을 늘리면 레오파드 게코 체중이 증가할까?
이런 질문들의 답을 찾을 때 사용하는 게 바로 산점도(Scatter Plot)입니다. 두 변수를 점으로 찍어서, 패턴이 보이는지 확인하는 거죠.
이 글은 데이터 시각화 Step 2로, 산점도 그리는 방법론을 다룹니다. 예제로는 키-몸무게, 공부시간-성적을 사용하지만, 핵심은 상관관계 발견 방법입니다.
Google Colab만으로 20분이면 완성할 수 있습니다. Step 1을 해봤다면, Step 2는 더 쉬울 거예요!
산점도는 실생활에서 어떻게 쓰이나요?
본격적으로 시작하기 전에, 산점도가 실제로 어떻게 쓰이는지 살펴볼게요. "이런 상황에서 쓰는 거구나!" 하고 감을 잡으시면 됩니다.
상황 1: 다이어트 효과 확인하기
운동 시간을 늘렸는데, 정말 체중이 줄어드는지 궁금하죠? 매일 운동 시간(분)과 체중 감량(kg)을 기록했다면, 산점도로 그려보세요.
- 점들이 오른쪽 아래로 흐르면 → 운동 많이 할수록 체중 감소 (음의 상관관계)
- 점들이 무작위로 흩어져 있으면 → 운동과 체중 감량은 무관 (상관관계 없음)
상황 2: 공부 시간과 성적 관계
학생이라면 누구나 궁금한 질문: "공부 시간과 성적은 비례할까?" 시험 전 일평균 공부 시간과 시험 점수를 산점도로 그려보면, 실제로 비례하는지, 아니면 일정 시간 이상은 효과가 없는지 한눈에 보입니다.
상황 3: 부동산 가격 분석
집을 사려고 할 때, 면적(㎡)과 가격(만원)의 관계를 산점도로 그리면 "우리 동네는 면적당 가격이 비싼 편인가?" "이 매물은 싼 편인가?"를 판단할 수 있습니다.
상황 4: 브리딩 - 먹이량과 성장 속도
도마뱀을 키우면서 급여량(마리)과 체중 증가(g)를 기록했다면, 산점도로 그려보세요. "먹이를 더 주면 정말 빨리 자랄까?"를 데이터로 확인할 수 있습니다.
상황 5: 비즈니스 - 광고비와 매출
매달 광고비(만원)와 매출(만원)을 기록하고 있다면, 산점도로 "광고비를 늘릴수록 매출이 오르는가?"를 분석할 수 있습니다. 점들이 직선에 가까울수록, 투자 대비 효과를 예측하기 쉬워집니다.
이제 감이 오시나요? 산점도는 "X가 증가하면 Y는 어떻게 변할까?"라는 질문에 답하는 가장 직관적인 방법입니다.
환경 세팅 - Google Colab 준비
Step 1을 따라 하셨다면 이미 익숙하실 거예요. 브라우저에서 colab.research.google.com에 접속하고, "+ New notebook"으로 새 노트북을 만드세요.
파일명은 scatter_plot.ipynb로 저장하면 됩니다.
Google Colab 시작 화면 - '+ New notebook'으로 새 노트북 생성
라이브러리 설치
첫 번째 셀에 다음 코드를 입력하고 Shift + Enter를 누르세요:
!pip install matplotlib numpy pandas
pip install 실행 결과 - 'Successfully installed' 메시지 확인
각 라이브러리의 역할:
- matplotlib: 그래프 그리기 (Step 1에서 사용했던 그 라이브러리!)
- numpy: 숫자 데이터 다루기
- pandas: 표 형태 데이터 다루기 (선택사항이지만 편리함)
산점도용 데이터는 어떻게 준비하나요?
실제 데이터를 준비하는 게 가장 좋지만, 연습용으로 간단한 데이터를 직접 만들어볼게요. 새 셀에 다음 코드를 입력하세요:
예제 1: 공부 시간 vs 성적
import numpy as np
import matplotlib.pyplot as plt
# 10명의 학생 데이터 (가상)
study_hours = [1, 2, 2.5, 3, 3.5, 4, 4.5, 5, 5.5, 6] # 일평균 공부 시간
test_scores = [55, 60, 62, 68, 72, 75, 78, 82, 85, 88] # 시험 점수
print("공부 시간:", study_hours)
print("시험 점수:", test_scores)Shift + Enter를 누르면 데이터가 출력됩니다. 보시다시피, 공부 시간이 늘어날수록 성적도 오르는 것 같죠? 하지만 숫자만 봐서는 확신이 서지 않습니다. 그래프로 그려봐야 명확해집니다!
산점도는 어떻게 그리나요?
이제 드디어 산점도를 그려볼 시간입니다! 새로운 셀에 다음 코드를 입력하세요:
# 한글 폰트 설정 (Google Colab용)
plt.rcParams['font.family'] = 'DejaVu Sans'
plt.rcParams['axes.unicode_minus'] = False
# 산점도 그리기
plt.figure(figsize=(10, 6))
plt.scatter(study_hours, test_scores, color='#3498db', s=100, alpha=0.7)
# 스타일링
plt.title('Study Hours vs Test Scores', fontsize=16, pad=20)
plt.xlabel('Study Hours (hours/day)', fontsize=12)
plt.ylabel('Test Score (points)', fontsize=12)
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()Shift + Enter를 누르면... 짜잔! 파란색 점들이 나타납니다!
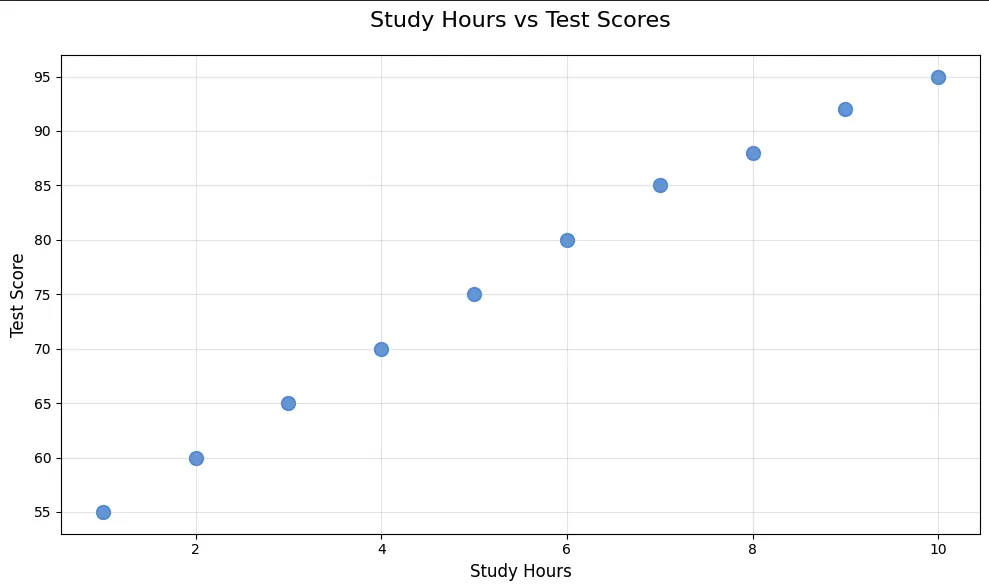
첫 번째 산점도 완성 - 공부 시간이 늘수록 성적이 올라가는 양의 상관관계
점들이 왼쪽 아래에서 오른쪽 위로 올라가는 패턴이 보이죠? 이건 양의 상관관계입니다. 공부 시간이 늘어날수록 성적도 올라간다는 뜻이에요.
코드 이해하기
• plt.scatter(x, y): X축에 study_hours, Y축에 test_scores를 점으로 찍음
• s=100: 점 크기 (숫자가 클수록 점이 커짐)
• alpha=0.7: 투명도 (0~1, 작을수록 투명)
상관관계에는 어떤 패턴이 있나요?
산점도를 보면, 크게 3가지 패턴이 나타납니다. 각 패턴이 무엇을 의미하는지 알아볼게요.
패턴 1: 양의 상관관계 (Positive Correlation)
점들이 왼쪽 아래 → 오른쪽 위로 올라가는 패턴
- X가 증가하면 Y도 증가
- 예시: 공부 시간 ↑ → 성적 ↑, 광고비 ↑ → 매출 ↑
패턴 2: 음의 상관관계 (Negative Correlation)
점들이 왼쪽 위 → 오른쪽 아래로 내려가는 패턴
- X가 증가하면 Y는 감소
- 예시: 운동 시간 ↑ → 체중 ↓, 가격 ↑ → 판매량 ↓
패턴 3: 무상관 (No Correlation)
점들이 무작위로 흩어진 패턴
- X와 Y 사이에 관계가 없음
- 예시: 키와 성적, 생일과 체중 (관계 없음)
응용 1: 음의 상관관계 그려보기
이번엔 운동 시간과 체중 감량 데이터를 그려볼게요. 운동을 많이 할수록 체중이 줄어드는 패턴이 나타날 겁니다.
# 운동 시간과 체중 감량 데이터
exercise_hours = [0.5, 1, 1.5, 2, 2.5, 3, 3.5, 4, 4.5, 5] # 주간 운동 시간
weight_loss = [0.2, 0.5, 0.8, 1.2, 1.5, 1.8, 2.1, 2.4, 2.7, 3.0] # 한 달 체중 감량 (kg)
plt.figure(figsize=(10, 6))
plt.scatter(exercise_hours, weight_loss, color='#e74c3c', s=100, alpha=0.7)
plt.title('Exercise vs Weight Loss', fontsize=16, pad=20)
plt.xlabel('Weekly Exercise (hours)', fontsize=12)
plt.ylabel('Monthly Weight Loss (kg)', fontsize=12)
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()이번엔 빨간색 점들이 오른쪽 위로 올라갑니다. 운동 시간이 늘어날수록 체중 감량도 증가하는 양의 상관관계네요! (음의 상관관계가 아니라 헷갈리시나요? 여기선 "감량량"이 Y축이라서 둘 다 증가하는 거예요)
응용 2: 색상으로 그룹 구분하기
산점도에서 점의 색상을 다르게 하면, 그룹별 비교가 가능합니다. 예를 들어, 남학생과 여학생의 키-몸무게 관계를 비교해볼게요.
# 남학생 데이터
male_height = [165, 170, 172, 175, 178, 180]
male_weight = [60, 65, 68, 70, 75, 78]
# 여학생 데이터
female_height = [155, 158, 160, 162, 165, 168]
female_weight = [48, 50, 52, 55, 58, 60]
plt.figure(figsize=(10, 6))
# 남학생 (파란색)
plt.scatter(male_height, male_weight, color='#3498db', s=100, alpha=0.7, label='Male')
# 여학생 (핑크색)
plt.scatter(female_height, female_weight, color='#e91e63', s=100, alpha=0.7, label='Female')
plt.title('Height vs Weight by Gender', fontsize=16, pad=20)
plt.xlabel('Height (cm)', fontsize=12)
plt.ylabel('Weight (kg)', fontsize=12)
plt.legend(fontsize=12)
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()이제 파란색 점(남학생)과 핑크색 점(여학생)으로 구분되어 나타납니다. 두 그룹 모두 키가 클수록 몸무게가 증가하지만, 남학생 그룹이 전체적으로 더 무겁다는 걸 한눈에 알 수 있죠.
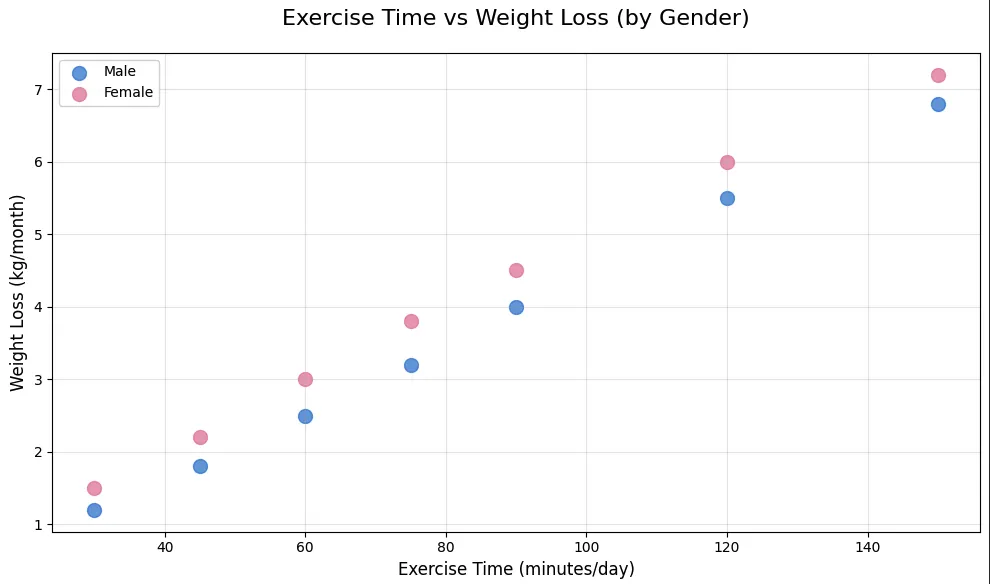
색상으로 그룹 구분하기 - 파란색(남학생), 핑크색(여학생)
응용 3: 점 크기로 추가 정보 표현하기
점의 크기를 데이터에 따라 다르게 하면, 3개의 변수를 한 그래프에 담을 수 있습니다. 예를 들어, 광고비-매출 관계에서 점 크기를 "광고 횟수"로 설정해볼게요.
# 광고비, 매출, 광고 횟수
ad_cost = [10, 20, 30, 40, 50, 60, 70, 80] # 만원
revenue = [50, 80, 110, 140, 170, 200, 230, 260] # 만원
ad_frequency = [5, 10, 15, 20, 25, 30, 35, 40] # 횟수
plt.figure(figsize=(10, 6))
# 점 크기를 광고 횟수에 비례하게 설정
plt.scatter(ad_cost, revenue, s=np.array(ad_frequency)*10, color='#9b59b6', alpha=0.6)
plt.title('Ad Cost vs Revenue (size = Ad Frequency)', fontsize=16, pad=20)
plt.xlabel('Ad Cost (10k KRW)', fontsize=12)
plt.ylabel('Revenue (10k KRW)', fontsize=12)
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()점이 클수록 광고 횟수가 많다는 뜻입니다. 이렇게 하면 X축(광고비), Y축(매출), 점 크기(광고 횟수) 3개 변수를 한 번에 볼 수 있어요!
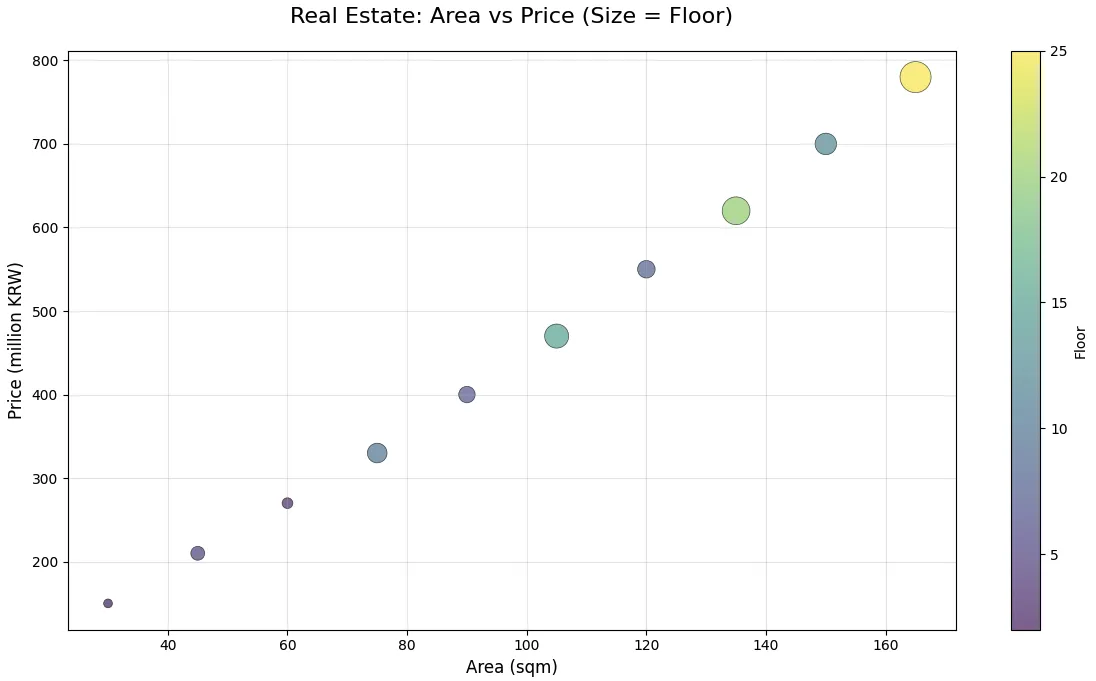
점 크기로 3번째 변수 표현 - 크기가 광고 횟수를 나타냄
응용 4: 고급 다변수 시각화 - 프로페셔널 그래프
지금까지 배운 기술들을 모두 결합하면, 정말 전문적인 그래프를 만들 수 있습니다. 이번엔 5개의 변수를 한 그래프에 담아볼게요.
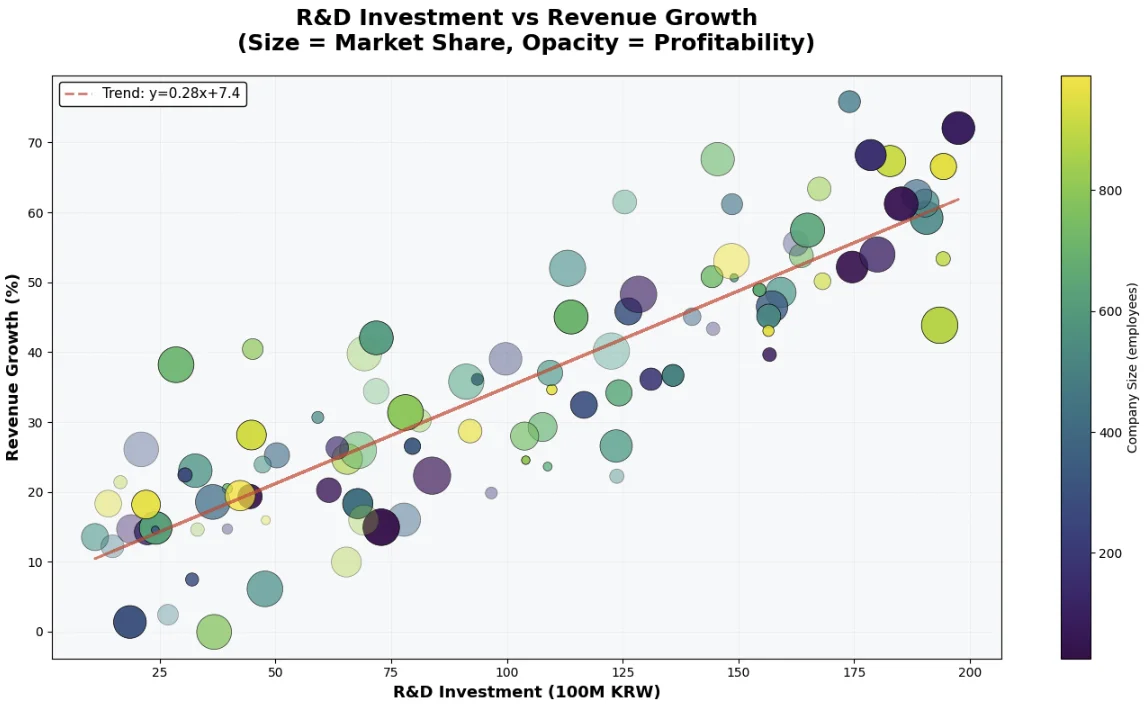
R&D 투자와 매출 증가율 관계 - 크기, 색상, 투명도로 추가 정보 표현
이 그래프가 보여주는 5가지 정보
- X축: R&D 투자 규모 (억원)
- Y축: 매출 증가율 (%)
- 점 크기: 시장 점유율 - 클수록 점유율 높음
- 점 색상: 기업 규모 (직원 수) - 노란색에서 보라색으로
- 투명도: 수익성 - 진할수록 수익성 높음
여기에 더해, 빨간 점선은 추세선입니다. 전체 데이터의 경향성을 한눈에 파악할 수 있죠.
실전 활용 시나리오
이런 고급 시각화는 비즈니스 보고서, 논문, 프레젠테이션에서 정말 강력합니다. 한 장의 그래프로 복잡한 데이터를 설득력 있게 전달할 수 있거든요.
- 투자 보고서: "어떤 기업에 투자해야 할까?" 판단 근거 제시
- 마케팅 분석: 광고비-매출-고객만족도-재구매율을 한눈에
- 연구 논문: 실험 변수들 간의 복잡한 관계를 시각적으로 증명
처음엔 어려워 보이지만, 우리가 지금까지 배운 기술들을 조합한 것뿐입니다. 점 크기 조절 + 색상 매핑 + 투명도 + 추세선 = 프로페셔널 그래프!
마무리 - 이제 뭘 할 수 있을까?
축하합니다! 이제 할 수 있는 것:
- 두 변수 간 상관관계를 산점도로 시각화할 수 있고
- 양의 상관관계, 음의 상관관계, 무상관을 구분할 수 있고
- 색상과 크기로 추가 정보를 표현할 수 있습니다
다음 단계로 나아가기
기본을 마스터했으니, 이제 더 재미있는 것들을 시도해볼 수 있습니다:
- 추세선 추가: numpy의 polyfit으로 회귀선을 그려보세요
- 상관계수 계산: numpy.corrcoef()로 정확한 상관계수를 구할 수 있습니다
- 실제 데이터 활용: CSV 파일을 pandas로 불러와서 실전 데이터를 분석해보세요
- 3D 산점도: matplotlib의 3D 기능으로 3개 변수를 입체로 표현할 수 있습니다
흑섬 브리딩에서의 활용
저는 이 방법으로 레오파드 게코의 급여량과 체중 증가 관계를 분석하고 있습니다. "먹이를 더 주면 정말 빨리 자랄까?"라는 질문에, 산점도가 명확한 답을 줍니다.
산점도는 "X와 Y 사이에 관계가 있을까?"라는 질문에 답하는 가장 직관적인 방법입니다. 다이어트, 공부, 비즈니스, 브리딩—모든 분야에 적용할 수 있어요.
다음 시리즈 예고
다음 글에서는 "히스토그램으로 데이터 분포 파악하기" (Step 3)를 다뤄볼 예정입니다. 월별 판매량, 제품별 성적 같은 범주형 데이터를 막대 그래프로 표현하는 방법을 배워볼 거예요.
궁금한 점이 있거나, 이런 내용도 다뤄줬으면 좋겠다는 의견이 있다면 인스타그램 DM 주세요!