
LangChain이 Claude Code 복제품을 출시했습니다 — Deep Agents 직접 써봤습니다
2026년 3월, LangChain이 클로드 코드의 오픈소스 복제품 Deep Agents를 공개했습니다. 커뮤니티에서 '클로드 코드 복제품'이라는 말이 돌 정도로 반응이 뜨거웠고 GitHub 스타 12K를 넘겼습니다. 계획 도구, 파일시스템, 셸 실행, 서브에이전트까지 — 클로드 코드가 하는 걸 전부 오픈소스로 구현했습니다. MIT 라이선스에 어떤 LLM이든 연결 가능합니다. 직접 설치하고 로컬 LLM까지 연결해봤습니다.
LangChain의 Deep Agents는 Claude Code와 뭐가 다른가요?
Deep Agents는 LangChain이 만든 오픈소스 코딩 에이전트로, Claude Code와 비슷하게 터미널에서 코드를 생성하고 실행합니다. 핵심 차이는 모델 자유도인데, Claude Code는 Claude 전용이지만 Deep Agents는 아무 LLM이나 연결할 수 있고 파일시스템 백엔드도 6가지를 지원합니다.
2026년 3월, 커뮤니티에 소식 하나가 돌았습니다.
"LangChain이 클로드 코드의 복제품을 출시했다."
이게 Deep Agents입니다. LangChain이 만든 오픈소스 에이전트 하네스.
계획 세우기, 파일 읽고 쓰기, 셸 명령 실행, 서브에이전트 위임 — 클로드 코드가 하는 걸 전부 오픈소스로 구현했습니다.
MIT 라이선스. GitHub 스타 12K 돌파. (지금도 계속 늘고 있네요...ㅎㅎ 글 작성할 때만 해도 9.9K였는데 벌써 12K도 넘겼네요.. 이 속도면 20K도 금방일 것 같습니다)
왜 화제냐면 — Anthropic의 Claude Code, OpenAI의 Codex는 각자 자사 모델에만 묶여 있거든요.
Deep Agents는 달랐습니다.
어떤 LLM이든 연결 가능. Anthropic, OpenAI, Google, Azure, Bedrock, 로컬 Ollama까지.
Harrison Chase(LangChain CEO)는 이렇게 설명했습니다.
"Claude Code 같은 코딩 에이전트들이 실제로 어떻게 동작하는지 분석해봤다. 생각보다 단순한 원칙들 위에서 돌아갔다."
그 원칙들을 뜯어내서 오픈소스로 구현한 게 Deep Agents입니다.
쉽게 말하면 이겁니다.
Anthropic이 Claude Code에 숨겨둔 구조를 LangChain이 분석해서, 누구나 쓸 수 있게 무료로 공개했습니다.
왜 이게 중요하냐면
클로드 코드 같은 프로덕션급 AI 에이전트를 만들려면 원래 Anthropic API 비용 + 독점 구조에 묶여야 했습니다.
Deep Agents는 그 구조를 통째로 MIT 오픈소스로 풀어버렸습니다.
· 작업 전 TO-DO 리스트를 먼저 만들고, 복잡한 작업은 서브 에이전트에게 분배
· 파일 직접 읽고 쓰기, 셸 명령 실행, 사람 승인 단계(Human-in-the-loop)
· 장기 기억, 세션 간 컨텍스트 유지
· LangGraph 기반이라 실무 적용이 쉬움
이제 프로덕션급 AI 에이전트를 돈 한 푼 안 내고 직접 만들 수 있습니다.
모델도 자유롭게 — OpenAI, Google, 로컬 Ollama 전부 붙습니다.
→ 공식 사이트: langchain.com/deep-agents · 발표 블로그: blog.langchain.com/deep-agents · GitHub: langchain-ai/deepagents
Step 1. 핵심 아키텍처 — 4가지 설계 원칙
Harrison Chase가 밝힌 Deep Agents의 핵심 원칙은 네 가지입니다.
복잡하지 않습니다. 오히려 "이게 다야?" 싶을 만큼 심플합니다.
→ 공식 문서: docs.langchain.com — deepagents/overview
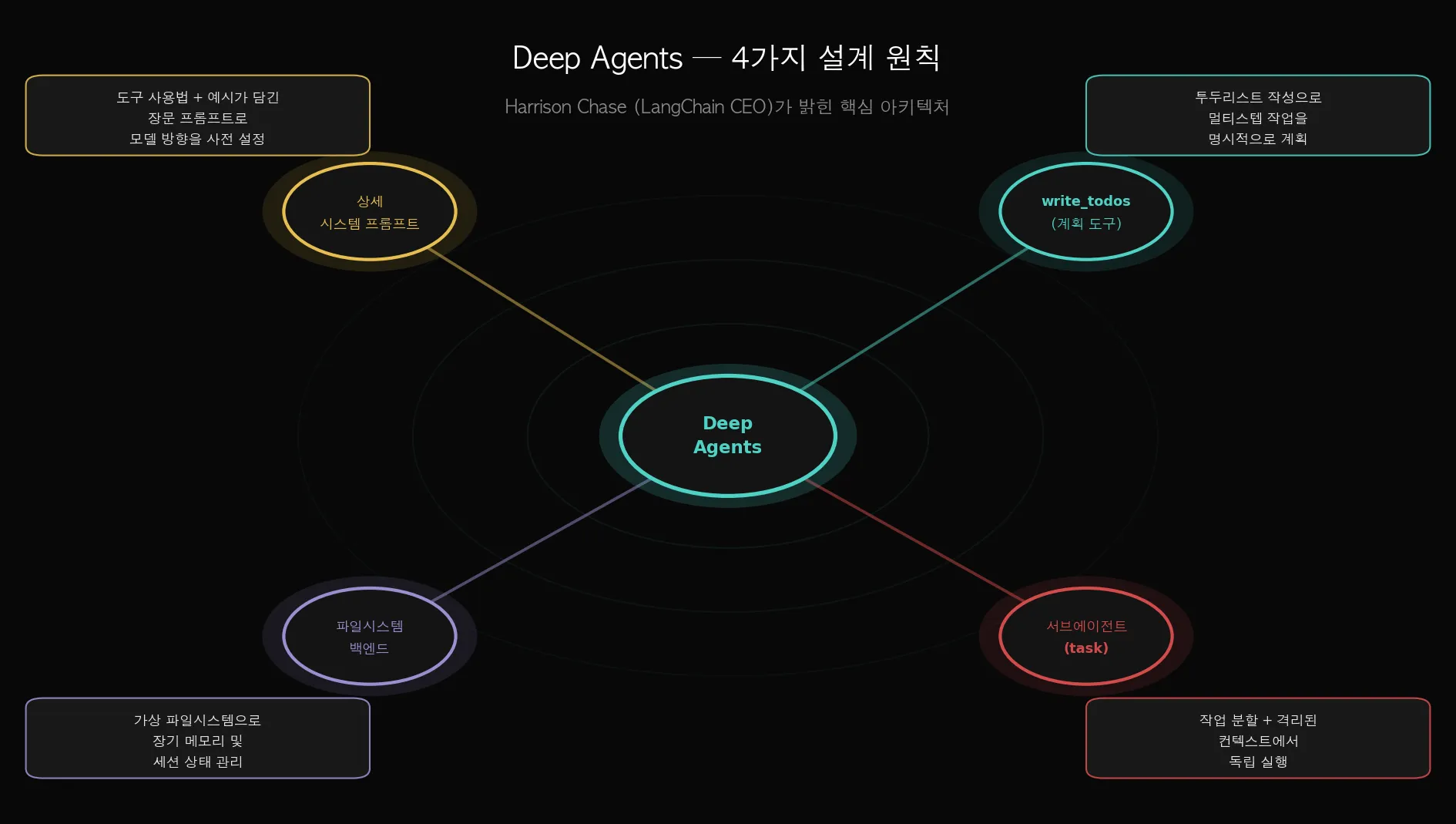
원칙 1 — 상세 시스템 프롬프트
도구 사용법과 예시가 담긴 장문의 시스템 프롬프트를 미리 제공합니다.
"언제 어떤 도구를 써야 하는지"를 모델에게 컨텍스트로 주는 거죠.
모델이 스스로 판단하게 하지 않고, 올바른 방향을 미리 잡아줍니다.
원칙 2 — write_todos (계획 도구)
투두리스트를 작성하고 업데이트하는 도구입니다.
흥미로운 건, 이 도구가 기능적으로는 아무것도 안 한다는 점입니다.
값을 반환하거나 외부 API를 호출하지 않아요. 그냥 투두를 기록할 뿐입니다.
그런데 이게 왜 효과적이냐면 — 모델이 "지금 뭘 해야 하는지" 명시적으로 계획을 세우게 강제하거든요.
Harrison Chase는 이를 "컨텍스트 공학(Context Engineering) 전략"이라고 불렀습니다.
실제로 write_todos가 있으면 없을 때보다 멀티스텝 작업 완성도가 높아집니다.
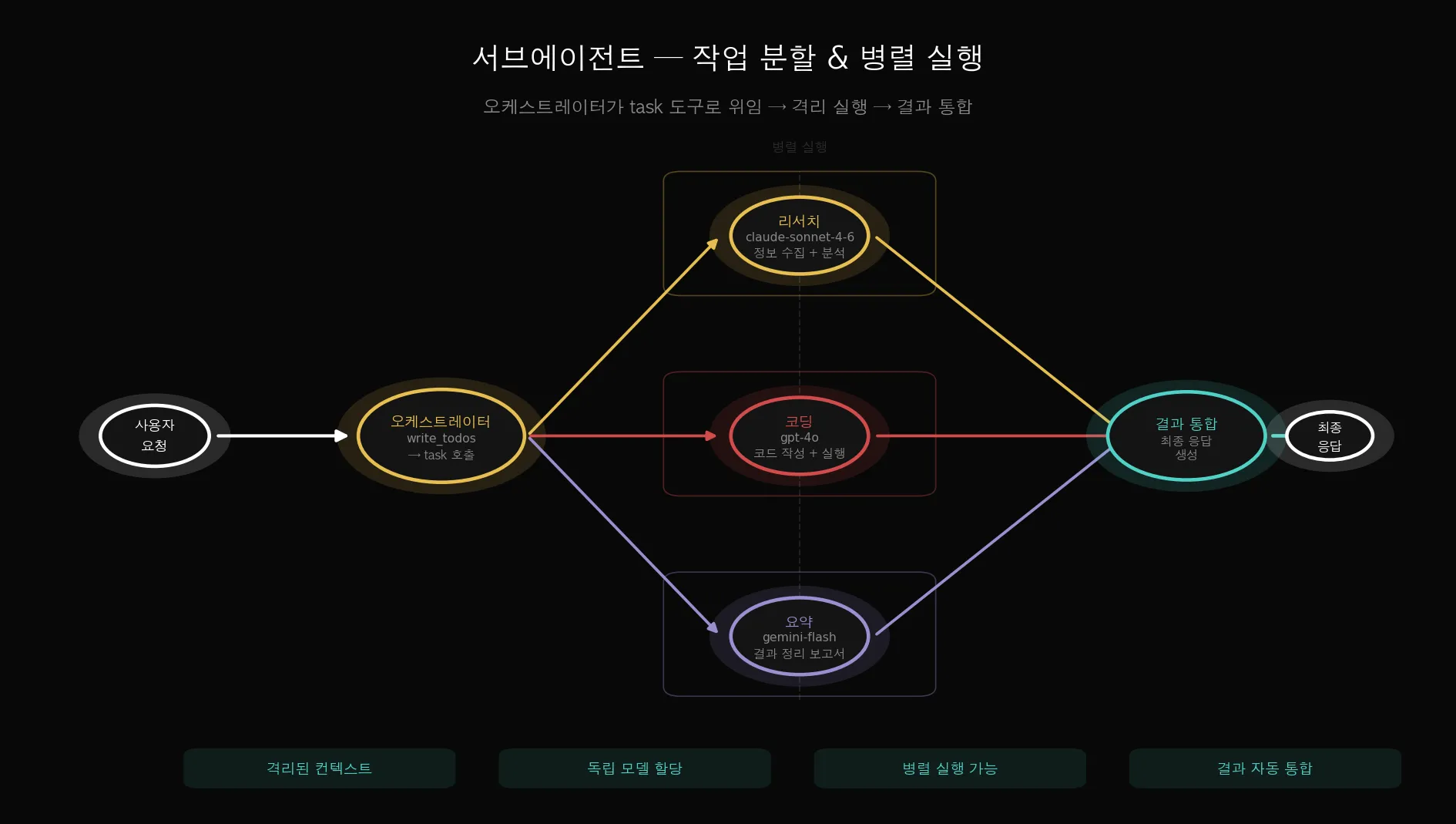
원칙 3 — 서브에이전트 (task 도구)
복잡한 작업을 독립된 서브에이전트에 위임합니다.
각 서브에이전트는 격리된 컨텍스트에서 실행돼서 메인 에이전트가 오버플로 없이 집중할 수 있습니다.
서브에이전트마다 다른 모델, 다른 도구, 다른 시스템 프롬프트를 줄 수 있습니다.
원칙 4 — 파일시스템 백엔드
가상 파일시스템으로 장기 메모리와 상태를 관리합니다.
세션이 끝나도 파일에 저장된 결과는 남아 있습니다. 6가지 백엔드를 지원하는데 뒤에서 자세히 봅니다.
Step 2. 설치 + 첫 에이전트 만들기
→ 공식 문서: docs.langchain.com — deepagents/quickstart
실제로 설치해봤습니다. pip install deepagents 한 줄이면 됩니다.
cap_install — 설치 확인 캡처
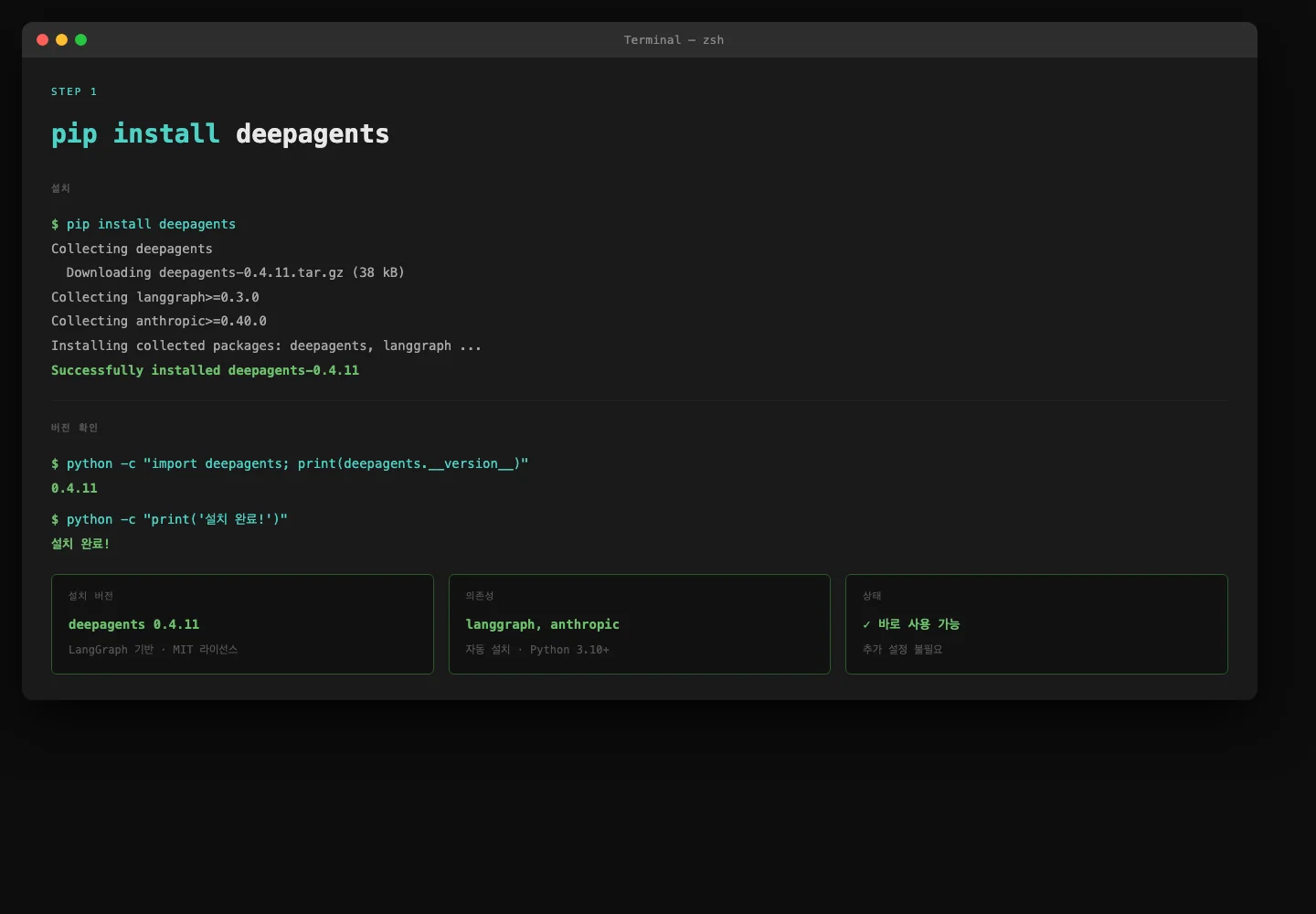
LangGraph와 Anthropic SDK가 자동으로 같이 설치됩니다.
버전은 0.4.11 (2026-03 기준).
가장 간단한 에이전트
from deepagents import create_deep_agent
# 도구 없음, 기본 모델(ANTHROPIC_API_KEY 환경변수 필요)
agent = create_deep_agent()
result = agent.invoke({
"messages": [{
"role": "user",
"content": "Python에서 리스트를 역순으로 정렬하는 방법 3가지"
}]
})
print(result["messages"][-1].content)cap_basic_run — 기본 실행 결과 캡처
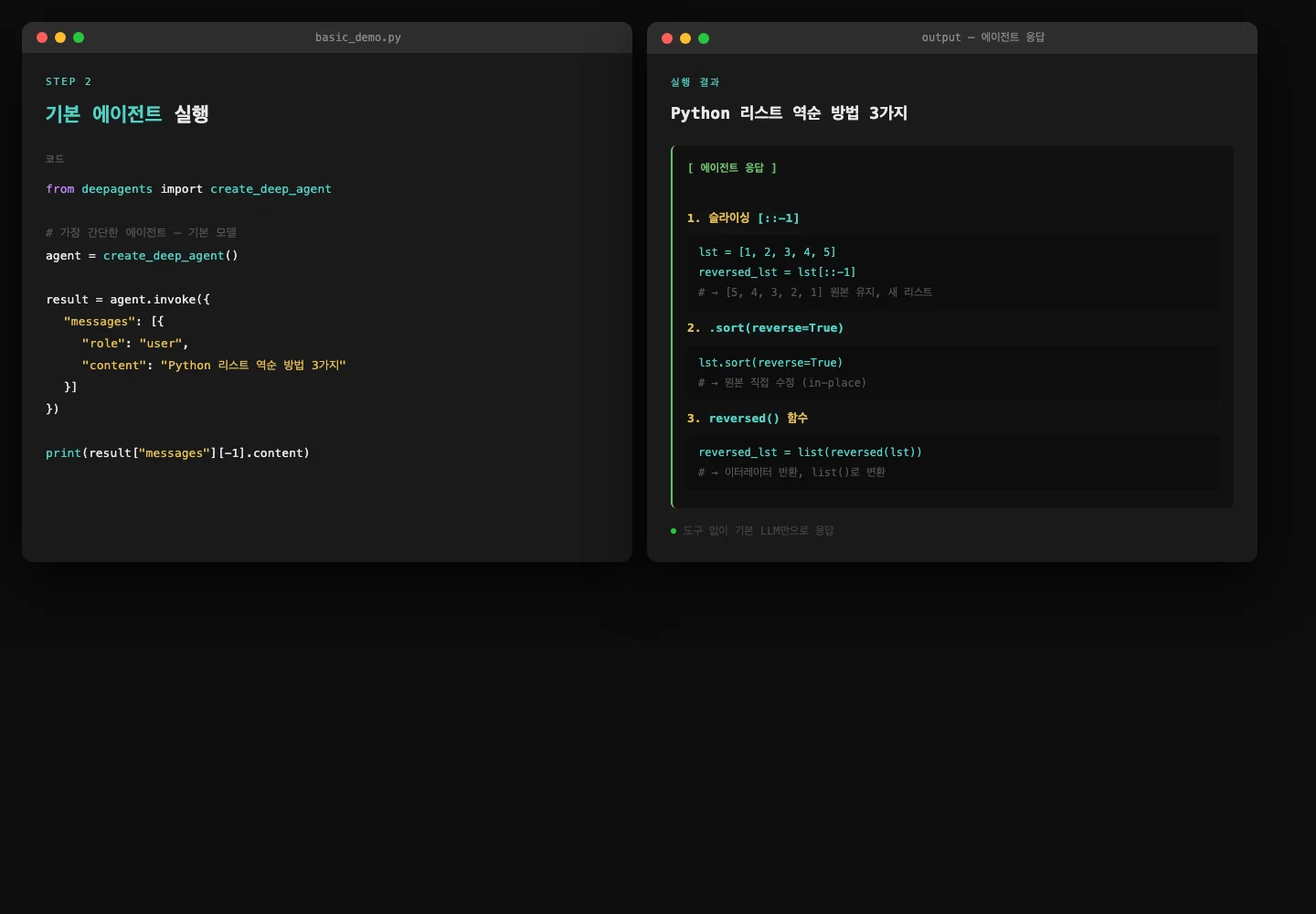
create_deep_agent()가 반환하는 건 LangGraph로 컴파일된 그래프입니다.
LangGraph 런타임 위에서 돌기 때문에 스트리밍, 체크포인팅, 영속성이 기본으로 제공됩니다.

커스텀 도구 추가
import pytz
from datetime import datetime
def get_current_time(timezone: str = "Asia/Seoul") -> str:
"""현재 시간을 조회합니다. timezone: 타임존 (예: Asia/Seoul, UTC)"""
tz = pytz.timezone(timezone)
now = datetime.now(tz)
return f"{timezone} 현재 시간: {now.strftime('%Y-%m-%d %H:%M:%S')}"
def calculate(expression: str) -> str:
"""수학 계산을 수행합니다. expression: 수식 (예: 2 + 3 * 4)"""
result = eval(expression, {"__builtins__": {}}, {})
return f"계산 결과: {expression} = {result}"
agent = create_deep_agent(
tools=[get_current_time, calculate],
system_prompt="당신은 시간과 계산을 도와주는 에이전트입니다.",
)cap_tools — 커스텀 도구 실행 흐름 캡처
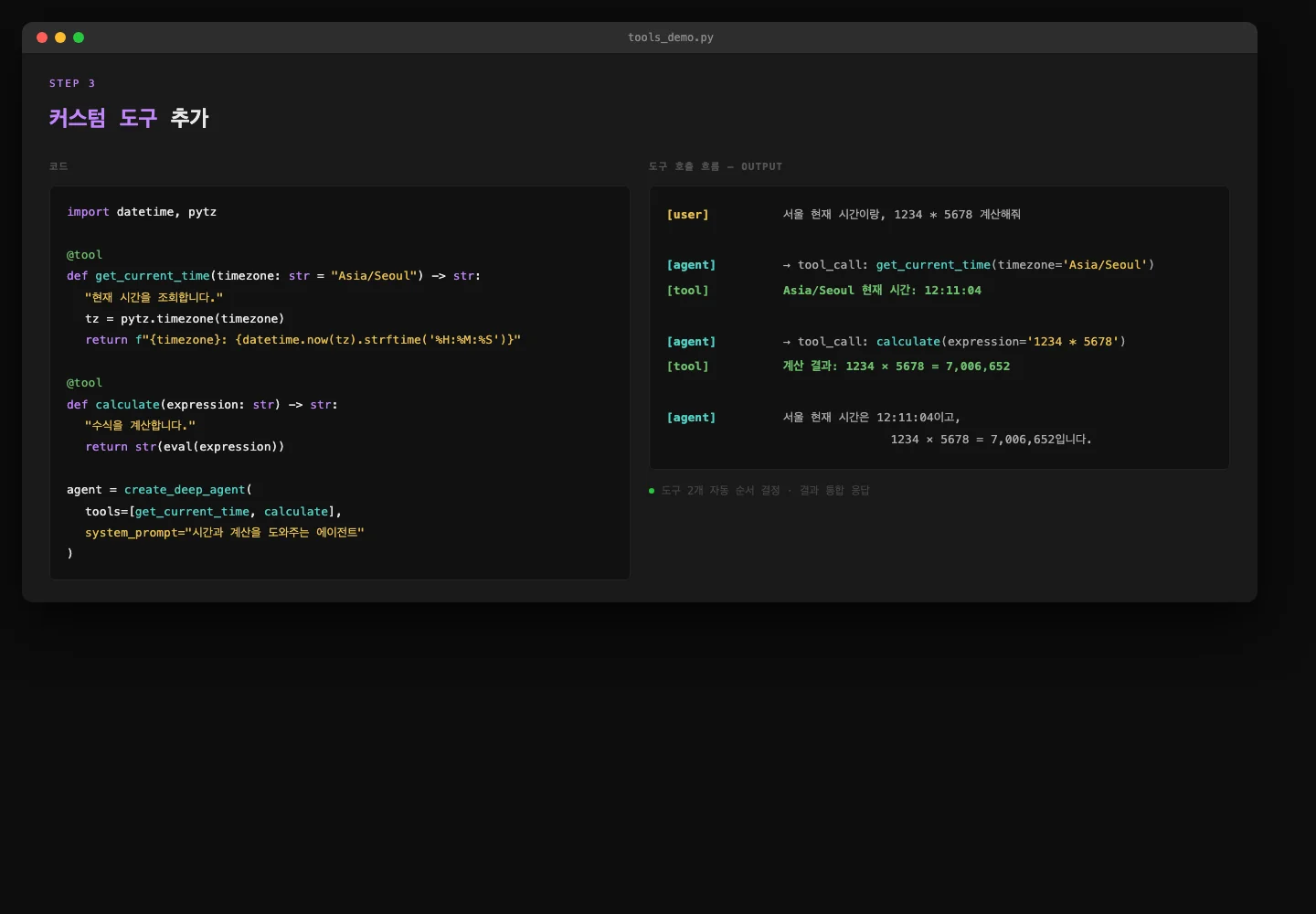
함수 docstring이 그대로 도구 설명으로 사용됩니다.
에이전트가 요청을 받으면 어떤 도구를 언제 쓸지 스스로 판단해서 순서대로 호출합니다.
그리고 Claude Code나 기타 고급 코딩 에이전트에서 사용하는 사용자 승인(Approval) 시스템도 그대로 구현되어 있습니다.
에이전트가 셸 명령이나 파일 수정 같은 위험한 작업을 수행하기 전에, 사용자에게 먼저 확인을 요청합니다.
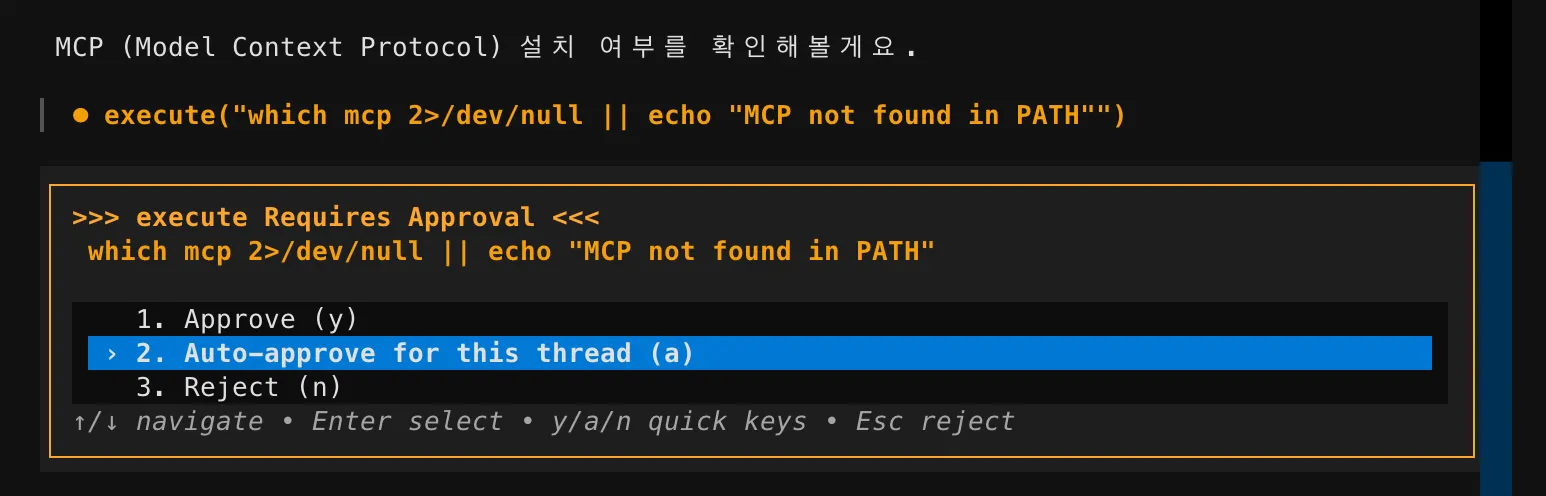
Approve(승인), Auto-approve(이 스레드에서 자동 승인), Reject(거절) — 세 가지 선택지를 제공합니다.
에이전트가 함부로 위험한 작업을 실행하지 못하도록 거절할 수도 있고, 반복 작업이 많을 때는 자동 승인으로 전환할 수도 있습니다.
이런 권한 제어 로직이 오픈소스에 포함되어 있다는 점이 꽤 인상적입니다.
Step 3. 모델 자유도 — 아무 LLM이나 연결
→ 공식 문서: docs.langchain.com — deepagents/customization · 지원 백엔드: deepagents/backends
Deep Agents가 Claude Code, Codex와 가장 다른 점이 여기 있습니다.
어떤 LLM 제공자든 연결할 수 있습니다.
# Anthropic Claude
agent = create_deep_agent(model="anthropic:claude-sonnet-4-6")
# OpenAI GPT-4o
agent = create_deep_agent(model="openai:gpt-4o")
# Google Gemini
agent = create_deep_agent(model="google:gemini-2.0-flash")
# Ollama (로컬, 인터넷 필요 없음)
agent = create_deep_agent(model="ollama:llama3.2")
# AWS Bedrock
agent = create_deep_agent(model="bedrock:anthropic.claude-3-5-sonnet")
포맷은 provider:model_id. 환경 변수만 맞게 세팅하면 모델 전환은 한 줄 변경이면 됩니다.
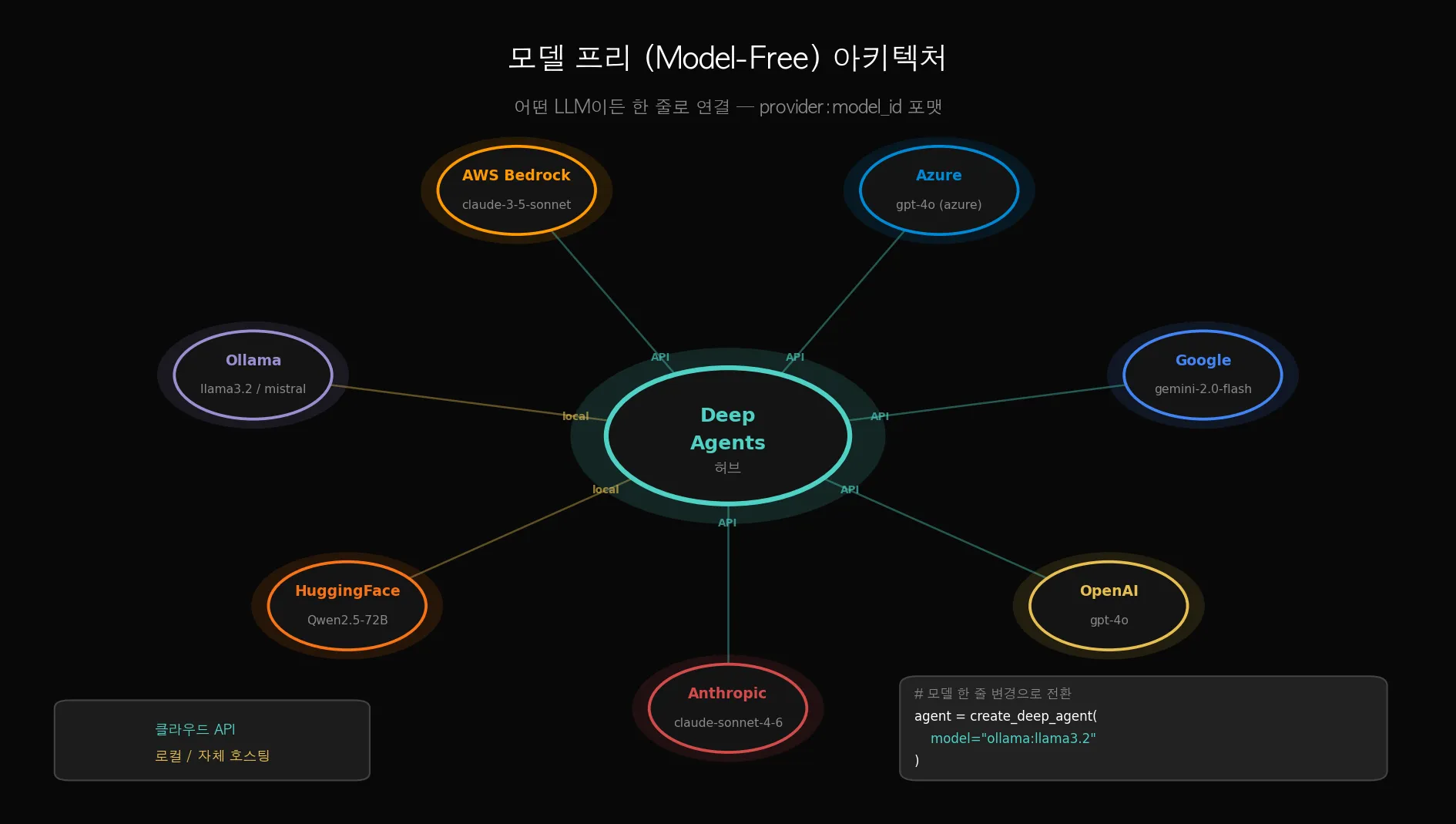
더 재밌는 건 오케스트레이터와 서브에이전트에 다른 모델을 쓸 수 있다는 점입니다.
예를 들어 메인 에이전트는 Claude Opus(정확도 우선), 빠른 서브작업은 Gemini Flash(속도 우선) 이런 식으로요.
비용과 성능을 작업 특성에 맞게 조합할 수 있습니다.
Step 4. 서브에이전트 — 작업을 나눠서 처리
→ 공식 문서: docs.langchain.com — deepagents/customization#subagents
단일 에이전트로 처리하기 복잡한 작업은 서브에이전트로 분할합니다.
각 서브에이전트는 격리된 컨텍스트에서 독립 실행됩니다.
# 리서치 특화 서브에이전트
research_agent = {
"name": "research-agent",
"description": "심층 분석이나 조사가 필요한 작업에 사용합니다",
"system_prompt": "당신은 전문 리서치 에이전트입니다.",
"tools": [], # 도구 없이 LLM 추론만
"model": "anthropic:claude-sonnet-4-6",
}
# 오케스트레이터 — 복잡한 요청을 받아 서브에이전트에 위임
orchestrator = create_deep_agent(
model="anthropic:claude-sonnet-4-6",
subagents=[research_agent],
system_prompt="""복잡한 작업은 research-agent에게 위임하고, 결과를 정리합니다.""",
)cap_subagent — 서브에이전트 위임 실행 흐름 캡처
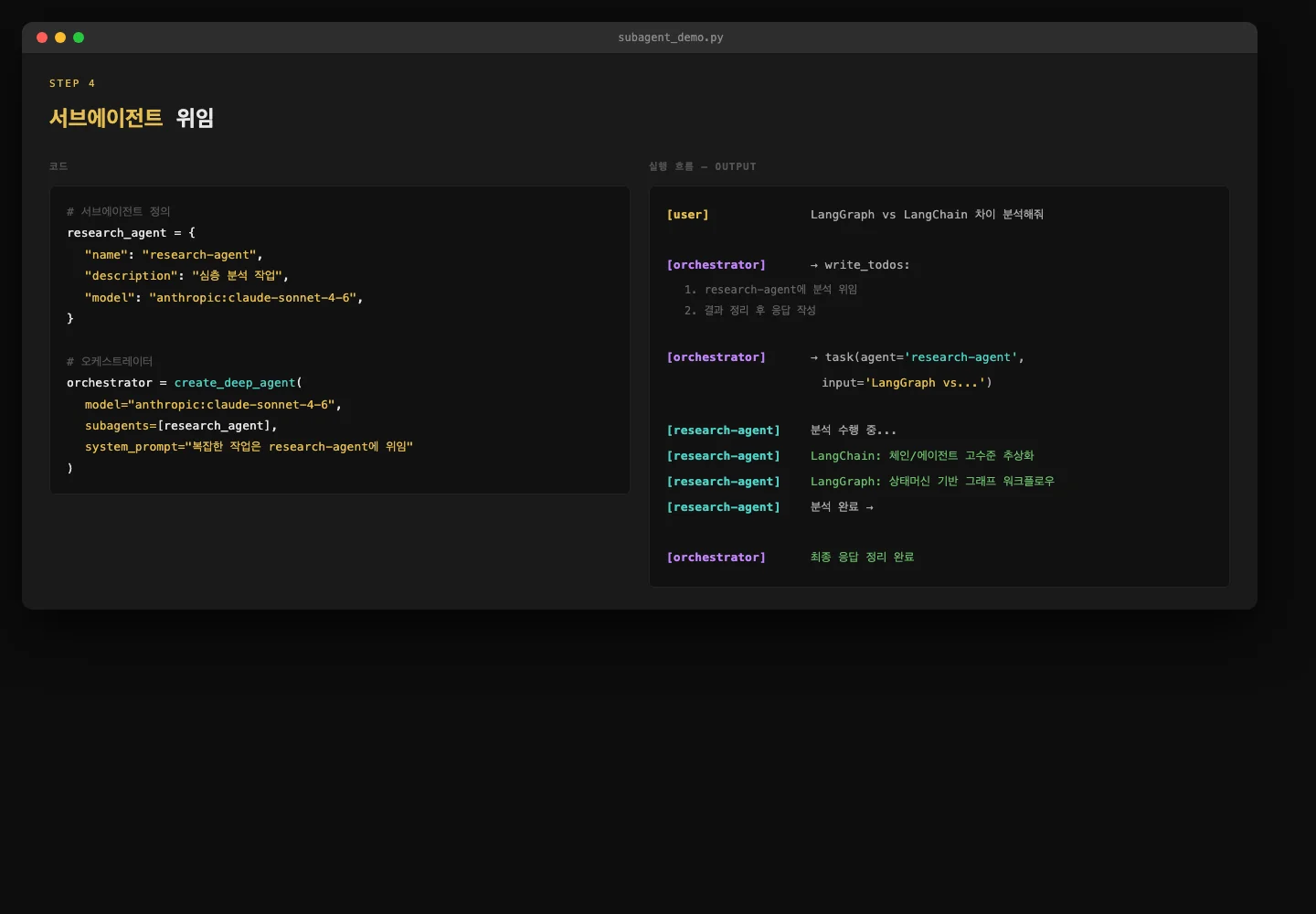
오케스트레이터는 먼저 write_todos로 작업 계획을 세운 뒤, task 도구로 서브에이전트를 호출합니다.
서브에이전트가 완료되면 결과를 받아 정리해 최종 응답을 만들어냅니다.
write_todos가 "아무것도 안 하는데" 왜 필요할까?
write_todos는 컨텍스트에 현재 작업 상태를 명시적으로 써두는 도구입니다.
모델이 "나는 지금 이걸 하고 있다"를 스스로 인식하게 해서 멀티스텝 작업에서 길을 잃지 않도록 합니다.
실제 실행 로그를 보면: pending → in_progress → completed 순으로 상태가 업데이트되면서 진행됩니다.
실제로 사용해 보면 이 todo 시스템이 꽤 전략적으로 동작합니다.
예를 들어 "playwright랑 g-search 등 외부 서치용 MCP 다운로드 받아줄래?" 같은 요청을 하면,
에이전트가 먼저 write_todos(3 items)로 작업 목록을 만들고 — Playwright MCP 서버 설치, Google Search MCP 서버 설치, MCP 서버 설정 확인 —
순서대로 하나씩 실행해 나갑니다.
단순히 명령 하나를 실행하는 게 아니라, 스스로 계획을 세우고 단계별로 진행하는 거라서 복잡한 작업일수록 체감되는 차이가 큽니다.
UX(User Experience, 사용자 경험) 측면에서도 잘 만들어져 있는데요 — 각 todo 항목이 done(완료), active(실행 중), todo(대기) 세 가지 상태로 실시간 표시됩니다.
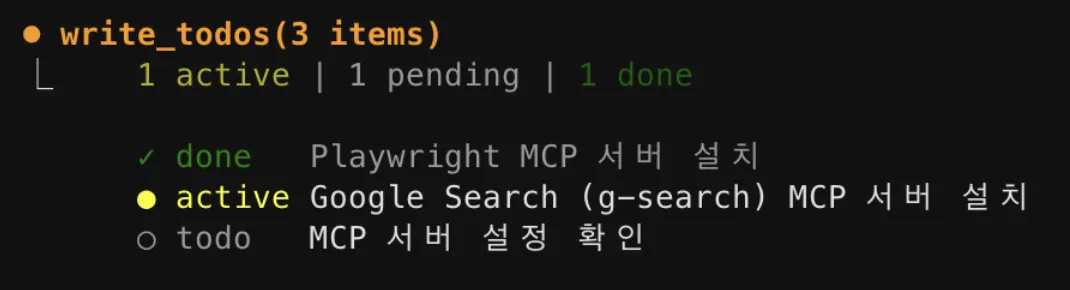
지금 에이전트가 뭘 하고 있고, 뭐가 끝났고, 뭐가 남았는지 한눈에 파악할 수 있어서
복잡한 멀티스텝 작업에서도 진행 상황을 놓치지 않을 수 있습니다.
오픈소스 CLI 도구에서 이 정도 UX가 나오는 건 솔직히 인상적입니다.
Step 5. 파일시스템 백엔드 — 6가지 옵션
→ 공식 문서: docs.langchain.com — deepagents/backends · 샌드박스: deepagents/sandboxes
에이전트가 파일을 읽고 쓰는 방식을 백엔드로 추상화했습니다.
상황에 따라 6가지 중 선택하면 됩니다.

가장 자주 쓰는 두 가지만 예시로 보면:
from deepagents.backends import FilesystemBackend
from langgraph.checkpoint.memory import MemorySaver
# 로컬 디렉토리에 실제로 파일 생성
agent = create_deep_agent(
backend=FilesystemBackend(root_dir="./workspace", virtual_mode=False),
checkpointer=MemorySaver(), # 세션 간 컨텍스트 유지
)
result = agent.invoke(
{"messages": [{"role": "user", "content": "hello.py 파일 만들어줘"}]},
config={"configurable": {"thread_id": "session-1"}} # 세션 ID
)
virtual_mode=False면 실제 로컬 파일시스템에 파일이 생성됩니다.
virtual_mode=True면 에이전트 상태 안에서만 파일이 존재하는 샌드박스 모드입니다.
샌드박스가 필요하면 Modal, Daytona, Runloop 같은 클라우드 샌드박스를 백엔드로 연결할 수도 있습니다.
코드 실행 환경을 격리하고 싶을 때 유용하죠.
Step 6. CLI — 설치부터 첫 실행까지
→ 공식 문서: docs.langchain.com — deepagents/cli/overview
SDK 말고 CLI도 있습니다. Claude Code처럼 터미널에서 대화형으로 바로 쓸 수 있습니다.
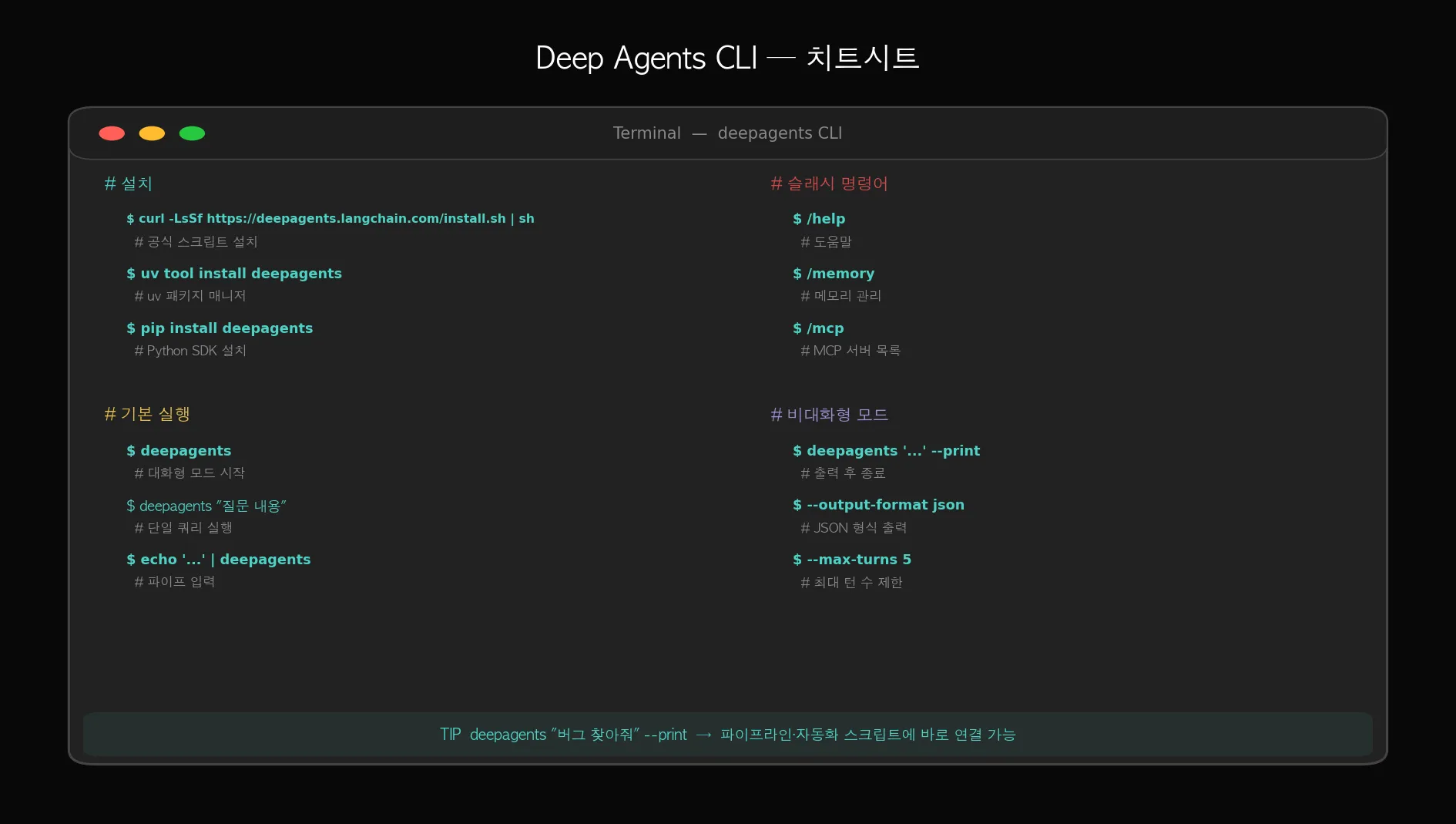
① 설치
# 기본 설치 (OpenAI 포함)
curl -LsSf https://raw.githubusercontent.com/langchain-ai/deepagents/refs/heads/main/libs/cli/scripts/install.sh | bash
# Anthropic, Ollama 등 추가 프로바이더 포함 설치
DEEPAGENTS_EXTRAS="anthropic,ollama" curl -LsSf https://raw.githubusercontent.com/langchain-ai/deepagents/refs/heads/main/libs/cli/scripts/install.sh | bash
# 또는 uv로 설치
uv tool install 'deepagents-cli[anthropic,ollama]'② API 키 설정
# Anthropic Claude 쓸 때
export ANTHROPIC_API_KEY="sk-ant-..."
# OpenAI GPT 쓸 때
export OPENAI_API_KEY="sk-..."
# Google Gemini 쓸 때
export GOOGLE_API_KEY="AIza..."
~/.zshrc 또는 ~/.bashrc에 넣어두면 매번 입력 안 해도 됩니다.
③ 첫 실행
# 대화형 모드로 시작
deepagents
# 모델 지정해서 시작
deepagents --model anthropic:claude-sonnet-4-6
deepagents --model openai:gpt-4o로컬 LLM(Ollama) 연결하는 법
인터넷 없이, API 비용 없이 로컬 모델 연결하는 방법입니다.
# 1. Ollama 설치 (ollama.ai에서 다운로드 후)
ollama serve # 별도 터미널에서 실행
# 2. 원하는 모델 다운로드
ollama pull llama3.2
ollama pull qwen2.5-coder # 코딩 특화
# 3. deepagents에서 연결
deepagents --model ollama:llama3.2API 키 없어도 됩니다. Ollama만 실행 중이면 끝.
슬래시 명령어 전체 목록
비대화형 모드(--print)로 CI/CD 파이프라인이나 쉘 스크립트에 바로 연결할 수도 있습니다.
# 단일 쿼리 (비대화형)
deepagents "이 디렉토리 Python 파일들 분석해줘" --print
# 파이프 연결
echo "버그 찾아줘" | deepagents --print
# JSON 출력 (자동화용)
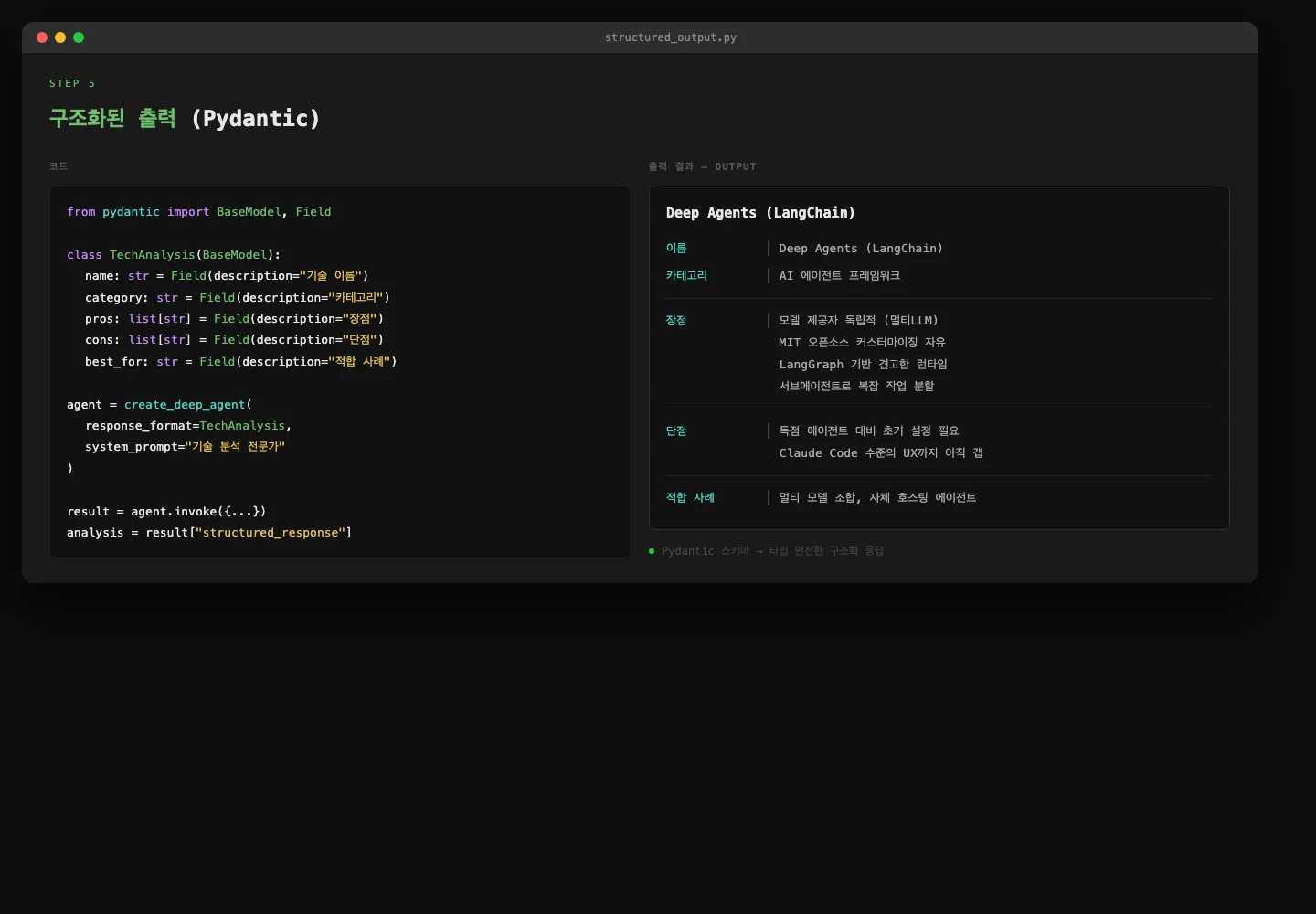
deepagents "요약해줘" --output-format json --printStep 7. 구조화된 출력 (Pydantic)
→ 공식 문서: docs.langchain.com — deepagents/customization#structured-output
응답을 JSON이 아닌 Pydantic 모델로 받을 수 있습니다.
에이전트를 API의 일부로 쓸 때 유용합니다.
from pydantic import BaseModel, Field
class TechAnalysis(BaseModel):
name: str = Field(description="기술/도구 이름")
category: str = Field(description="카테고리")
pros: list[str] = Field(description="장점 목록")
cons: list[str] = Field(description="단점 목록")
best_for: str = Field(description="가장 적합한 사용 사례")
agent = create_deep_agent(
response_format=TechAnalysis,
system_prompt="기술 분석 전문가입니다.",
)
result = agent.invoke({...})
analysis = result["structured_response"] # TechAnalysis 인스턴스
print(analysis.pros) # list[str]로 바로 접근cap_structured — 구조화된 출력 결과 캡처
로컬 LLM을 연결하면 어떻게 동작하나요?
백문이 불여일견. 직접 돌려봤습니다.
집에서 운영 중인 Mac Studio M1 Max (64GB)에 llama-server로 Qwen3.5-35B를 서빙하고,
맥북에서 deepagents로 연결했습니다.
(로컬 LLM 환경이 궁금하시면 [IT장비#1] 맥미니 대란? 나만의 AI 구축하기 편을 참고해 주세요!)
핵심은 deepagents 자체는 오케스트레이션만 담당하고, 실제 추론은 로컬 서버가 처리한다는 점입니다. 맥북 CPU 부하는 거의 0%.
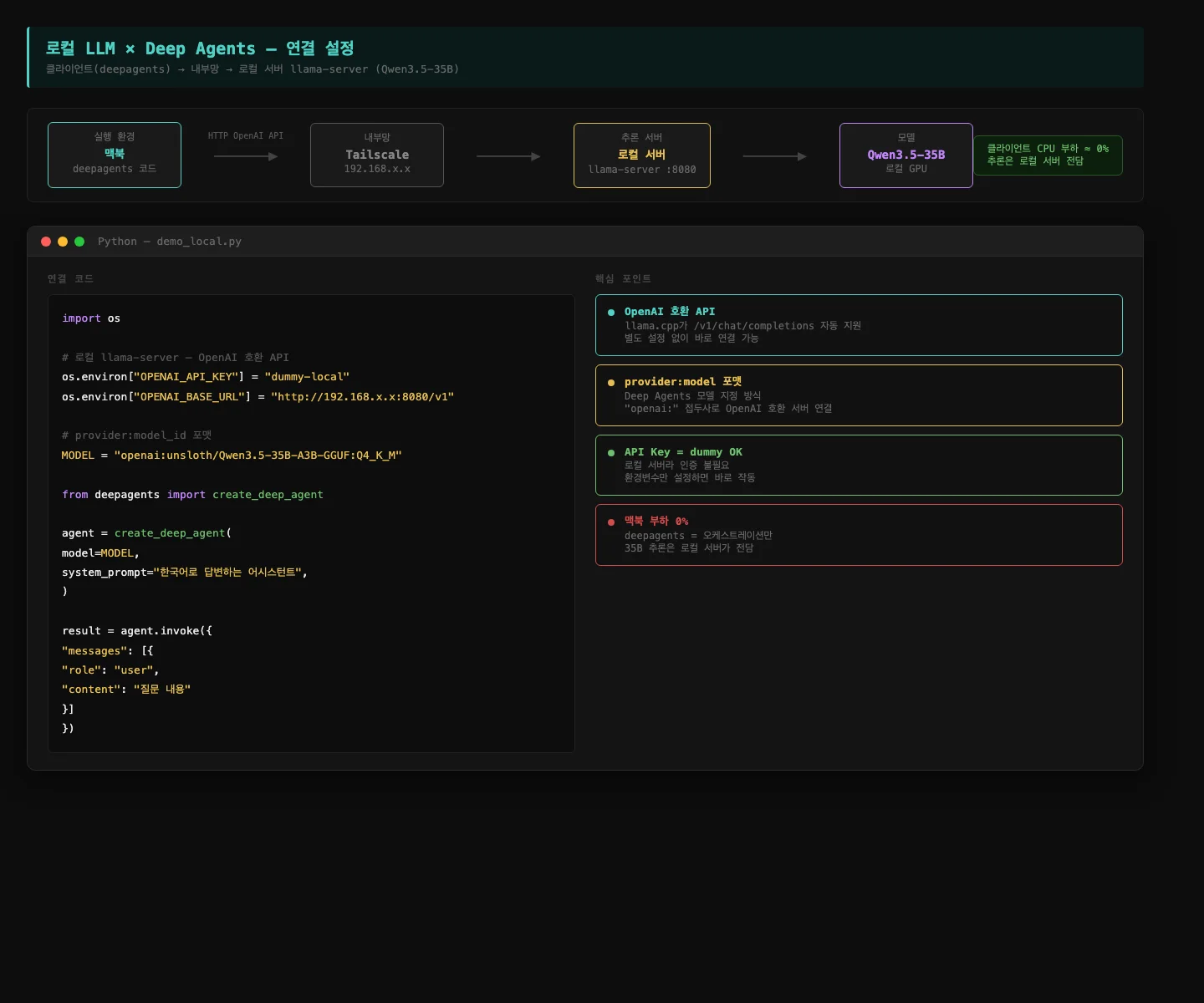
연결은 환경변수 두 줄이면 끝입니다. OPENAI_BASE_URL을 로컬 서버 주소로 바꾸고,
모델 ID에 openai: 접두사를 붙이면 deepagents가 해당 서버로 요청을 보냅니다.
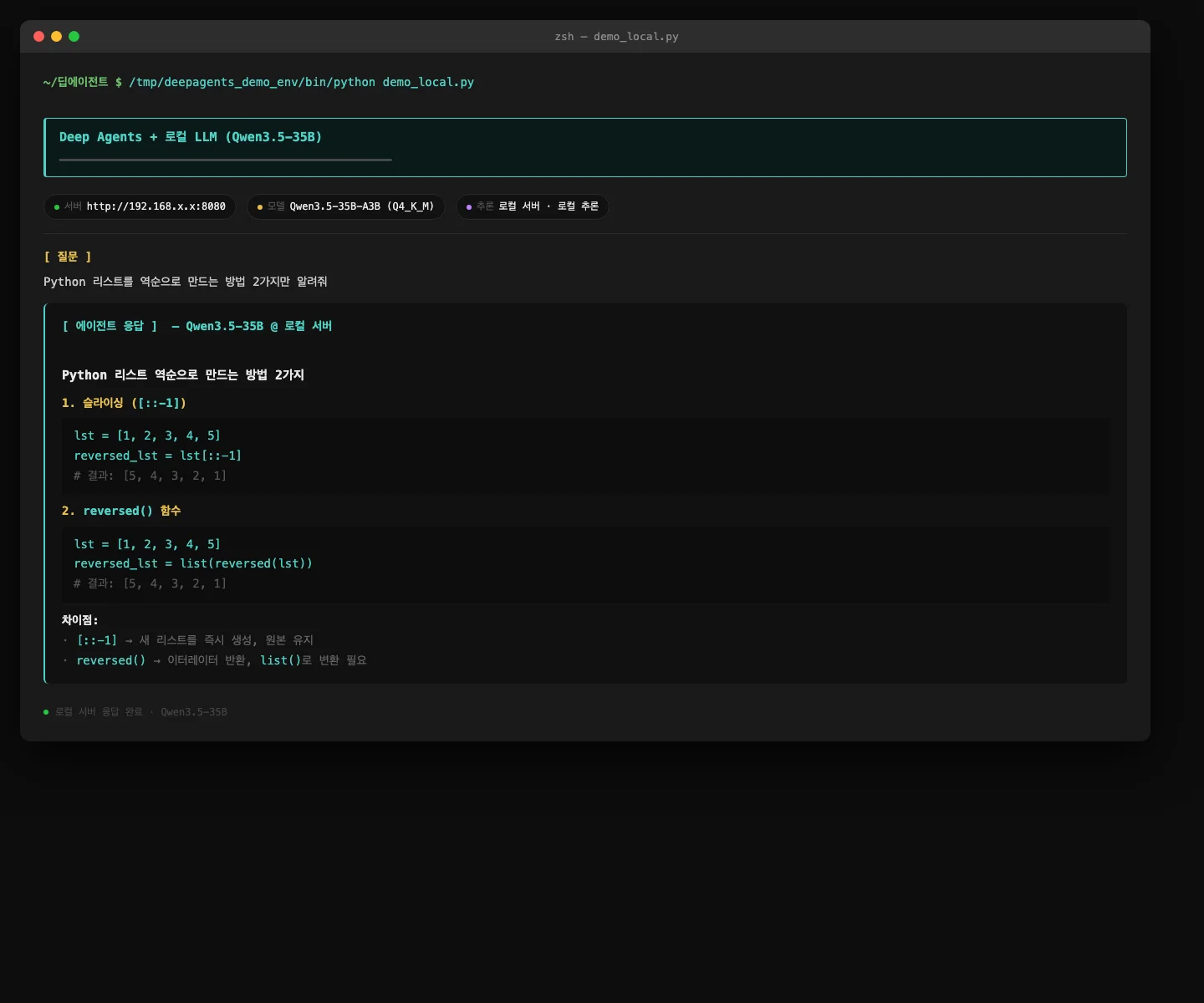
기본 에이전트로 Python 질문을 던졌습니다.
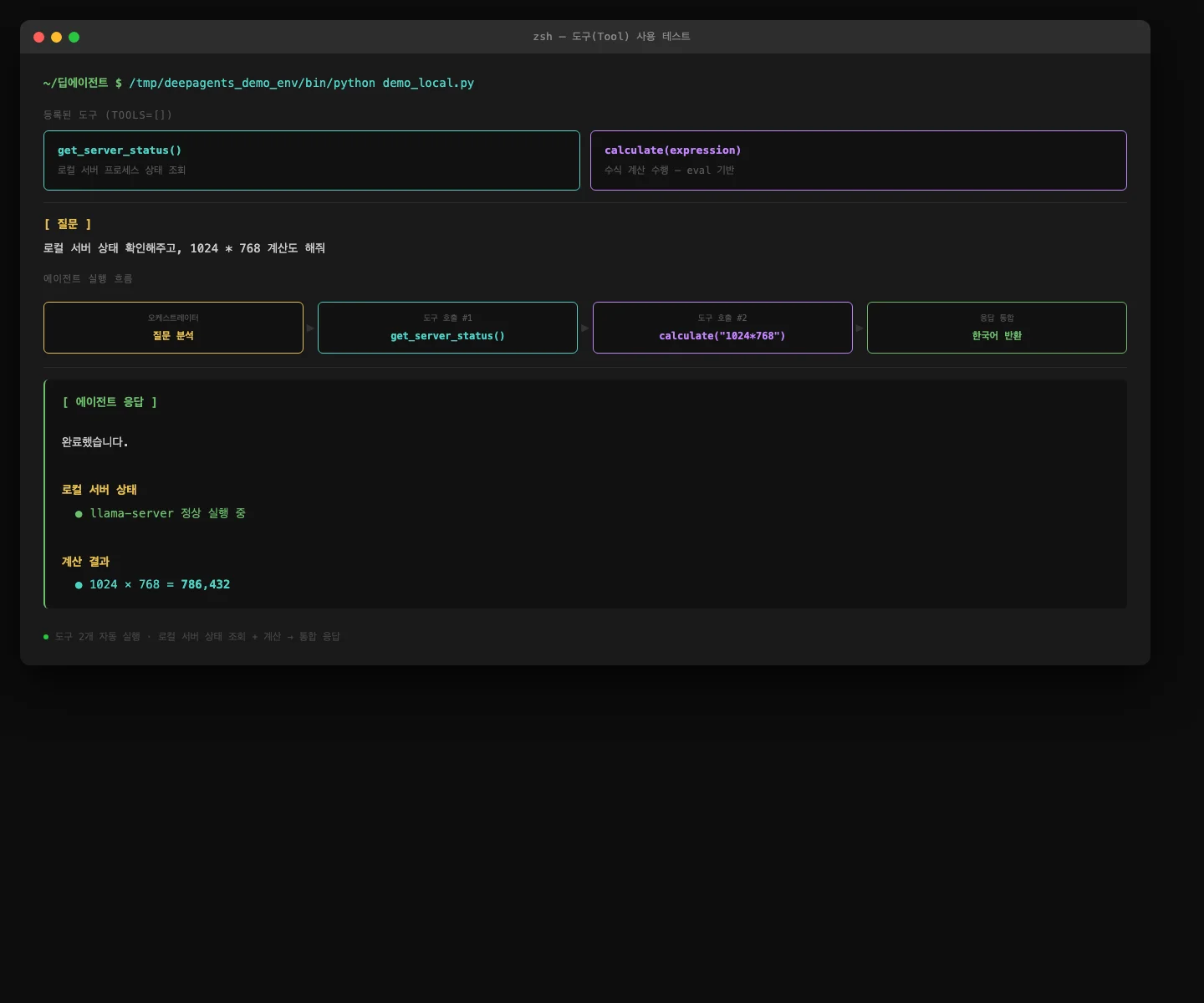
다음은 도구(Tool)까지 붙인 버전입니다.
get_server_status()로 서버 상태를 조회하고, calculate()로 수식을 계산했습니다.
두 도구를 자동으로 순서에 맞게 호출하고 결과를 통합해서 답변했습니다.
코딩 에이전트로도 바로 써볼 수 있습니다.
"사칙연산 계산기 짜고 테스트까지 해줘"라고 요청하면, Qwen3.5-35B가 calculator.py 작성 → 테스트 케이스 19개 생성 → 모두 통과까지 한 번에 처리합니다.
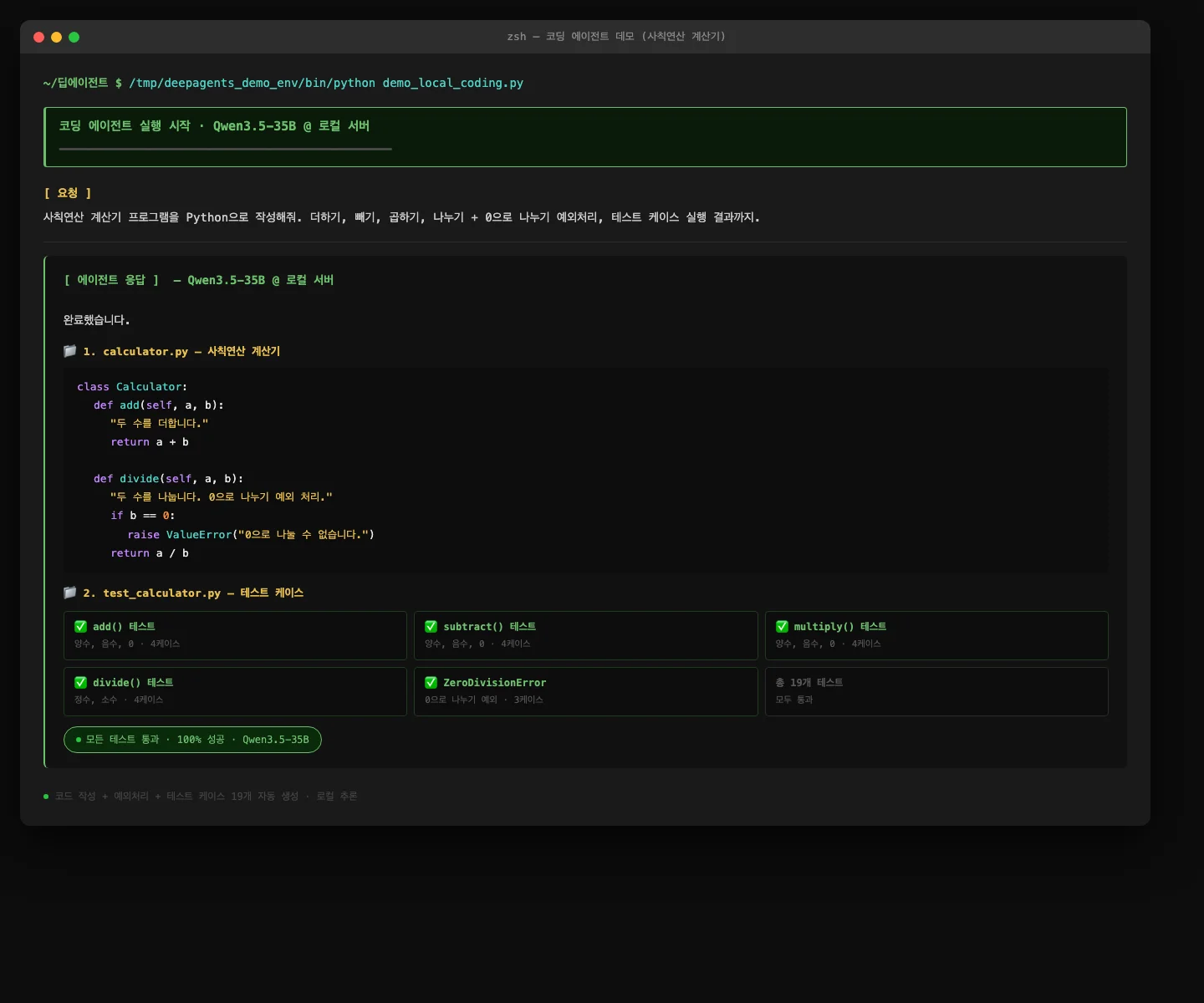
Anthropic API 없이, 인터넷 연결 없이, 완전 로컬에서 동작합니다. 모델만 바꾸면 OpenAI, Google, Azure, HuggingFace 어디든 같은 코드로 연결됩니다. 이게 "모델 프리" 설계의 실제 의미입니다.
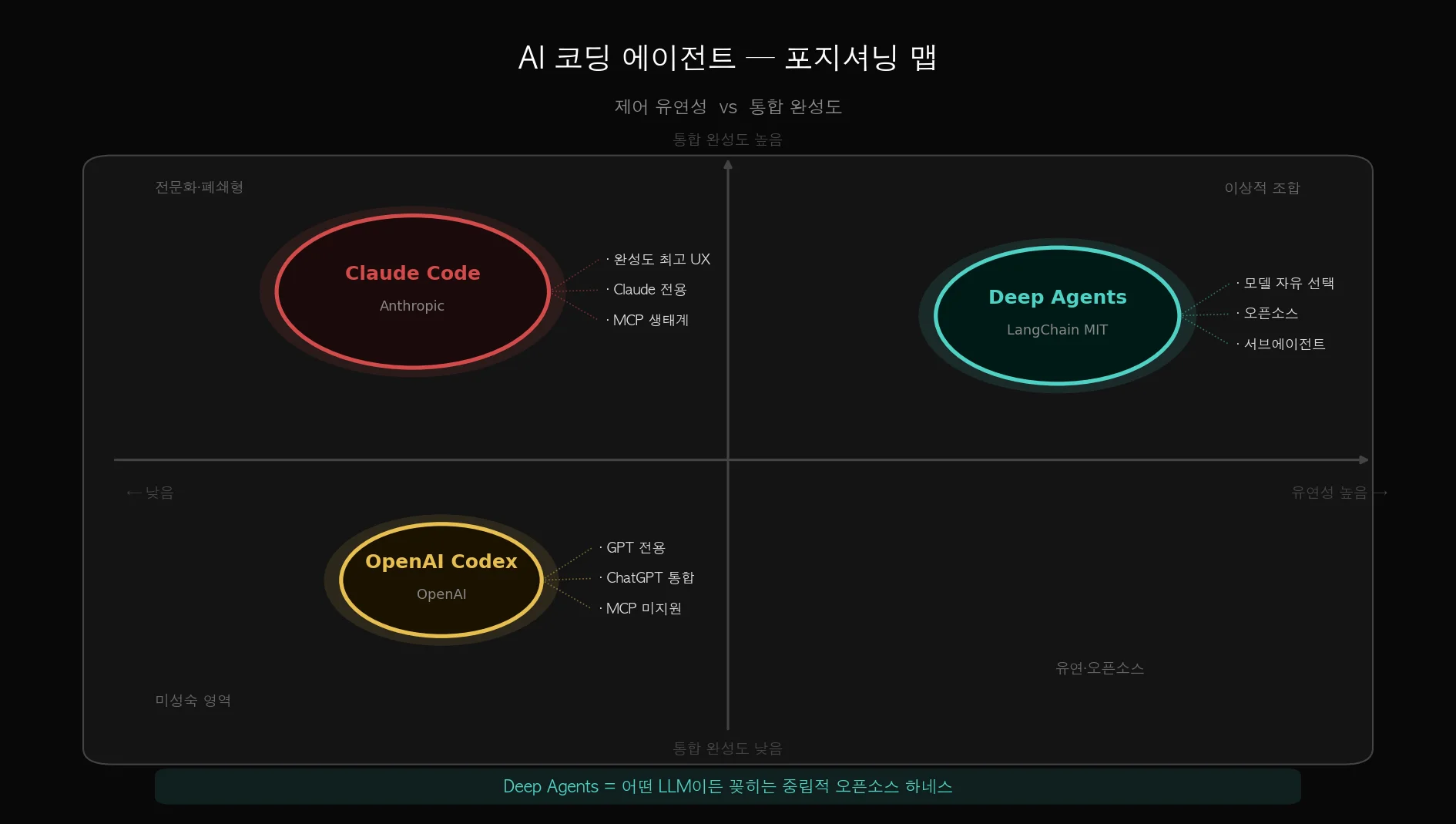
Step 8. Claude Code vs Deep Agents vs Codex — 3자 비교
→ 공식 비교 문서: docs.langchain.com — deepagents/comparison
공식 비교 문서를 기반으로 정리했습니다.

요약하면:
- Claude Code: 완성도 높은 UX, 클로드 생태계에 최적화, 가장 빠른 실용적 선택
- Deep Agents: 모델 자유도 + 오픈소스, 직접 호스팅 가능, 커스터마이징 최대
- OpenAI Codex: GPT 생태계에 통합, 장기 메모리·MCP 미지원(현재)
아키텍처가 Claude Code에서 영감을 받은 만큼, 기능적으로 상당히 유사한 수준까지 올라와 있습니다.
어떤 상황에서 뭘 쓰면 좋을까?
클로드 생태계에서 빠르게 시작하고 싶다 → Claude Code
모델을 자주 바꿔야 하거나 직접 호스팅이 필요하다 → Deep Agents
GPT 기반 ChatGPT 플러그인/API와 통합해야 한다 → OpenAI Codex
직접 써봤습니다
설치하고 바로 켜봤습니다. "Hello, world!" 한 마디에 "Hello." 로 받아쳤습니다.
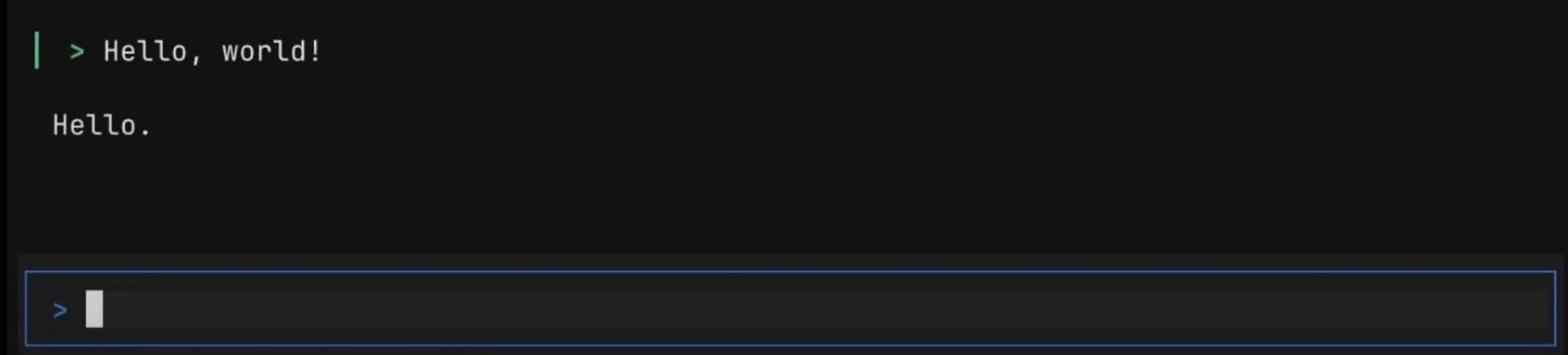
담백하죠. 이게 기본 상태입니다.
여기에 도구 붙이고, 모델 바꾸고, 서브에이전트 연결하면서 Claude Code 급으로 키워나가는 구조입니다.
정리 — 실무에서 어떻게 쓸까
Deep Agents가 적합한 3가지 시나리오입니다.
1. 모델 전환이 잦은 팀
비용 최적화로 OpenAI→Anthropic→Ollama를 왔다갔다해야 한다면, 에이전트 코드는 그대로 두고 모델 파라미터 한 줄만 바꾸면 됩니다.
2. 복잡한 멀티스텝 파이프라인
리서치 → 코딩 → 테스트 → 보고서 같은 파이프라인을 각 서브에이전트로 분업하면 각 단계를 전문화할 수 있습니다.
3. 자체 인프라에서 운영
MIT 라이선스라 상업적 사용에 제약이 없고, LangGraph 기반이라 이미 LangGraph를 쓰는 팀이라면 학습 곡선이 거의 없습니다.
주의할 점도 있습니다.
Deep Agents는 "모델을 신뢰하는" 설계 철학을 갖고 있습니다. 파일시스템 접근, 셸 실행 권한을 에이전트에 주기 때문에 운영 환경에서는 샌드박스 백엔드나 권한 제한을 반드시 설정해야 합니다.
로컬 개발이나 신뢰할 수 있는 환경에서는 문제없지만, 외부 입력이 들어오는 환경이라면 격리를 꼼꼼히 설정하세요.
아직 v0.4.x 단계라 API가 바뀔 수 있습니다.
이 글 쓰기 시작할 때 GitHub 스타가 9.9K였는데, 마무리할 때 다시 보니 12K를 넘어 있었습니다. 쓰는 지금 와중에도 다운로드 수가 올라가네요 ㅋㅋㅋ
그만큼 커뮤니티 반응이 빠르고, 관심이 뜨겁습니다.
Claude Code의 편의성은 아직 따라가기 어렵지만, 모델 자유도와 커스터마이징 면에서는 지금 당장 실용적으로 쓸 수 있습니다.
직접 써보고 싶다면 — GitHub에 전체 코드 공개돼 있습니다.
github.com/langchain-ai/deepagents — MIT License
다음 글에서는 Deep Agents에 Tavily 검색 도구를 붙여서 실제 리서치 에이전트를 만들어볼 예정입니다.