
[NLP 프로젝트 3편] AI 광고 카피 생성기 — 제품 하나로 스타일별 문구 자동 생성
1편은 분류, 2편은 요약. 이번엔 NLP의 마지막 단계 '생성'입니다. 제품명과 스타일만 넣으면 고급·친근·유머·직설 4가지 톤의 광고 카피를 자동으로 뽑아주는 도구를 만들었습니다. 모델을 새로 학습하는 게 아니라, 직접 만든 스타일 시드를 few-shot으로 Claude에 주입해서 톤을 잡는 방식입니다. Colab에서 그대로 따라 할 수 있습니다.
분류, 요약 다 했는데 — 이번엔 '생성'입니다
1편에서 BERT로 뉴스를 분류했고, 2편에서 KoBART로 요약까지 했습니다.
NLP 기술을 단계로 보면 이해(분류) → 압축(요약) → 창작(생성), 이렇게 흘러가거든요.
이번 3편은 마지막 단계 생성(generation)입니다.
근데 뉴스 생성은 좀 조심스럽더라고요. 가짜뉴스로 오해받을 수 있으니까요.
그래서 더 실용적이고 안전한 걸로 골랐습니다. 광고 카피 생성기요.
같은 제품도 톤(고급/친근/유머/직설)에 따라 카피가 완전히 달라지는데, 이걸 자동으로 뽑아봅니다.
제가 생각하는 핵심은, 모델을 새로 학습하지 않아도 된다는 점인 것 같습니다.
직접 만든 스타일 예시를 few-shot으로 Claude에 주입해서 톤을 잡아봤어요.
이렇게 하면 GPU나 며칠씩 걸리는 학습 없이도 되더라고요. API 키 하나면 시작할 수 있습니다.
이번 글은 좀 깁니다. 그래도 차근차근 따라오면, 마지막엔 제품명 한 줄만 넣어서
네 가지 톤의 카피를 만들어주는 작은 도구를 직접 만들어볼 수 있을 거예요. ㅎㅎ
이번 편이 1·2편과 다른 점: 1·2편은 Colab 무료 오픈소스 모델(BERT/KoBART)이었습니다.
3편은 생성 품질이 중요해서 Claude API를 씁니다. 무료 모델 대신 API 키가 필요해요(소액 과금, 뒤에서 비용도 따져봅니다).
같은 제품인데 카피가 왜 이렇게 다를까?
같은 제품이라도 노리는 고객과 상황에 따라 카피의 톤이 완전히 달라집니다. 고급형은 절제되고 우아하게, 친근형은 다정하게 권유하고, 유머형은 위트로 가볍게, 직설형은 스펙과 숫자를 바로 보여줍니다. 즉 광고 카피 생성은 '제품 정보'에 '스타일'이라는 변수를 더하는 문제입니다.
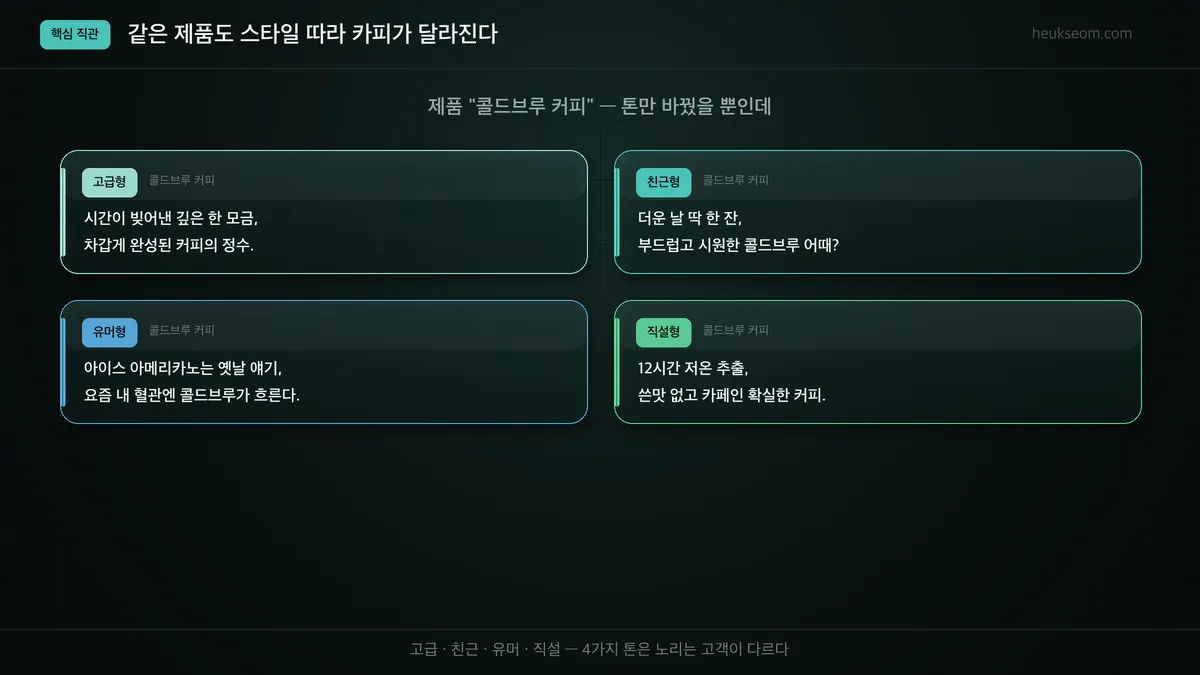
"콜드브루 커피" 하나를 예로 들어볼게요. 같은 커피인데 톤만 바꾸면 이렇게 됩니다.
- 고급형 — "시간이 빚어낸 깊은 한 모금, 차갑게 완성된 커피의 정수."
- 친근형 — "더운 날 딱 한 잔, 부드럽고 시원한 콜드브루 어때?"
- 유머형 — "아이스 아메리카노는 옛날 얘기, 요즘 내 혈관엔 콜드브루가 흐른다."
- 직설형 — "12시간 저온 추출, 쓴맛 없고 카페인 확실한 커피."
제품은 똑같은데 받는 느낌이 완전히 다르죠?
고급형은 백화점 명품관 느낌, 직설형은 마트 가격표 느낌, 유머형은 친구가 톡 보낸 느낌.
(같은 메뉴라도 호텔 레스토랑 메뉴판이랑 분식집 칠판이 말투가 다른 거랑 똑같아요.)
그래서 카피라이터들은 한 제품을 놓고도 톤을 여러 개 만들어둡니다.
인스타엔 가벼운 톤, 상세페이지엔 정보 톤, 이런 식으로 골라 쓰려고요.
우리가 만들 도구는 이 과정을 자동화하는 겁니다.
그래서 정확히 뭘 만드는 건가요?
우리가 만들 건 '제품 정보 × 스타일 → 카피'를 자동화하는 생성기입니다. 제품 정보는 고정해두고, 스타일을 4가지로 바꿔가며 각각에 맞는 카피를 한 번에 뽑아냅니다. 즉 입력은 제품명 하나, 출력은 스타일별 카피 4개입니다.
문제를 그림으로 정리하면 이렇게 됩니다.
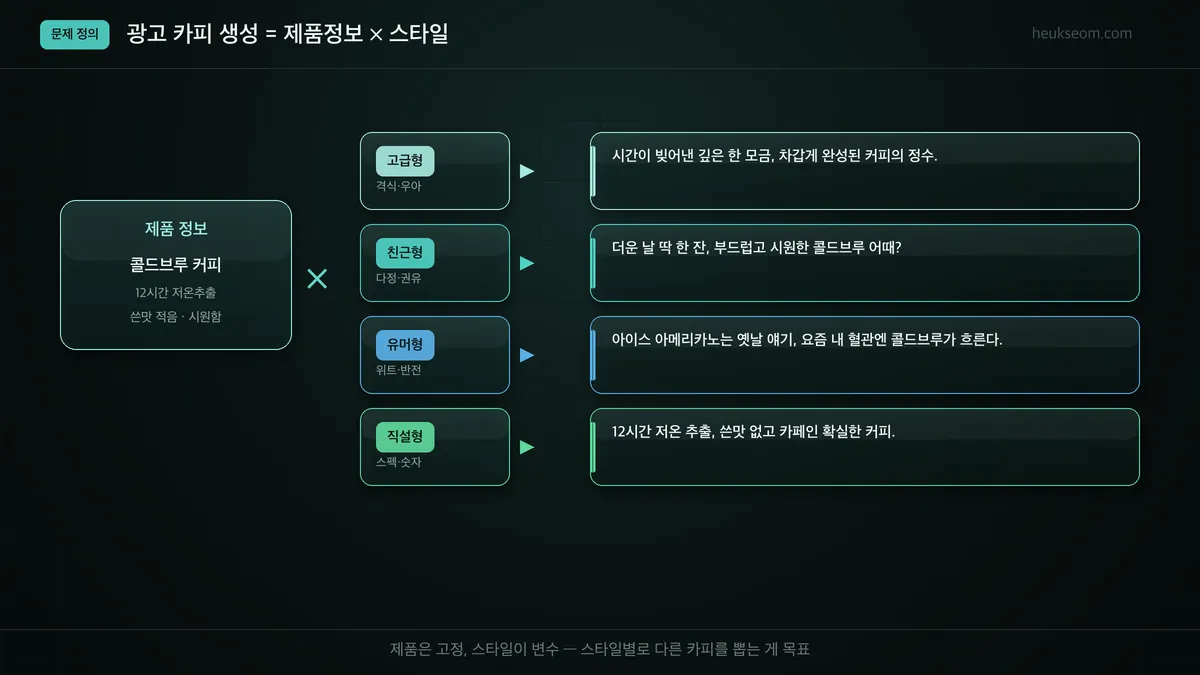
왼쪽 제품 정보는 고정값입니다. "콜드브루 커피, 12시간 저온추출, 쓴맛 적음" 같은 거죠.
가운데 스타일이 변수예요. 고급/친근/유머/직설 네 가지.
이 둘을 곱하면 오른쪽 카피 4개가 나옵니다.
여기서 우리가 풀어야 할 진짜 문제는 딱 하나입니다.
"스타일이라는 추상적인 걸 모델한테 어떻게 알려주지?"
"고급스럽게 써줘"라고 말로만 하면 모델마다, 실행할 때마다 해석이 달라지거든요.
이 문제를 푸는 게 이 글의 핵심이고, 답은 뒤에 나올 few-shot입니다.
스타일 카피 데이터는 어디서 모으나요?
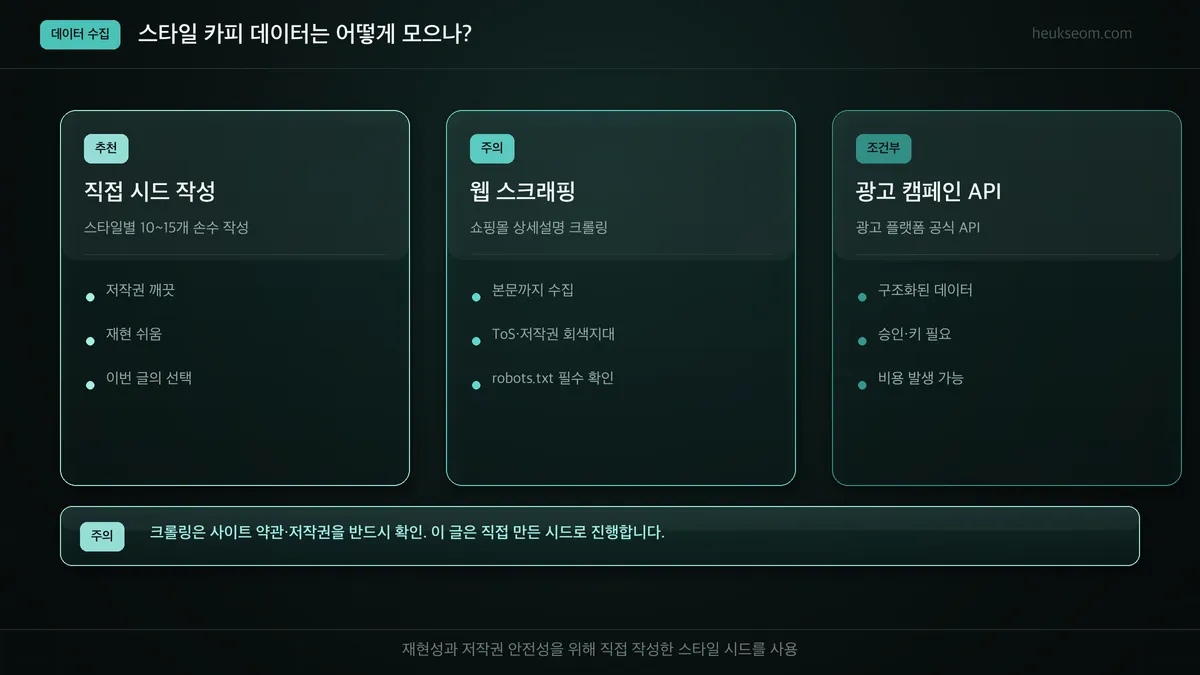
광고 카피 데이터는 직접 작성, 웹 스크래핑, 광고 캠페인 API 세 가지로 모을 수 있습니다. 다만 쇼핑몰 상세설명이나 광고 문구를 크롤링하는 건 사이트 약관과 저작권 문제가 걸리는 회색지대라, 이번 글에서는 저작권이 깨끗하고 재현이 쉬운 '직접 작성한 스타일 시드'를 사용합니다.
스타일을 모델한테 알려주려면, 먼저 "이게 그 스타일이야"라고 보여줄 예시가 필요합니다.
이 예시 데이터를 모으는 방법은 크게 세 가지예요.
직접 시드 작성은 스타일별로 카피 예시를 10~15개씩 손수 적는 방식입니다.
저작권 걱정이 없고 재현이 쉬워서, 이번 글은 이걸로 갑니다.
웹 스크래핑은 쇼핑몰 제품 상세설명 같은 걸 크롤링하는 방법인데요.
본문까지 수집할 수 있지만, 광고 문구는 저작물이라 함부로 긁으면 안 됩니다.
사이트 약관(ToS)과 robots.txt를 반드시 확인해야 하는 회색지대예요.
광고 캠페인 API는 광고 플랫폼이 공식 제공하는 API를 쓰는 방법입니다.
데이터가 구조화돼 있지만 승인·키 발급이 필요하고 비용이 들 수 있습니다.
(직접 작성은 내가 쓴 메모, 스크래핑은 남의 글 베끼기, API는 정식 계약하고 받아오는 거예요.)
저작권 주의: 남이 만든 광고 카피를 크롤링해서 그대로 학습/생성에 쓰면 저작권 분쟁 소지가 있습니다.
실전에서도 가능하면 공개 데이터셋이나 직접 만든 시드를 쓰는 걸 권합니다.
자, 이제 코드로 들어갑니다. 먼저 환경부터 깔아요.
Colab 새 노트북 열고 셀 0부터 순서대로 따라오면 됩니다.
Colab 실습 — 설치 + Claude 클라이언트 (셀 0)
!pip install anthropic -q
import os
from anthropic import Anthropic
# Colab에서는 키를 직접 넣거나 환경변수로 설정
os.environ['ANTHROPIC_API_KEY'] = 'sk-ant-...' # ← 본인 키 입력
client = Anthropic()
MODEL = 'claude-haiku-4-5' # 카피 생성 루프엔 가성비. 품질 ↑면 'claude-opus-4-8'anthropic 패키지를 설치하고 클라이언트를 만듭니다. API 키는 console.anthropic.com에서 발급받아요. 카피 생성은 짧은 출력을 여러 번 반복하는 작업이라, 비용 효율 좋은 claude-haiku-4-5를 기본으로 씁니다(모델 선택은 섹션 8에서 자세히).
Colab 실습 — 스타일 시드 데이터 (셀 1)
# 스타일별 카피 시드 — 직접 작성(저작권 깨끗)
style_seeds = {
'고급형': {
'설명': '절제되고 우아한 톤. 시간/장인정신/정수.',
'예시': [
{'제품': '프리미엄 만년필', '카피': '한 줄의 무게가 다른, 손끝에서 완성되는 격.'},
{'제품': '싱글몰트 위스키', '카피': '12년의 침묵이 빚어낸 깊이, 서두르지 않은 자만이 안다.'},
{'제품': '캐시미어 니트', '카피': '걸치는 순간 달라지는 온도, 절제된 우아함.'},
# ... 스타일당 10~15개
],
},
'친근형': { '설명': '다정하게 권유. ~어때?, ~해보세요.', '예시': [...] },
'유머형': { '설명': '위트/과장/반전. 일상 밈처럼.', '예시': [...] },
'직설형': { '설명': '스펙/숫자/혜택을 바로 명시.', '예시': [...] },
}스타일마다 '설명'(톤 정의)과 '예시'(few-shot에 넣을 카피들)를 둡니다. 예시 제품은 일부러 다양하게 — 모델이 '제품'이 아니라 '톤'을 배우게 하려는 겁니다. 만년필·위스키·니트는 다 다른 제품이지만 톤은 똑같이 '고급'이잖아요.
맨 프롬프트랑 few-shot이 왜 그렇게 차이 나나요?
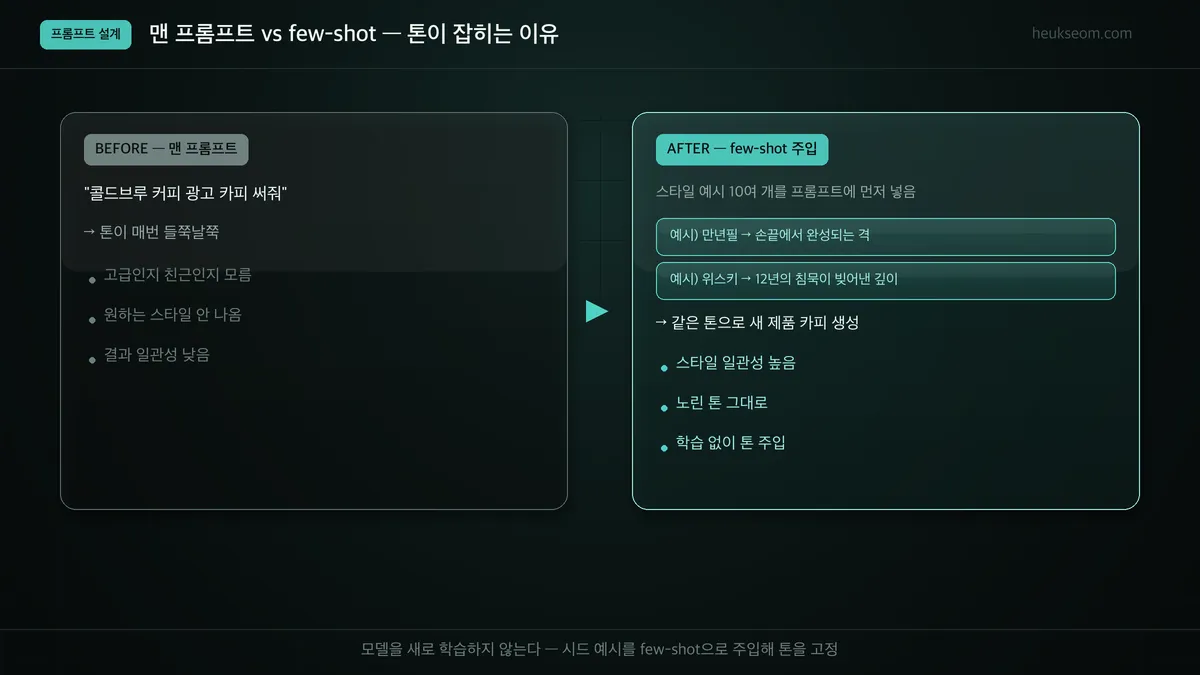
"콜드브루 커피 카피 써줘" 같은 맨 프롬프트는 톤이 매번 들쭉날쭉합니다. 모델이 고급인지 친근인지 알 방법이 없으니까요. 반면 스타일 예시 10여 개를 프롬프트에 먼저 넣어주는 few-shot 방식은, 그 톤을 그대로 흉내 내서 새 제품에도 일관된 스타일의 카피를 만들어냅니다. 모델을 새로 학습하지 않고도 톤을 고정하는 방법입니다.
맨 프롬프트로 "콜드브루 커피 광고 카피 써줘"라고만 하면, 결과 톤이 매번 달라져요.
어떤 날은 고급스럽게, 어떤 날은 가볍게. 일관성이 없습니다.
대신 스타일 시드를 few-shot 예시로 프롬프트에 먼저 깔아주면 얘기가 달라집니다.
"이런 톤의 카피들이야 → 같은 톤으로 콜드브루 카피 써줘" 하면, 그 톤을 그대로 따라옵니다.
(시 몇 편 보여주고 "이런 느낌으로 한 편 써줘" 하는 거랑 똑같아요. 예시가 톤을 정해주는 거죠.)
여기서 잠깐. few-shot이 학습(fine-tuning)이랑 뭐가 다른가요?
학습은 모델 가중치를 바꾸는 거라 데이터 수천 건 + GPU + 시간이 필요합니다.
few-shot은 가중치를 안 건드려요. 그냥 매 요청마다 예시를 같이 보내서 "이번엔 이 톤으로" 하고 알려주는 거예요.
비용도 싸고 즉시 바꿀 수 있어서, 톤 몇 개 잡는 정도엔 few-shot이 훨씬 실용적입니다.
Colab 실습 — few-shot 프롬프트 조립 (셀 2)
def build_fewshot(style):
# 스타일 시드를 few-shot 텍스트 블록으로 조립
block = style_seeds[style]
lines = [f"# 스타일: {style} — {block['설명']}", "# 예시:"]
for ex in block['예시']:
lines.append(f"- 제품: {ex['제품']} → 카피: {ex['카피']}")
return "\n".join(lines)
print(build_fewshot('고급형'))스타일 예시들을 "제품 → 카피" 형태로 죽 나열한 텍스트를 만듭니다. 이게 프롬프트 앞에 깔리면서 톤을 잡아주는 핵심 역할을 합니다.
Colab 실습 — 카피 생성 함수 (셀 3)
SYSTEM = ("너는 한국어 광고 카피라이터다. 주어진 스타일 예시의 톤을 그대로 살려, "
"제품에 맞는 카피를 딱 한 줄만 쓴다. 설명/따옴표 없이 카피만 출력한다.")
def make_copy(product, style):
fewshot = build_fewshot(style)
user = f"{fewshot}\n\n# 위 톤으로 아래 제품 카피를 한 줄.\n제품: {product}\n카피:"
resp = client.messages.create(
model=MODEL,
max_tokens=120,
system=SYSTEM,
messages=[{'role': 'user', 'content': user}],
)
return resp.content[0].text.strip()
print(make_copy('콜드브루 커피', '고급형'))시스템 프롬프트로 역할을 정하고, few-shot 블록 + 제품을 user 메시지로 보냅니다. max_tokens=120은 한 줄 카피엔 충분해요. claude-haiku-4-5로 돌리면 위처럼 고급형 톤의 카피가 한 줄 나옵니다.
few-shot 예시는 몇 개나 넣어야 하나요?
스타일당 예시가 많을수록 톤이 안정됩니다. 예시가 0~3개로 적으면 톤이 흔들리고, 8개를 넘어가면 거의 안정 구간에 들어갑니다. 실용적으로는 스타일당 10~15개면 충분하고, 그 이상은 효과가 완만해지면서 프롬프트만 길어집니다.
"예시 몇 개가 적당해?"는 few-shot에서 제일 많이 나오는 질문이에요.
예시를 늘려가며 톤 일관성을 재보면 대략 이런 곡선이 나옵니다.
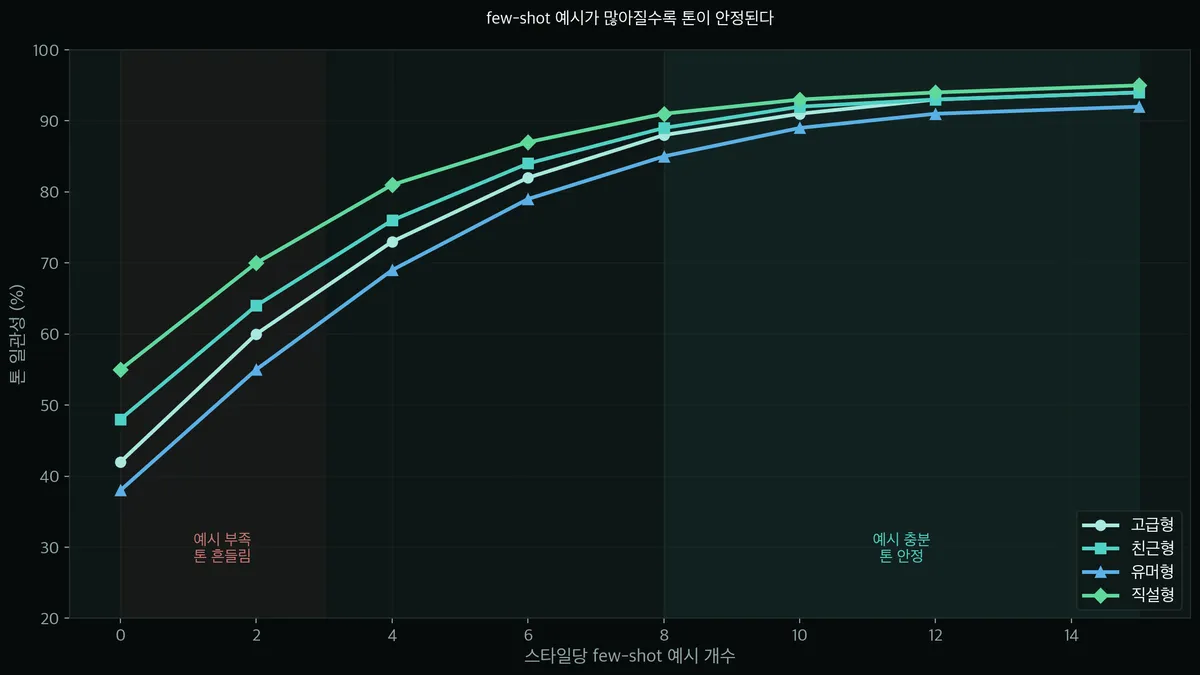
사실 저도 처음엔 스타일당 예시를 3개만 넣고 돌렸는데, 톤이 매번 바뀌어서 좀 헤맸어요.
예시를 10개 가까이 늘리고 나서야 톤이 잡히더라고요. 곡선을 보면 패턴이 똑같습니다. 처음엔 가파르게 올라가다가, 8~10개쯤에서 완만해집니다.
예시 2~3개로는 톤이 들쭉날쭉(빨간 구간), 10개 넘으면 거의 안정(민트 구간)이에요.
(처음 몇 장만 봐도 분위기 파악은 되지만, 여러 장 봐야 확실히 감 잡는 거랑 비슷해요.)
그래서 권장은 스타일당 10~15개입니다.
더 넣어도 일관성은 1~2%p 오를까 말까인데, 프롬프트가 길어져서 비용·속도만 나빠져요.
유머형이 제일 늦게 안정되는 것도 보이죠? 위트는 톤 잡기가 원래 까다롭거든요.
제품명 하나로 4가지 스타일을 한 번에 뽑으려면?
스타일 하나를 생성하는 make_copy 함수를 스타일 리스트로 감싸면, 제품명 한 줄만 넣어도 고급·친근·유머·직설 4가지 카피가 한 번에 나옵니다. 이게 전체 파이프라인의 마지막 조립 단계입니다.
스타일 하나씩 만드는 건 됐으니, 이제 4가지를 한 번에 돌려봅시다.
앞에서 만든 make_copy()를 스타일 리스트로 감싸기만 하면 됩니다.

그림처럼 입력(제품명+스타일) → 조립(few-shot) → 생성(Claude) → 출력(카피 4안)으로 흐릅니다.
2편에서 만든 뉴스 파이프라인이랑 구조가 똑같아요. 단계만 다를 뿐이죠.
Colab 실습 — 4스타일 동시 생성 (셀 4)
STYLES = ['고급형', '친근형', '유머형', '직설형']
def generate_all(product):
return {s: make_copy(product, s) for s in STYLES}
import pandas as pd
res = generate_all('콜드브루 커피')
pd.DataFrame(res.items(), columns=['스타일', '카피'])generate_all('콜드브루 커피') 한 줄이면 4가지 스타일 카피가 전부 나옵니다. 딕셔너리 컴프리헨션으로 스타일마다 make_copy를 호출할 뿐이에요. 스타일마다 톤이 확실히 다른 게 보이죠.
스타일마다 톤이 정확히 어떻게 다른가요?
스타일별 카피를 격식도·감정표현·정보량·위트·문장길이 같은 축으로 뜯어보면 성격이 뚜렷하게 갈립니다. 고급형은 격식이 높고 위트가 낮고, 유머형은 위트가 압도적이고, 직설형은 정보량이 높고 감정이 낮습니다. 친근형은 감정표현이 가장 높습니다.
"고급형이랑 직설형이 다르다"는 건 느낌으로 알지만, 막상 뭐가 다른지 말로 하긴 애매하죠.
생성된 카피들을 몇 가지 축으로 점수 매겨서 레이더 차트로 그려봤습니다.
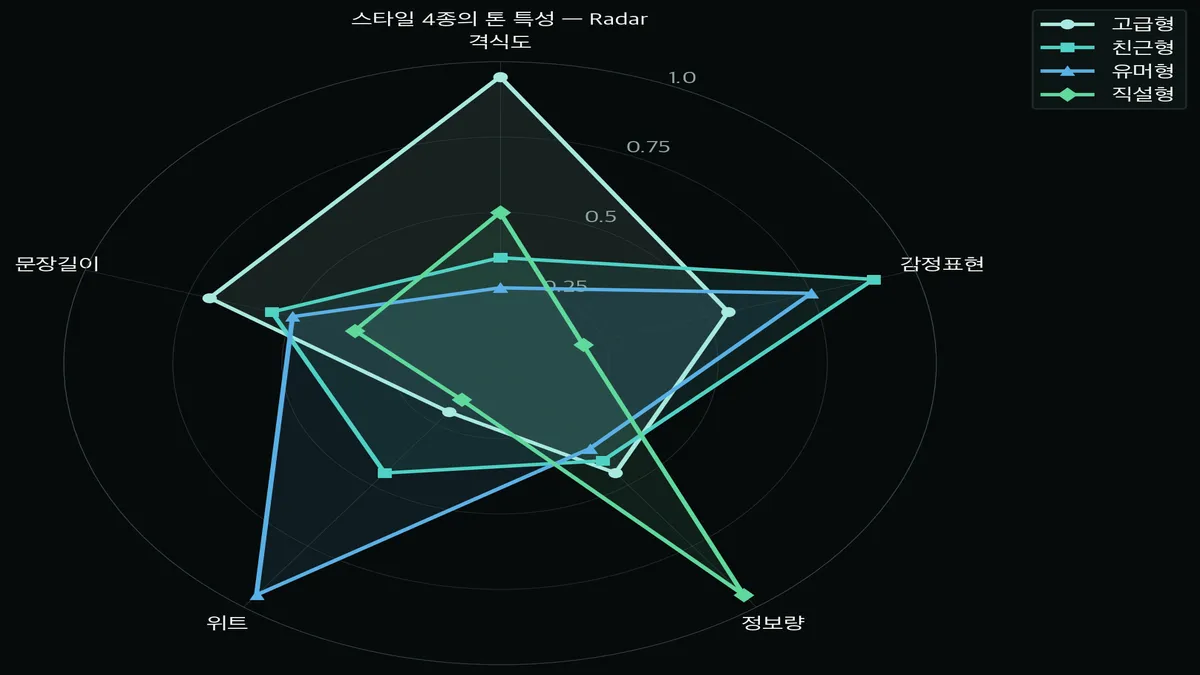
모양이 확실히 갈리죠?
- 고급형(금색) — 격식도가 꼭짓점, 위트는 바닥. 길고 우아한 문장.
- 친근형(민트) — 감정표현이 제일 높음. 다정하게 말 거는 톤.
- 유머형(빨강) — 위트가 압도적. 대신 격식·정보량은 낮음.
- 직설형(파랑) — 정보량이 꼭짓점, 감정은 바닥. 짧고 사실 위주.
이렇게 모양이 안 겹친다는 건, few-shot이 톤을 제대로 분리했다는 뜻이에요.
네 개가 다 비슷한 모양이었으면 스타일 구분이 실패한 거죠.
어떤 모델을 써야 하나요? (비용 vs 품질)
카피 생성처럼 짧은 출력을 많이 반복하는 작업은 가성비 모델(Haiku)로 충분합니다. 카피 1,000개를 뽑아도 Haiku는 약 0.27달러, Opus는 1.35달러로 5배 차이가 나고, 속도도 Haiku가 2배 이상 빠릅니다. 품질 차이가 결정적인 작업이 아니라면 Haiku로 시작해서 필요할 때만 상위 모델로 올리는 게 좋습니다.
Claude에는 여러 모델이 있어요. 빠르고 싼 Haiku, 균형 잡힌 Sonnet, 제일 똑똑한 Opus.
카피 생성에 어떤 걸 쓸지 비용이랑 속도로 따져봤습니다.
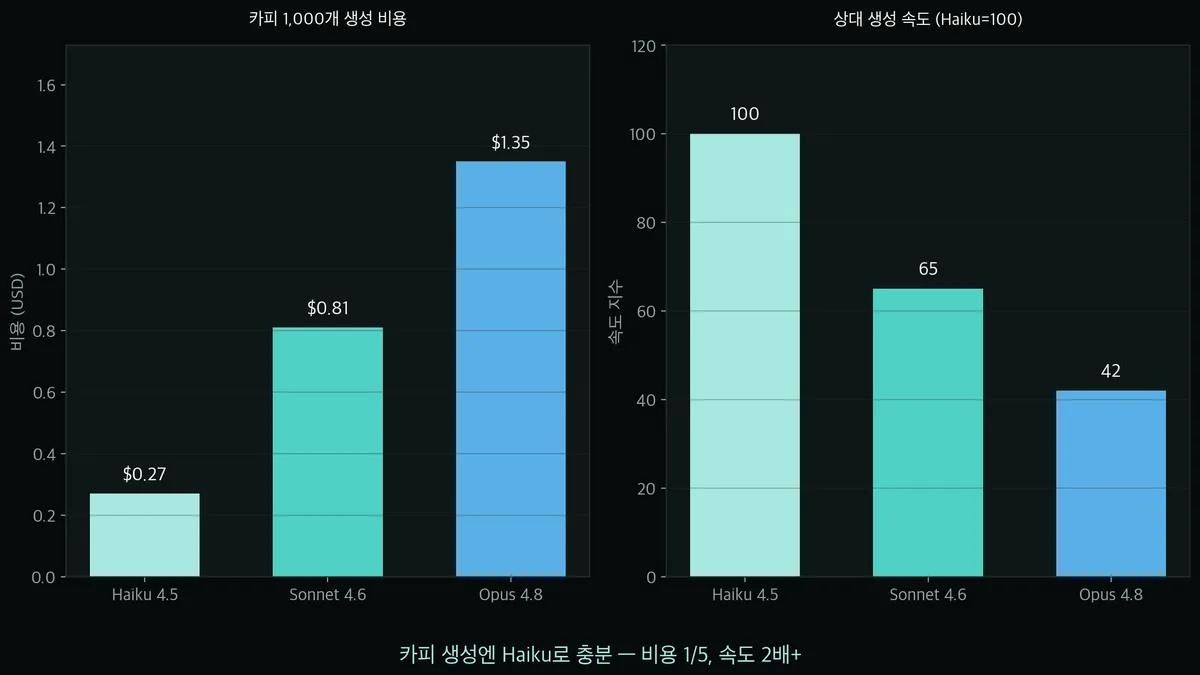
카피 한 개는 입력 약 120토큰(few-shot 포함), 출력 약 30토큰밖에 안 됩니다.
그래서 1,000개를 뽑아도 Haiku는 0.27달러로, 커피 한 잔 값도 안 됩니다. ㅋㅋ
Opus는 1.35달러로 5배. 속도도 Haiku가 가장 빠릅니다.
카피는 어차피 사람이 보고 고르는 거라, 양을 많이 뽑아 고르는 게 유리합니다.
그래서 기본은 Haiku로 많이 뽑고, "이 제품은 톤이 진짜 중요하다" 싶을 때만 Opus로 올리면 됩니다.
코드에서 MODEL 한 줄만 바꾸면 되니까 부담도 없고요.
흑섬 게코로 직접 돌려보면 어떻게 나오나요?
제품명만 키우는 개체로 바꿔도, 일반 제품과 똑같이 스타일별 카피가 나옵니다. 같은 게코 한 마리라도 고급형은 차분한 소개글, 유머형은 가벼운 SNS용으로 톤이 갈립니다. 시드는 그대로 두고 제품명만 바꿔 끼우면 됩니다.
일반 제품은 잘 되니까, 이번엔 제가 키우는 게코로도 한번 돌려봤습니다. ㅎㅎ
제품명만 "흑섬 블랙나이트 레오파드게코"로 바꿔서 돌려봤어요.
Colab 실습 — 흑섬 게코 카피 생성 (셀 5)
for style, copy in generate_all('흑섬 블랙나이트 레오파드게코').items():
print(f'[{style}] {copy}')코드는 셀 4랑 똑같고 제품명만 바꿨어요. 시드를 우리 브랜드 톤으로 더 다듬으면 결과도 더 정교해집니다.

같은 개체인데 톤이 확 다르죠. 고급형은 차분한 소개글에, 유머형은 짧은 SNS 영상 자막에 어울릴 것 같아요.
친근형 "데려가세요!" 같은 건 솔직히 좀 오글거려서 그대로는 안 쓸 것 같지만, 톤 방향 잡는 출발점으론 충분했습니다. ㅋㅋ
카피 고민하는 시간이 확 줄어듭니다.
채널마다 어떤 스타일을 골라 써야 하나요?
한 제품을 4스타일로 뽑아두면, 글의 성격에 맞게 골라 쓰기만 하면 됩니다. SNS 피드·스토리에는 친근형·유머형, 블로그나 상세 설명에는 직설형·고급형이 잘 맞는 것 같습니다. 글마다 노리는 효과가 다르기 때문입니다.
카피를 4개 뽑아놨으니, 이제 어디에 뭘 쓸지만 정하면 됩니다.
우리 채널들에 맞춰 정리하면 이렇게 돼요.

SNS는 스크롤하다 멈추게 해야 하니 가볍고 재밌는 친근형·유머형.
블로그나 상세 설명은 정보랑 신뢰가 중요하니 직설형·고급형.
차분하게 소개하고 싶을 땐 고급형이 1순위가 되고요.
핵심은, 한 번 4스타일로 뽑아두면 채널마다 다시 고민할 필요가 없다는 거예요.
골라 쓰기만 하면 되니까요.
코드 없이 빠르게 써보고 싶다면? (claude -p)
Python 코드까지 가기 전에, 터미널에서 claude -p 명령 한 줄로 카피를 바로 받아볼 수 있습니다. Claude Code CLI가 설치돼 있으면 API 키 없이도 동작해서, "이 톤 괜찮나?"를 빠르게 확인할 때 좋습니다.
본격적인 자동화 전에, 감 잡는 용도로 딱 좋은 방법이 하나 더 있어요.
Claude Code CLI가 깔려 있으면 claude -p로 터미널에서 바로 카피를 받습니다.
터미널 실습 — claude -p 한 줄 맛보기
claude -p '제품 "콜드브루 커피"의 광고 카피를 고급스러운 톤으로 한 줄만.'설치(claude.ai/code)와 로그인만 돼 있으면 API 키 없이도 한 줄로 생성됩니다. 본격적인 자동화는 위의 Python(SDK) 방식이 낫고, 이건 빠른 확인용입니다.
실제로 돌려보니 뭐가 좋고 뭐가 아쉬웠나요?
직접 만들어 돌려보니 장단점이 같이 보이더라고요.
잘 된 점:
- 학습이 전혀 없습니다. 시드만 바꾸면 톤이 바로 바뀌어요.
- 스타일별 톤 구분이 확실합니다. 레이더 차트로 봤듯이 4종이 안 겹쳐요.
- 제품을 바꿔도(커피 → 게코) 톤이 그대로 유지됩니다.
- Haiku로 돌리면 비용이 거의 안 듭니다. 카피 1,000개에 커피 한 잔 값도 안 돼요.
아쉬운 점:
- 시드 품질이 곧 결과 품질입니다. 예시가 어설프면 카피도 어설퍼져요.
- 같은 입력이라도 생성 결과가 매번 조금씩 달라집니다(LLM 특성).
- API 호출당 소액이지만 비용이 듭니다. 무료 모델이던 1·2편과 다른 점이에요.
- 스타일이 4개로 고정. 새 톤을 추가하려면 시드를 새로 써야 합니다(어렵진 않아요).
개선 방향:
- A/B 테스트로 반응 좋은 톤을 추려서 시드를 보강할 수 있습니다.
- 브랜드 전용 시드를 따로 만들면 우리 톤으로 고정됩니다.
- 이미지·해시태그 생성까지 붙이면 제품명 하나로 게시물 한 세트가 나옵니다.
- Streamlit로 입력창을 붙이면 비개발자도 제품명만 넣고 쓸 수 있어요.
정리
이번 글에서 다룬 핵심만 짧게 정리해봅니다.
- NLP 기술은 분류(1편) → 요약(2편) → 생성(3편) 순으로 이어집니다. 광고 카피는 '생성'의 실용 예시입니다.
- 모델을 새로 학습하지 않습니다. 직접 만든 스타일 시드를 few-shot으로 주입해 톤을 잡습니다.
- 맨 프롬프트는 톤이 들쭉날쭉, few-shot은 톤이 일관됩니다. 예시는 스타일당 10~15개가 적당합니다.
- generate_all(제품명) 한 줄로 고급·친근·유머·직설 4가지 카피가 한 번에 나옵니다.
- 카피 생성엔 Haiku로 충분합니다. 비용·속도 다 유리하고, 필요할 때만 상위 모델로 올리면 됩니다.
- 한 제품을 4스타일로 뽑아두면 채널마다 골라 쓰기만 하면 됩니다.
분류기를 만들고(1편), 실제 뉴스에 적용하고(2편), 이번엔 직접 무언가를 생성하는 데까지 왔습니다.
학습 없이 프롬프트만으로 이 정도 톤을 잡을 수 있다는 게, LLM 시대 NLP의 달라진 점이에요.
여기에 이미지 생성이나 해시태그 추천까지 붙이면?
제품명 하나로 카피 + 이미지 + 태그가 한 번에 나오는 도구가 될 것 같습니다.
저도 기회가 되면 한번 더 발전시켜보려고 합니다.