
[소셜 미디어 트렌드 1편] 영화 리뷰 20만 건으로 감성 분석 모델 만들기
YouTube 댓글을 분석하려면 먼저 감성 분석 모델이 필요합니다. 네이버 영화 리뷰(NSMC) 20만 건으로 한글 텍스트를 전처리하고, TF-IDF로 숫자로 바꾸고, Logistic Regression과 Naive Bayes를 비교해서 83% 정확도의 감성 분류기를 만듭니다.
시작하며 — 왜 감성 분석부터?
이번 시리즈의 최종 목표는 YouTube 댓글을 수집해서 트렌드를 분석하는 대시보드를 만드는 겁니다.
그런데 댓글을 수천 개 모아봤자, 사람이 하나하나 읽으면서 "이건 긍정, 이건 부정" 분류할 수는 없겠죠.
그래서 자동으로 긍정/부정을 판별하는 감성 분석 모델이 먼저 필요합니다.
이번 1편에서는 네이버 영화 리뷰 데이터(NSMC) 20만 건으로 한글 감성 분석 모델을 만들어봅니다.
텍스트를 숫자로 바꾸고, 모델 두 개를 비교해서 더 나은 걸 고르는 과정까지 진행합니다.
전체 흐름 — 텍스트가 예측이 되려면 어떤 과정을 거칠까요?
텍스트를 머신러닝 모델에 넣으려면 수집, 전처리, 특징 추출, 모델 학습, 평가까지 총 5단계를 거칩니다. 숫자 데이터와 가장 큰 차이는 전처리와 특징 추출 단계인데, 컴퓨터가 문장을 직접 이해할 수 없으니 텍스트를 숫자 벡터로 변환하는 과정이 반드시 필요하기 때문이에요.

텍스트 데이터로 머신러닝을 하려면 위 5단계를 거칩니다.
숫자 데이터와 가장 큰 차이는 2단계(전처리)와 3단계(특징 추출)이죠.
컴퓨터는 "이 영화 재미있다"라는 문장을 바로 이해할 수 없으니까, 숫자 벡터로 바꿔줘야 합니다.
데이터 준비 — NSMC는 어떤 데이터셋인가요?
NSMC(Naver Sentiment Movie Corpus)는 네이버 영화 리뷰에서 수집한 한글 감성 분석용 공개 데이터셋입니다.
총 20만 건 — 긍정 10만 건, 부정 10만 건으로 균형이 맞춰져 있어서 입문용으로 좋습니다.
import pandas as pd
# NSMC 데이터 로드
train = pd.read_csv('ratings_train.txt', sep='\t')
test = pd.read_csv('ratings_test.txt', sep='\t')
print(f"학습 데이터: {len(train):,}건") # 150,000건
print(f"테스트 데이터: {len(test):,}건") # 50,000건
print(f"컬럼: {list(train.columns)}") # ['id', 'document', 'label']
print(f"\n긍정(1) vs 부정(0):")
print(train['label'].value_counts())Jupyter 실행 결과 보기
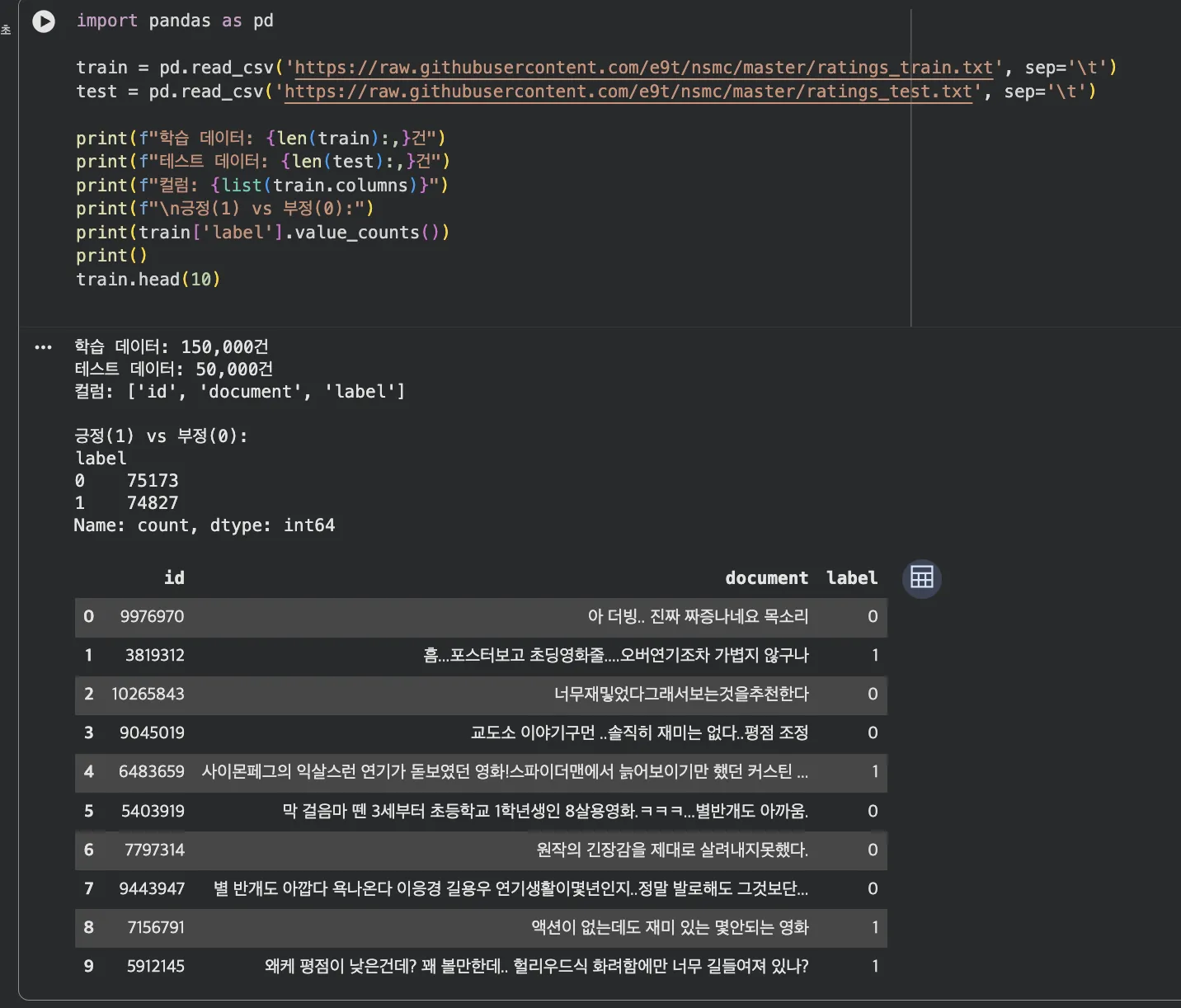
id: 리뷰 고유번호
document: 리뷰 텍스트 (예: "이 영화 진짜 재미있다")
label: 0(부정) 또는 1(긍정)
먼저 결측치부터 확인합니다. 텍스트 데이터는 빈 문자열이나 NaN이 생각보다 꽤 섞여 있거든요.
# 결측치 확인 및 제거
print(f"결측치: {train['document'].isnull().sum()}건") # 5건
train = train.dropna(subset=['document'])
test = test.dropna(subset=['document'])
print(f"정제 후 학습 데이터: {len(train):,}건")전처리 — 노이즈를 제거하면 정확도가 왜 올라갈까요?
Jupyter 실행 결과 보기 — 전처리 전/후 비교
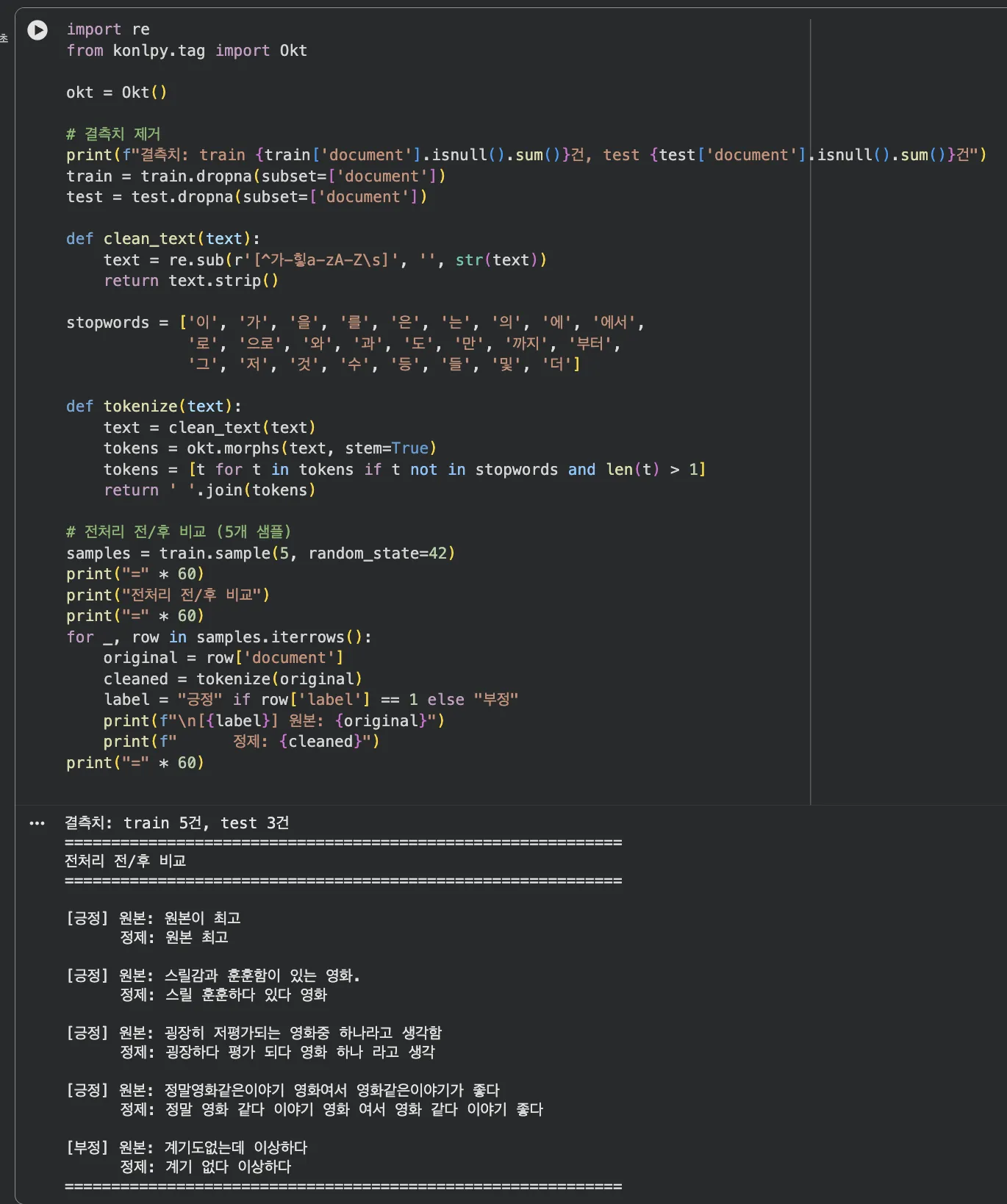
한글 텍스트에는 생각보다 노이즈가 많습니다.
"ㅋㅋㅋ", "...", "!!", "ㅠㅠ" 같은 건 감정 표현이긴 한데, 모델이 이걸 잘 학습하긴 어렵습니다.
그리고 "이", "를", "은" 같은 조사는 모든 문장에 다 나오니까 의미가 없습니다.
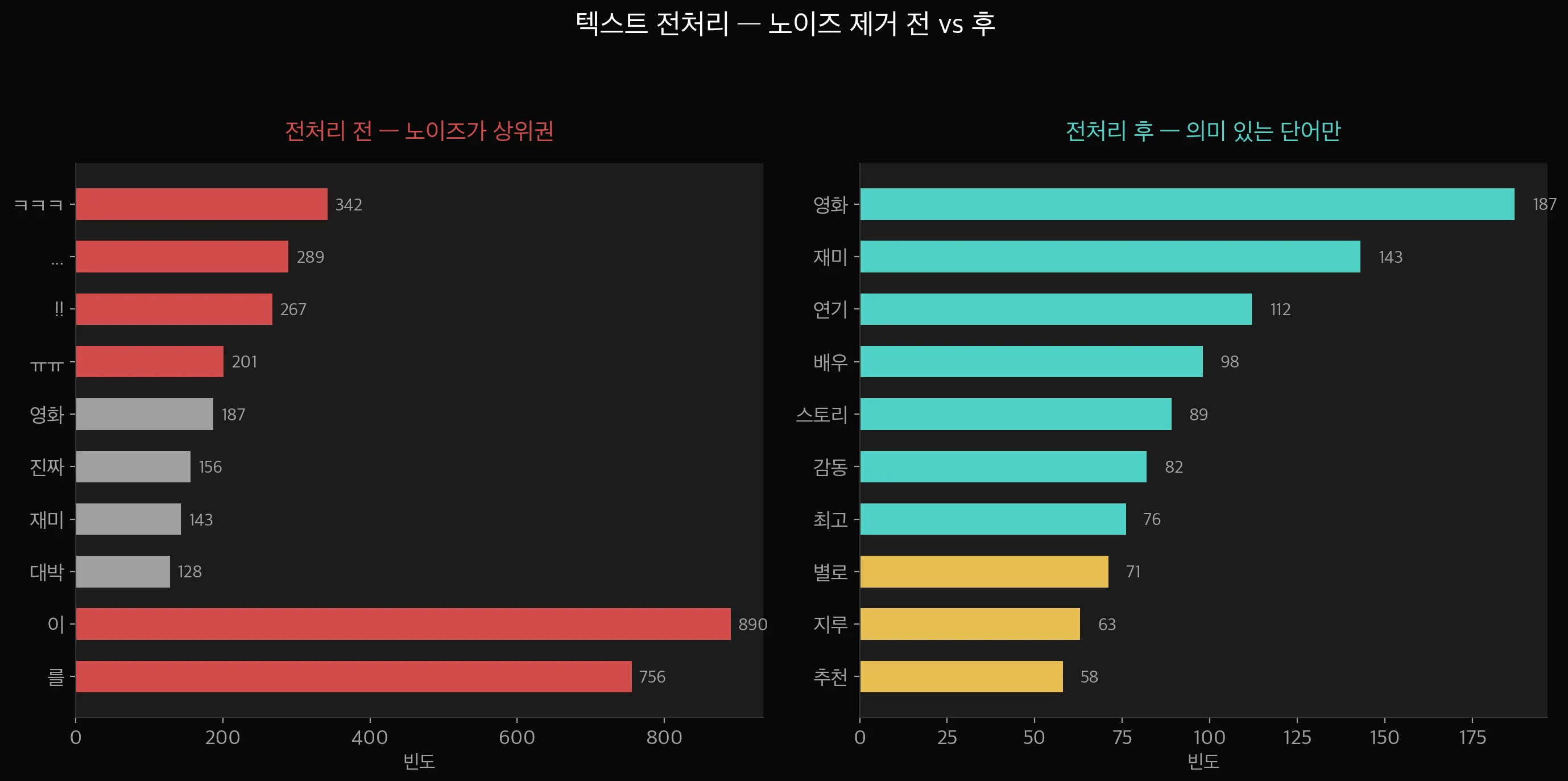
왼쪽이 전처리 전입니다. "이", "를" 같은 조사가 빈도 최상위를 차지하고, "ㅋㅋㅋ", "ㅠㅠ" 같은 표현도 많이 보이죠.
오른쪽은 전처리 후입니다. "영화", "재미", "연기", "배우" 같은 실제 의미가 있는 단어만 남았습니다.
전처리는 크게 3단계입니다.
1. 정규화 — 특수문자, 숫자 제거
import re
def clean_text(text):
"""한글, 영문, 공백만 남기기"""
text = re.sub(r'[^가-힣a-zA-Z\s]', '', str(text))
return text.strip()
# 적용 예시
sample = "이 영화 진짜 재미있다 ㅋㅋㅋ!! 10점 만점에 10점~"
print(clean_text(sample))
# → "이 영화 진짜 재미있다 ㅋㅋㅋ 점 만점에 점"2. 형태소 분석 — 단어를 쪼개기
영어는 띄어쓰기 기준으로 단어를 나눌 수 있지만, 한글은 "재미있다"에서 "재미"와 "있다"를 분리해야 합니다.
konlpy의 Okt(Open Korean Text)를 사용합니다.
from konlpy.tag import Okt
okt = Okt()
# 형태소 분석 예시
text = "이 영화 진짜 재미있다"
tokens = okt.morphs(text)
print(tokens) # ['이', '영화', '진짜', '재미있다']
# 명사만 추출
nouns = okt.nouns(text)
print(nouns) # ['영화', '진짜']
# 품사 태깅
pos = okt.pos(text)
print(pos) # [('이', 'Determiner'), ('영화', 'Noun'), ('진짜', 'Noun'), ('재미있다', 'Adjective')]3. 불용어 제거 — 의미 없는 단어 걸러내기
# 한글 불용어 리스트
stopwords = ['이', '가', '을', '를', '은', '는', '의', '에', '에서',
'로', '으로', '와', '과', '도', '만', '까지', '부터',
'그', '저', '것', '수', '등', '들', '및', '더']
def tokenize(text):
"""정규화 → 형태소 분석 → 불용어 제거"""
text = clean_text(text)
tokens = okt.morphs(text, stem=True) # stem=True: 어간 추출
tokens = [t for t in tokens if t not in stopwords and len(t) > 1]
return ' '.join(tokens)
# 전체 데이터에 적용
train['clean'] = train['document'].apply(tokenize)
test['clean'] = test['document'].apply(tokenize)Jupyter 실행 결과 보기 — 전체 전처리 적용 (약 5~10분 소요)
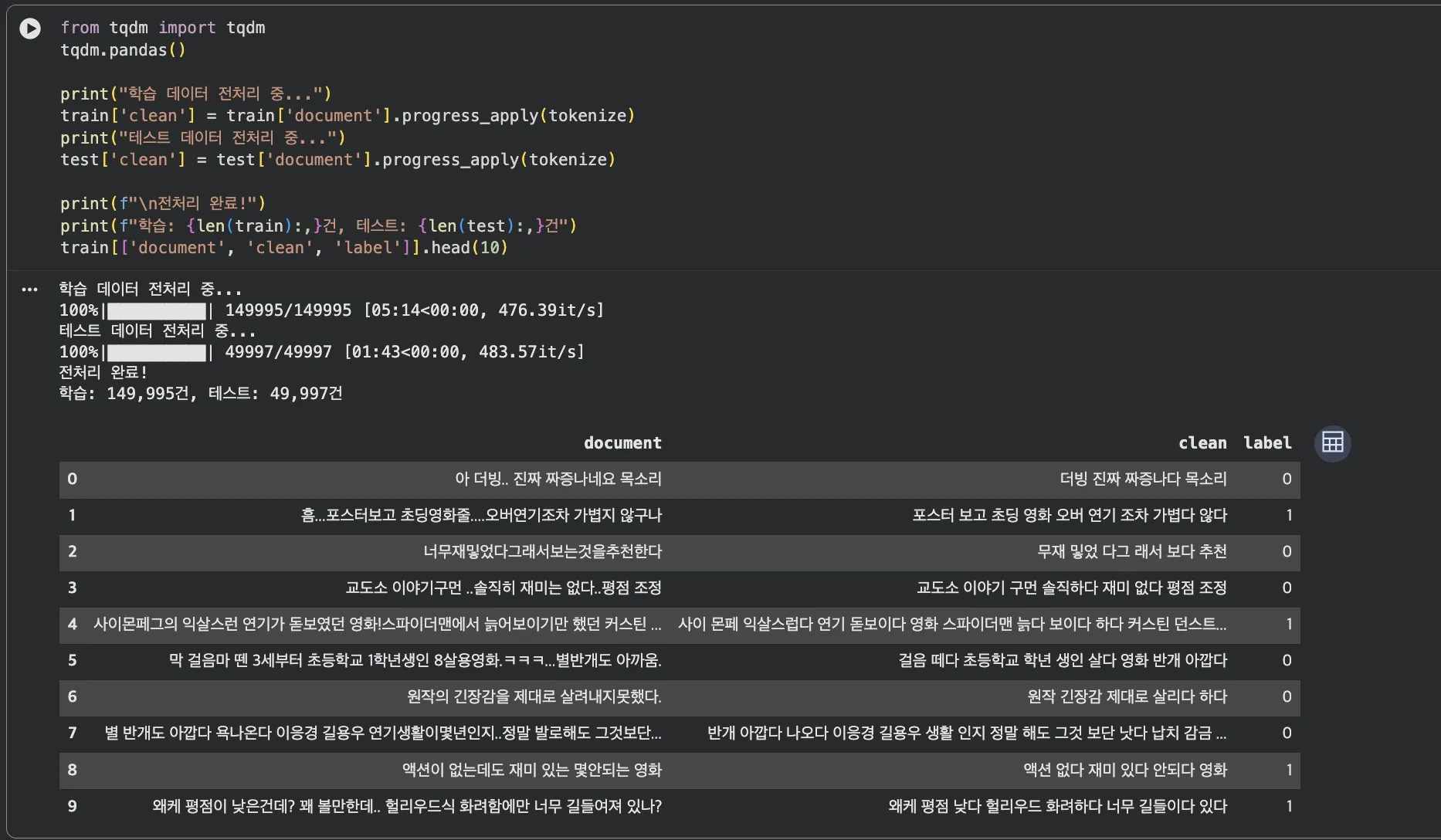
stem=True를 쓰면 "재미있다" → "재미있다", "재미있는" → "재미있다"처럼 어간을 통일합니다.
같은 의미인데 형태만 다른 단어들을 하나로 묶어주는 거죠.
다만 Okt의 스테밍이 완벽하지는 않아서, 실무에서는 Mecab을 쓰는 경우도 많습니다.
특징 추출 — TF-IDF로 텍스트를 어떻게 숫자로 바꿀까요?
전처리가 끝나면 텍스트를 숫자 벡터로 바꿔야 모델에 넣을 수 있습니다.
여기서 핵심이 되는 게 TF-IDF(Term Frequency - Inverse Document Frequency)입니다.
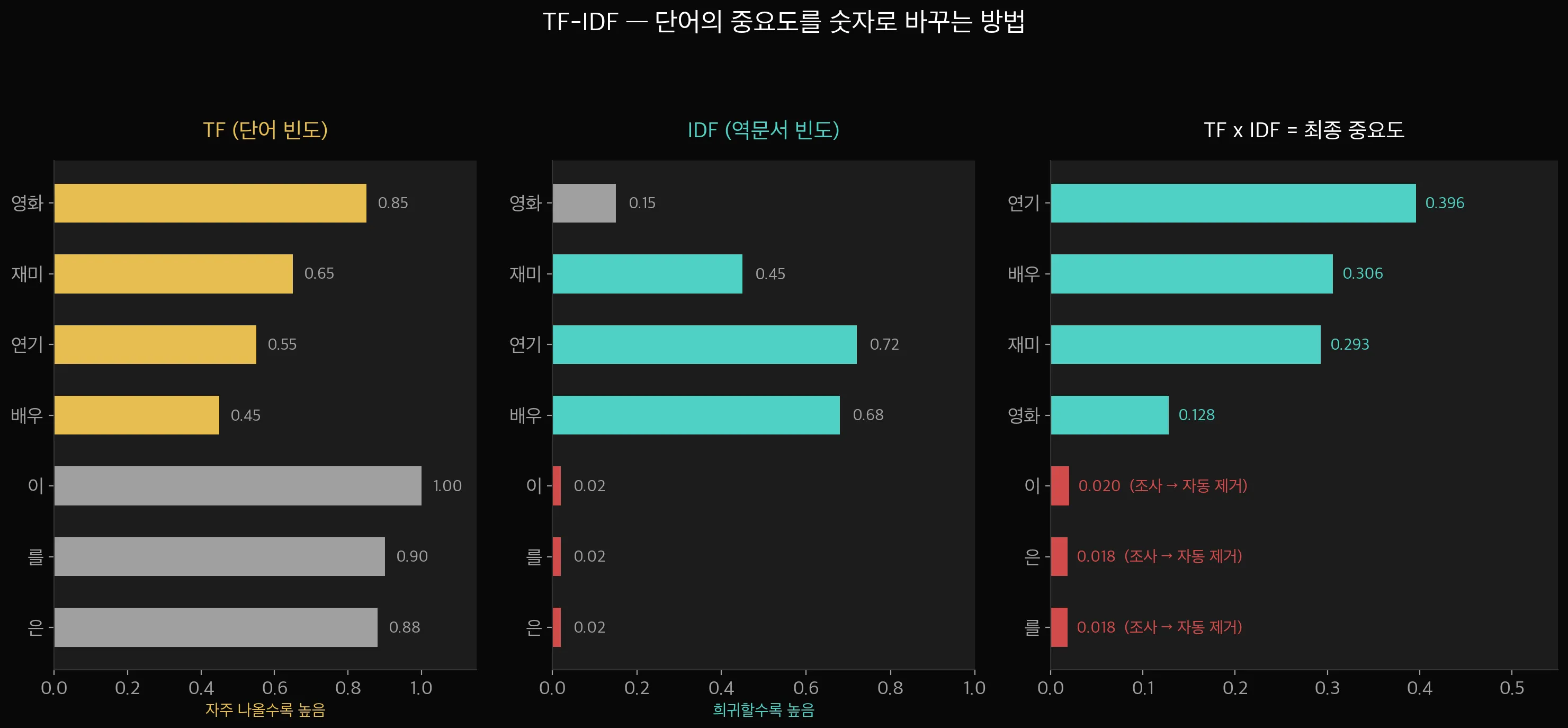
TF-IDF는 두 가지를 곱합니다.
- TF (단어 빈도): 해당 문서에서 단어가 얼마나 자주 나오는지. "영화"가 5번 나오면 TF가 높음.
- IDF (역문서 빈도): 전체 문서에서 얼마나 희귀한지. "이"는 모든 문서에 나오니까 IDF가 낮음.
위 차트를 보면 — "이", "를", "은" 같은 조사는 TF가 아무리 높아도 IDF가 거의 0이라 최종 중요도(TF×IDF)가 매우 낮습니다.
반면 "연기", "배우" 같은 단어는 특정 리뷰에만 집중적으로 나오니까 TF×IDF가 높게 나옵니다.
결과적으로 의미 있는 단어만 높은 점수를 받는 구조입니다.
from sklearn.feature_extraction.text import TfidfVectorizer
# TF-IDF 벡터화
tfidf = TfidfVectorizer(max_features=10000) # 상위 10,000개 단어만
X_train = tfidf.fit_transform(train['clean'])
X_test = tfidf.transform(test['clean'])
y_train = train['label']
y_test = test['label']
print(f"TF-IDF 행렬 크기: {X_train.shape}")
# → (149,995, 10,000) — 약 15만 문서 × 10,000 단어Jupyter 실행 결과 보기
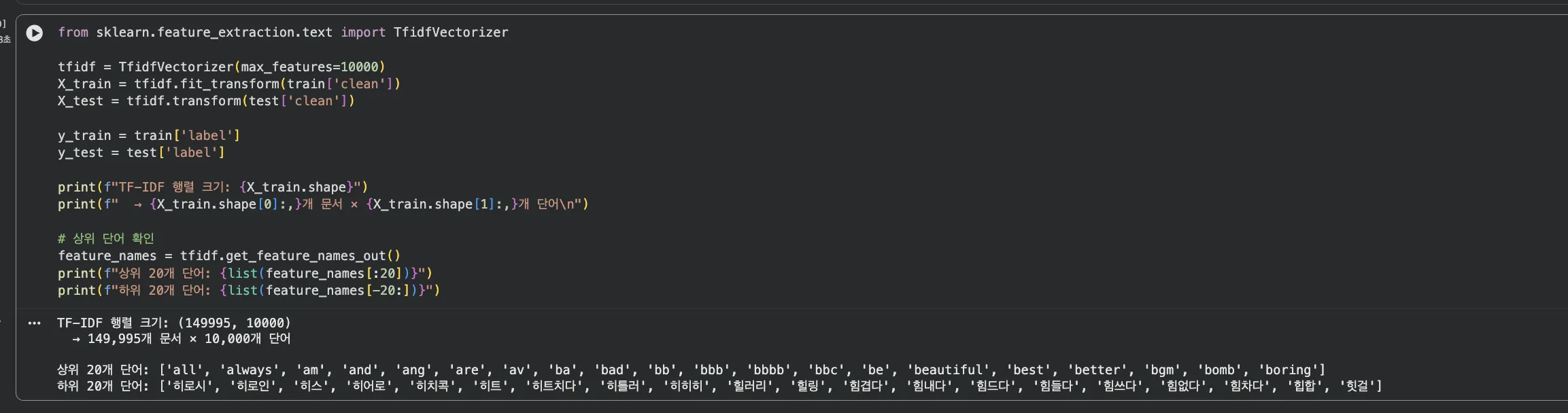
max_features=10000은 빈도 상위 1만 개 단어만 사용한다는 뜻입니다.
단어가 너무 많으면 차원이 폭발해서 학습이 느려집니다.
1만 개면 일반적인 한글 텍스트 분류에서 충분한 수준입니다.
모델 학습 — Logistic Regression과 Naive Bayes, 뭐가 다를까요?
텍스트 분류에서 자주 쓰이는 두 모델을 비교합니다.
- Logistic Regression: 각 단어에 가중치를 부여해서 긍정/부정 확률을 계산. 직관적이고 빠름.
- Naive Bayes: 각 단어가 독립이라고 가정하고, 긍정/부정에서 나올 확률을 계산. 텍스트에서 의외로 잘 됨.
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score, f1_score, classification_report
# 1. Logistic Regression
lr = LogisticRegression(max_iter=1000, C=1.0)
lr.fit(X_train, y_train)
lr_pred = lr.predict(X_test)
# 2. Naive Bayes
nb = MultinomialNB(alpha=1.0)
nb.fit(X_train, y_train)
nb_pred = nb.predict(X_test)
# 성능 비교
print("=== Logistic Regression ===")
print(f"Accuracy: {accuracy_score(y_test, lr_pred):.3f}")
print(f"F1 Score: {f1_score(y_test, lr_pred):.3f}")
print(classification_report(y_test, lr_pred, target_names=['부정', '긍정']))
print("\n=== Naive Bayes ===")
print(f"Accuracy: {accuracy_score(y_test, nb_pred):.3f}")
print(f"F1 Score: {f1_score(y_test, nb_pred):.3f}")
print(classification_report(y_test, nb_pred, target_names=['부정', '긍정']))Jupyter 실행 결과 보기
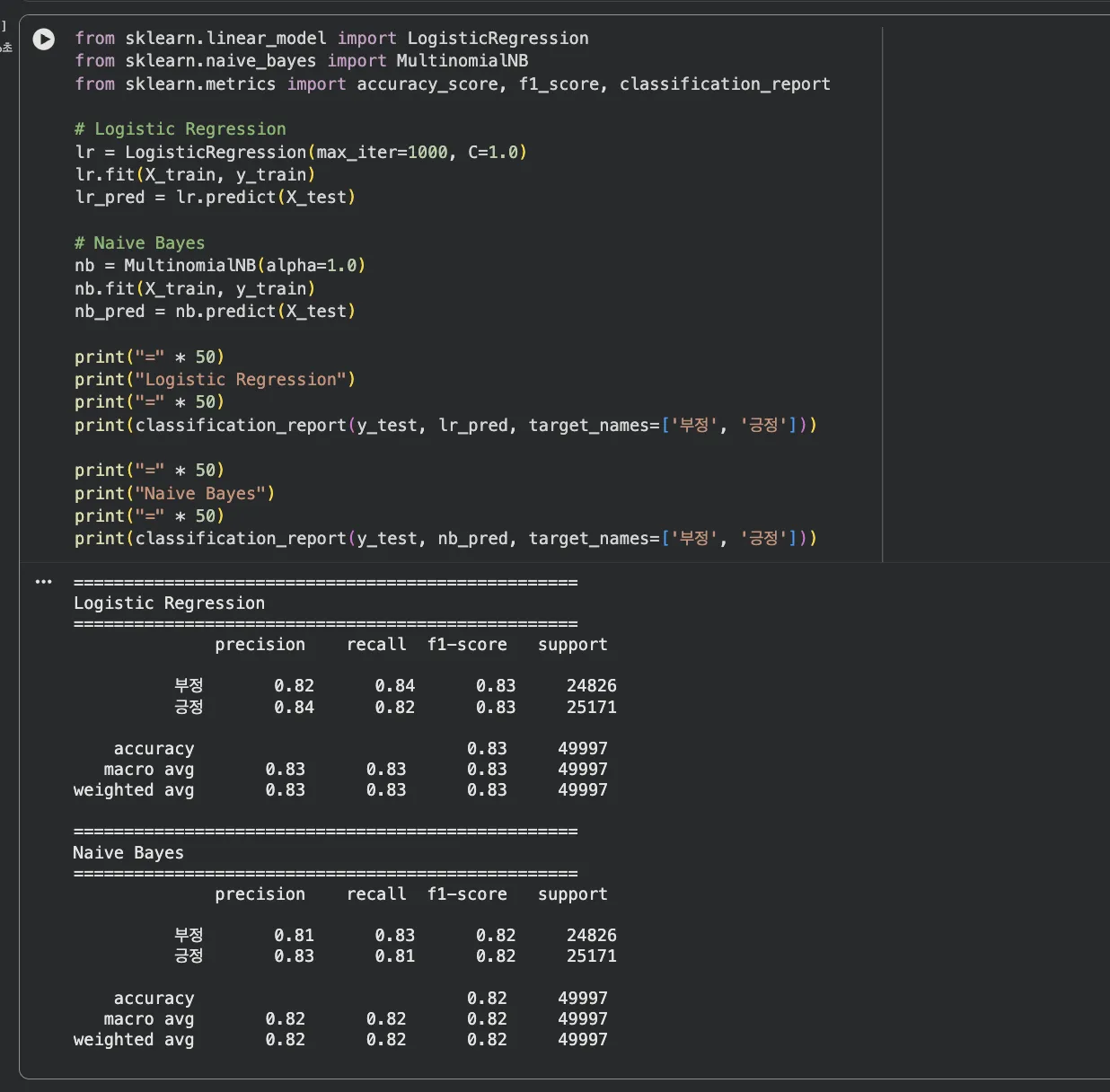
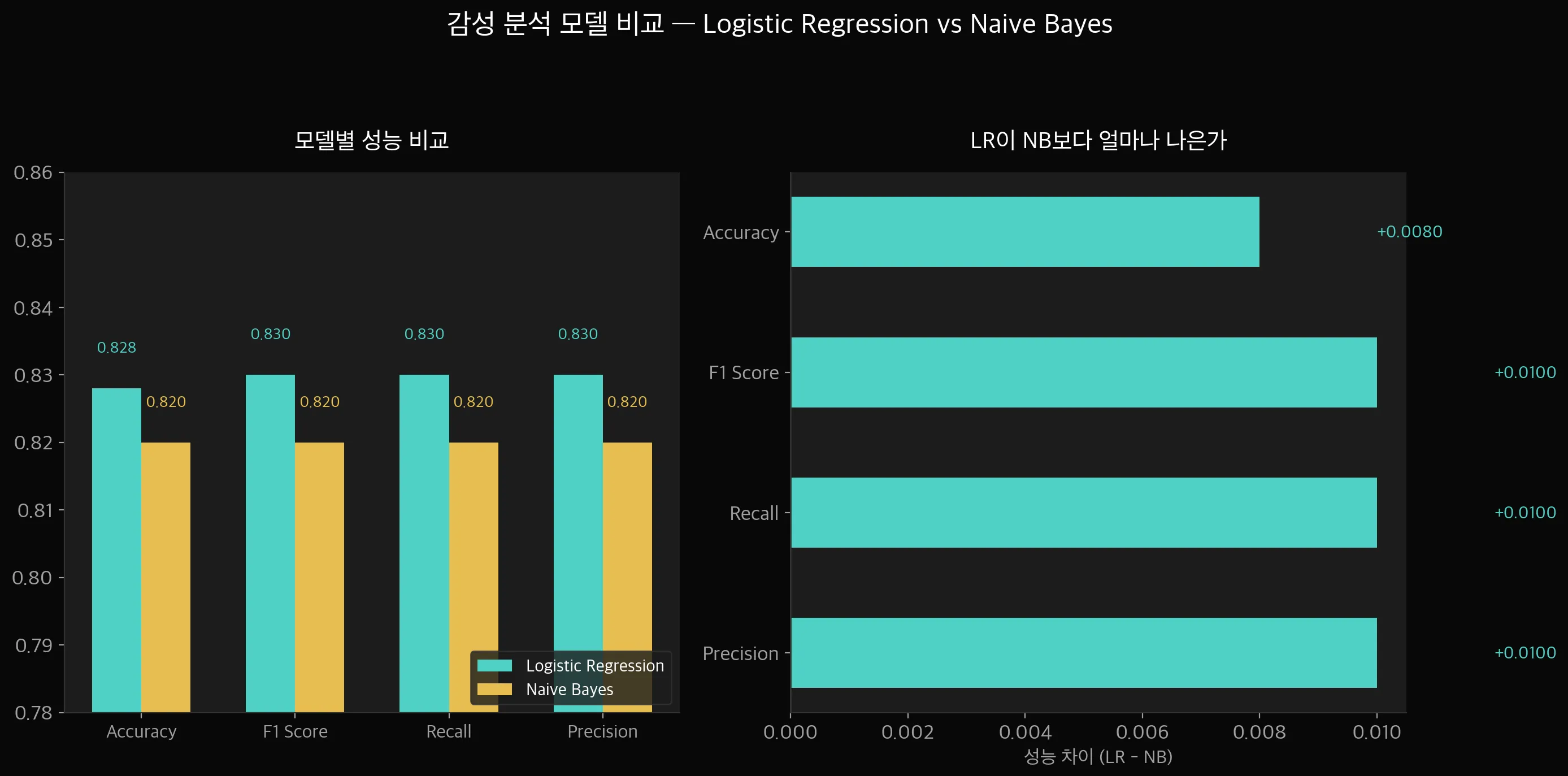
결과를 보면 Logistic Regression이 전 지표에서 약간 앞섭니다.
Accuracy 82.8% vs 82.0%로 차이가 크지는 않지만, 모든 지표에서 일관되게 LR이 나은 결과를 보여줍니다.
Naive Bayes가 나쁜 건 아닙니다.
학습 시간이 Logistic Regression보다 훨씬 빠르고, 데이터가 적을 때는 오히려 더 잘 되는 경우도 있습니다.
지금은 데이터가 15만 건으로 충분하니까 LR이 이긴 겁니다.
평가 — Confusion Matrix로 오답 패턴을 어떻게 볼까요?
정확도 83%가 좋아 보여도, 어디서 틀렸는지를 봐야 진짜 실력을 알 수 있습니다.
Confusion Matrix는 "실제 값 vs 예측 값"을 2×2 표로 보여줍니다.
from sklearn.metrics import confusion_matrix
# Confusion Matrix 계산
lr_cm = confusion_matrix(y_test, lr_pred)
nb_cm = confusion_matrix(y_test, nb_pred)
print("=== Logistic Regression ===")
print(lr_cm)
# [[20848, 3978],
# [ 4630, 20541]]
print("\n=== Naive Bayes ===")
print(nb_cm)
# [[20669, 4157],
# [ 4821, 20350]]Jupyter 실행 결과 보기
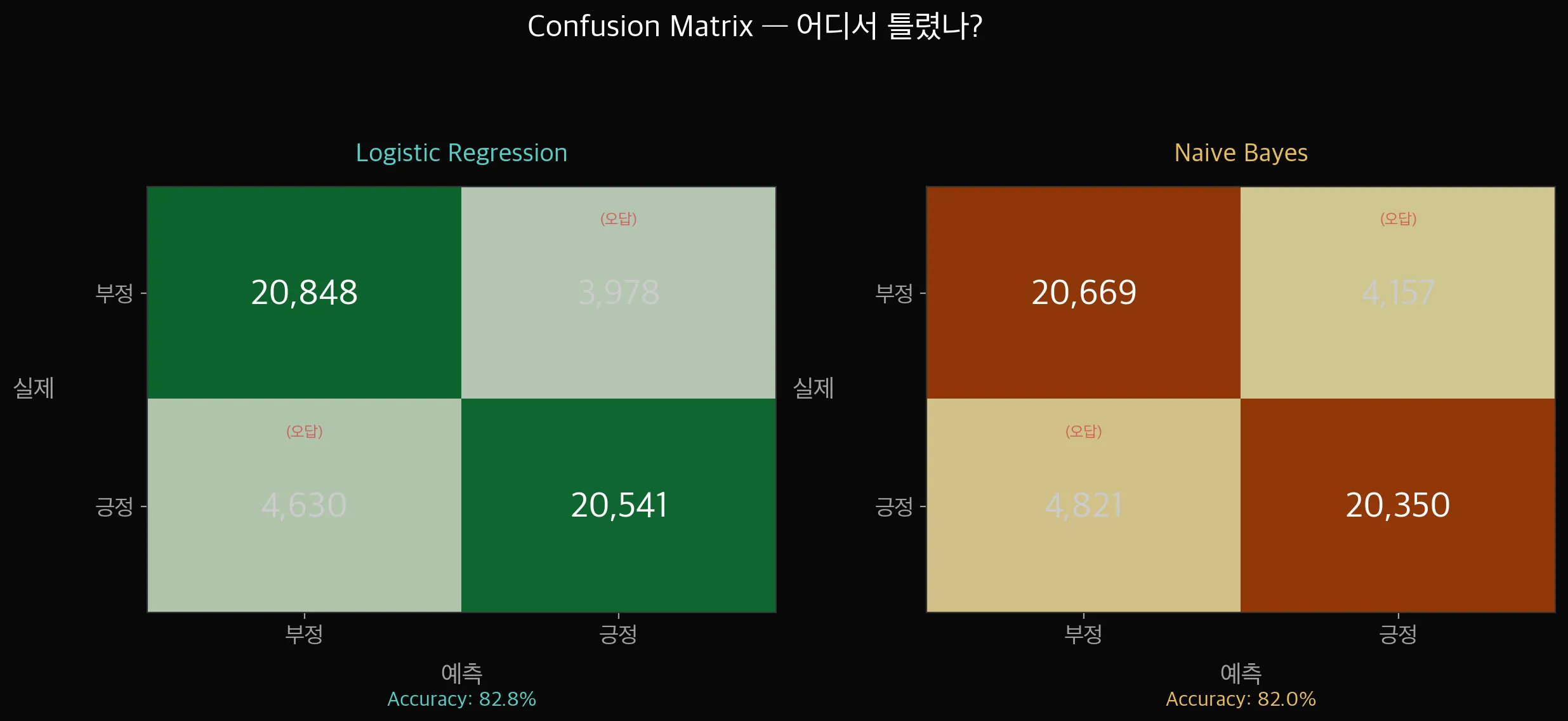
진한 색이 정답(대각선), 연한 색이 오답입니다.
두 모델 다 "긍정인데 부정으로 예측"하는 실수가 "부정인데 긍정으로 예측"보다 약간 더 많습니다.
LR 기준 — 부정을 긍정으로 오답(3,978건) vs 긍정을 부정으로 오답(4,630건)으로, 긍정을 부정으로 잘못 판단하는 경우가 더 많습니다.
NB도 비슷한 패턴이지만 오답 수가 전반적으로 더 많습니다.
왜 틀릴까?
"재미없진 않은데 감동은 아닌 영화" 같은 중립적인 리뷰가 대표적입니다.
부정어("없진")와 긍정어("감동")가 섞여 있으면 모델이 헷갈리는 거죠.
이런 리뷰는 사실 사람도 판단이 어렵습니다.
교차검증 — 한번만 돌리면 왜 안 될까요?
테스트셋 한번으로 끝내면, 운 좋게 잘 나온 건지 실력인지 구분이 안 됩니다.
5-Fold 교차검증으로 5번 다른 데이터 조합으로 평가합니다.
from sklearn.model_selection import cross_val_score
# 5-Fold 교차검증
lr_cv = cross_val_score(lr, X_train, y_train, cv=5, scoring='accuracy')
nb_cv = cross_val_score(nb, X_train, y_train, cv=5, scoring='accuracy')
print("=== Logistic Regression (5-Fold CV) ===")
print(f"각 Fold: {lr_cv.round(3)}")
print(f"평균: {lr_cv.mean():.3f} (±{lr_cv.std():.3f})")
print("\n=== Naive Bayes (5-Fold CV) ===")
print(f"각 Fold: {nb_cv.round(3)}")
print(f"평균: {nb_cv.mean():.3f} (±{nb_cv.std():.3f})")Jupyter 실행 결과 보기
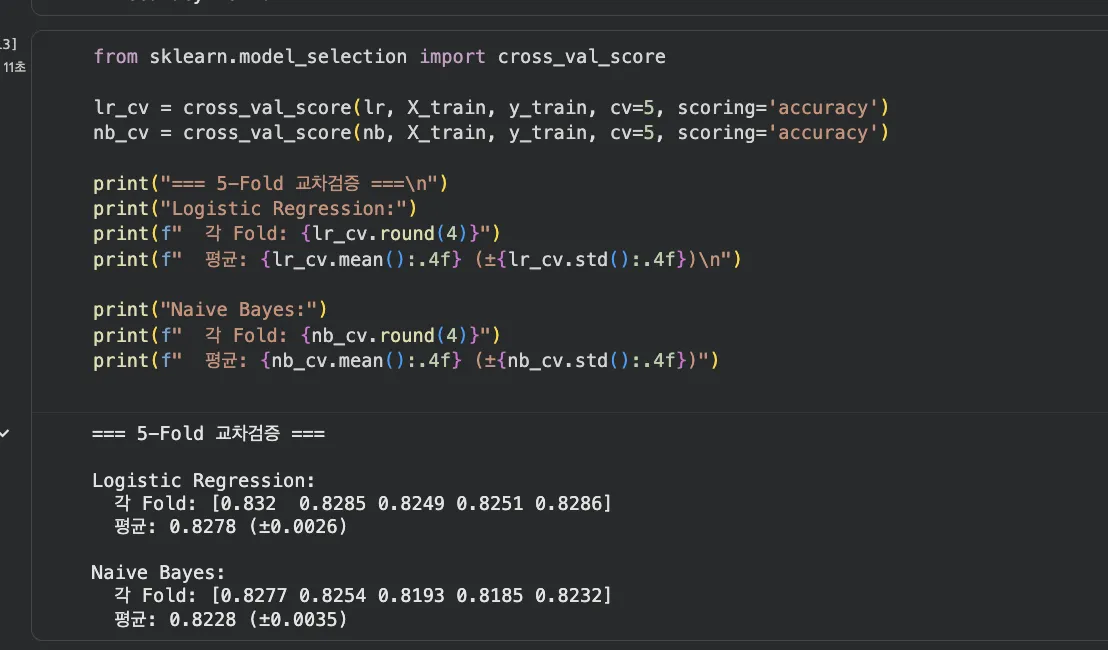
교차검증 결과도 LR이 안정적으로 앞섭니다.
표준편차(±)가 작다는 건 데이터를 바꿔도 성능이 비슷하다는 뜻이니까, 과적합 걱정은 안 해도 되겠죠.
모델 저장 — 다음 편에서 바로 쓰려면 어떻게 해야 할까요?
이 모델은 3편에서 YouTube 댓글에 적용할 겁니다.
매번 다시 학습시키면 비효율적이니, 모델과 TF-IDF 벡터라이저를 파일로 저장해둡니다.
import joblib
# 모델과 벡터라이저 저장
joblib.dump(lr, 'sentiment_model_lr.pkl')
joblib.dump(tfidf, 'tfidf_vectorizer.pkl')
print("모델 저장 완료!")
# 나중에 불러올 때
# lr_loaded = joblib.load('sentiment_model_lr.pkl')
# tfidf_loaded = joblib.load('tfidf_vectorizer.pkl')
# new_text = tfidf_loaded.transform(["이 영화 진짜 재미있다"])
# prediction = lr_loaded.predict(new_text)
# print(prediction) # [1] → 긍정Jupyter 실행 결과 보기 — 새 텍스트 감성 예측
정리 — 1편에서 한 것들

- 데이터: NSMC 한글 영화 리뷰 20만 건 (긍정 10만 + 부정 10만)
- 전처리: 정규화 + 형태소 분석(Okt) + 불용어 제거 → 노이즈 제거
- 특징 추출: TF-IDF로 텍스트를 10,000차원 숫자 벡터로 변환
- 모델: Logistic Regression(82.8%) vs Naive Bayes(82.0%) → LR 채택
- 평가: Confusion Matrix로 오답 패턴 분석 + 5-Fold 교차검증으로 안정성 확인
다음 2편에서는 이 데이터의 텍스트를 더 깊이 분석합니다.
문장 길이 분포, 워드클라우드, 긍정/부정 리뷰 간 차이 등 — 텍스트 EDA를 다룹니다.