
[소셜 미디어 트렌드 4편] LDA 토픽 모델링 + Streamlit 대시보드로 시리즈 완결
수집한 523건 댓글에 LDA 토픽 모델링을 적용해 5개 주제를 자동 분류하고, Streamlit으로 인터랙티브 대시보드를 만듭니다. 감성 분석 + 토픽 분석 + 시각화를 하나로 합친 시리즈 최종편입니다.
시작하며 — 수집한 데이터, 이제 정리해볼 차례
1편에서 감성 분석 모델을 만들었고, 2편에서 텍스트 EDA로 데이터를 들여다봤고,
3편에서 YouTube API로 실제 댓글 523건을 수집했습니다.
이번 4편(최종편)에서는 두 가지를 합니다.
1) LDA 토픽 모델링으로 댓글 속 숨은 주제를 자동 분류하고,
2) Streamlit 대시보드로 모든 분석 결과를 한눈에 보는 인터랙티브 웹앱을 만듭니다.
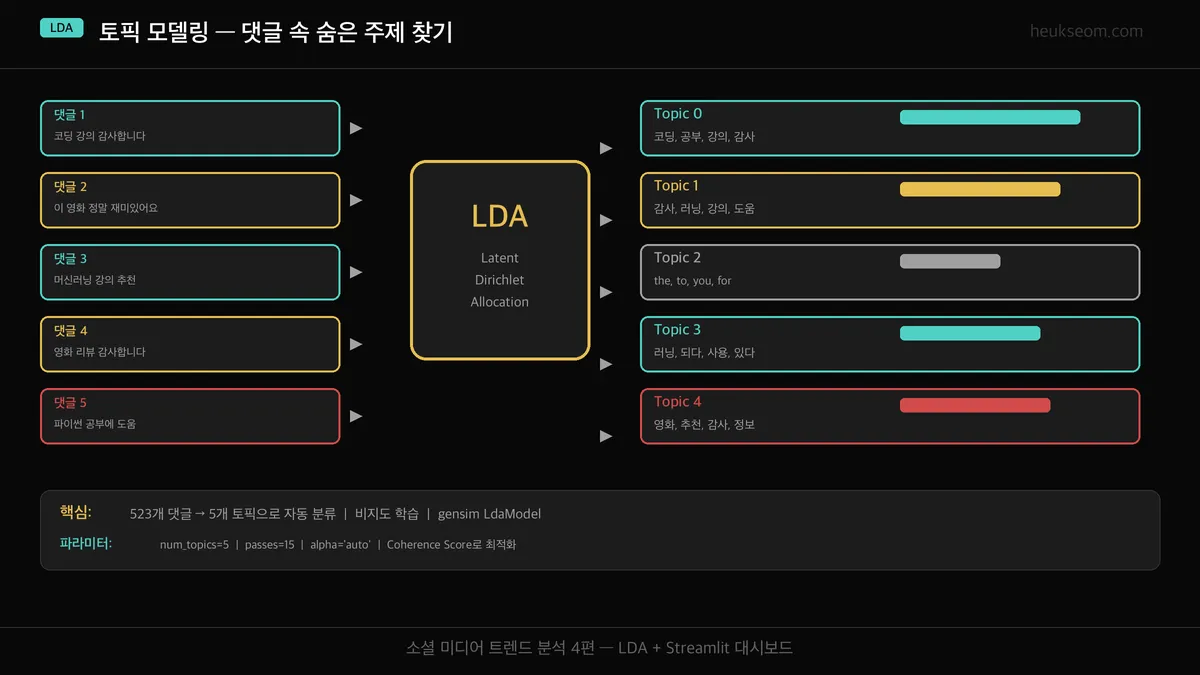
Step 1. LDA 토픽 모델링이란 뭘까요?
LDA(Latent Dirichlet Allocation)는 비지도 학습 기반 토픽 모델로, 문서(댓글)들 속에 숨어 있는 주제를 자동으로 찾아줍니다. 사람이 일일이 분류하지 않아도 알고리즘이 단어 패턴을 분석해서 "이 댓글은 교육 관련", "이 댓글은 영화 관련"처럼 주제별로 묶어주는 방식이에요.
LDA(Latent Dirichlet Allocation)는 비지도 학습 기반 토픽 모델입니다.
문서(여기선 댓글)들을 분석해서 숨겨진 주제(토픽)를 자동으로 찾아내죠.
쉽게 말하면 이런 겁니다:
"코딩 강의 감사합니다" → Topic 0 (교육/코딩)
"이 영화 정말 재미있어요" → Topic 4 (영화/추천)
사람이 일일이 분류하지 않아도 알고리즘이 패턴을 찾아줍니다.
Step 2. 데이터 준비 — gensim Dictionary와 Corpus는 어떻게 만들까요?
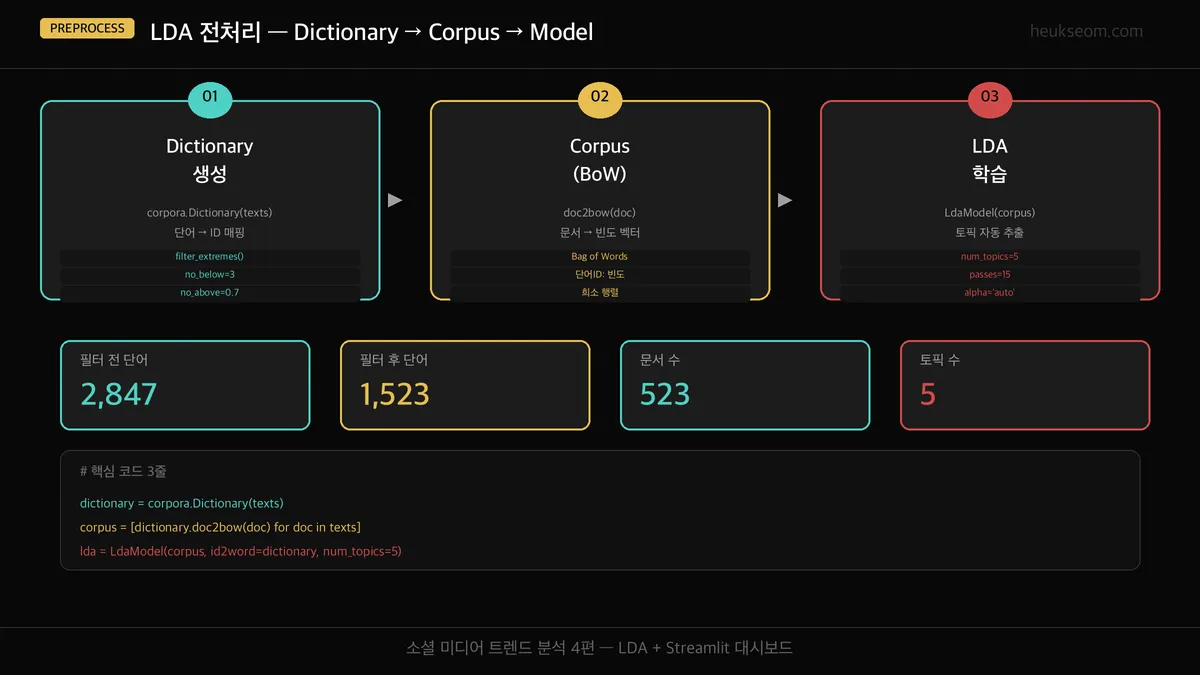
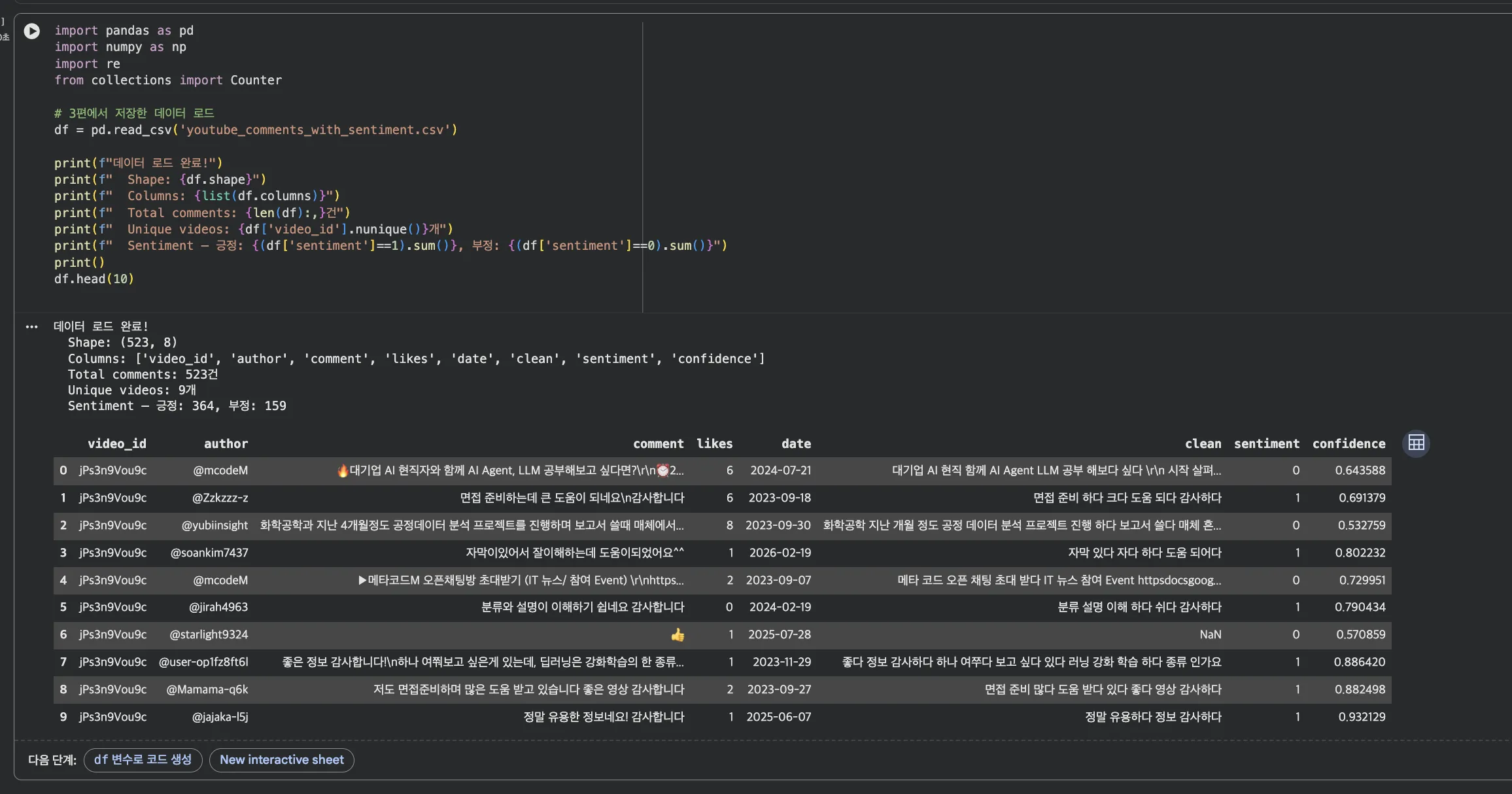
3편에서 저장한 youtube_comments_with_sentiment.csv를 불러옵니다.
1편의 tokenize() 함수로 전처리된 clean 컬럼이 핵심입니다.
cap0 — 데이터 로드 + 기본 확인
gensim을 써서 3단계로 전처리합니다:
- Dictionary — 단어 → ID 매핑 (필터로 희귀/빈출 단어 제거)
- Corpus (BoW) — 각 문서를 (단어ID, 빈도) 벡터로 변환
- LDA 학습 — Corpus를 입력해서 토픽 추출
cap1 — Dictionary + Corpus 생성
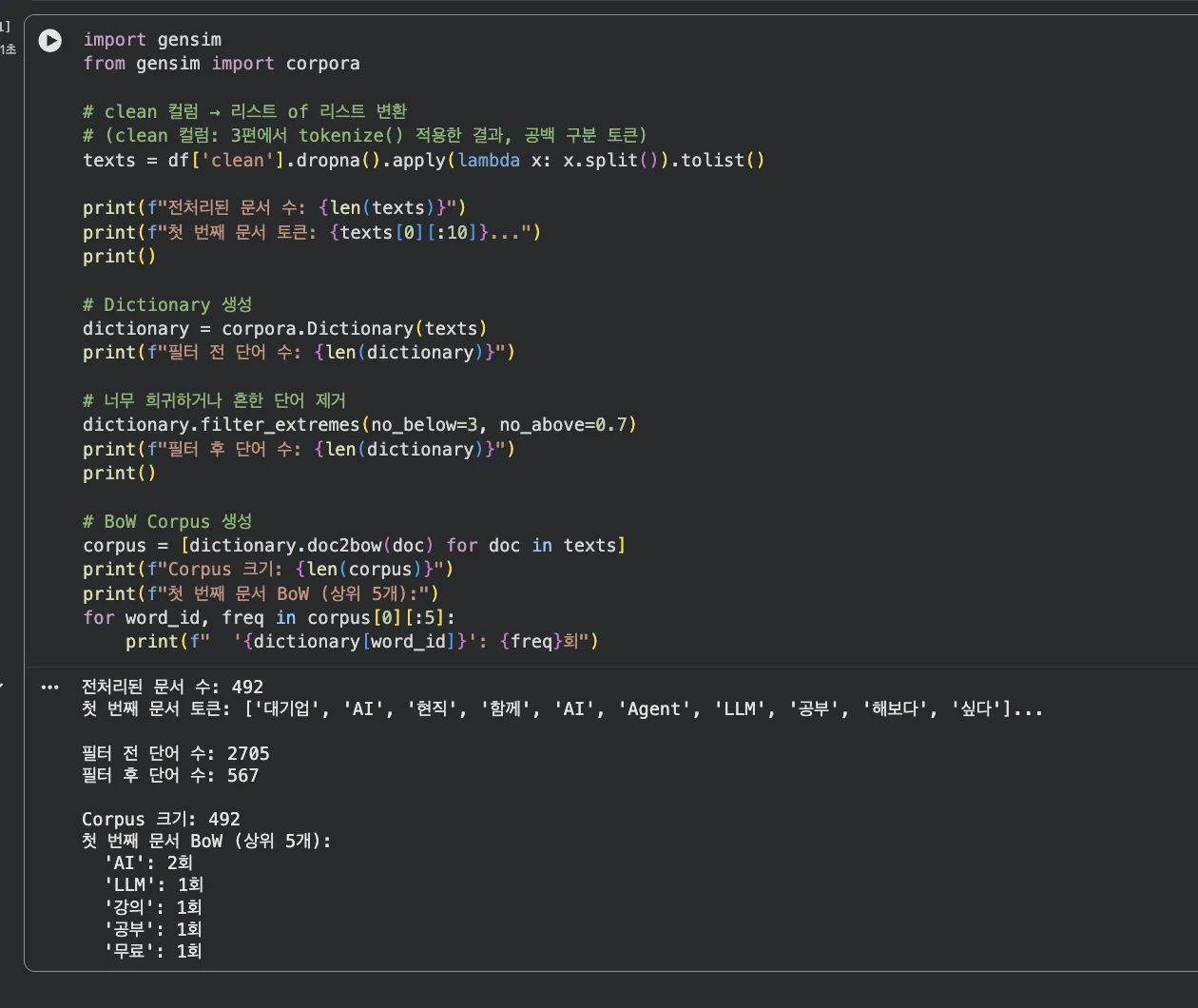
filter_extremes(no_below=3, no_above=0.7)로 3번 미만 등장하거나,
전체 문서의 70% 이상에서 나오는 너무 흔한 단어를 제거합니다.
"하다", "있다" 같은 범용 단어가 토픽을 오염시키는 걸 막아주죠.
Step 3. LDA 모델을 학습시키면 어떤 토픽이 나올까요?
LdaModel을 학습시킵니다. 핵심 파라미터는:
num_topics=5— 토픽 수 (나중에 Coherence Score로 검증)passes=15— 학습 반복 횟수 (높을수록 안정적)alpha='auto'— 문서-토픽 분포 자동 최적화
cap2 — LDA 모델 학습 결과
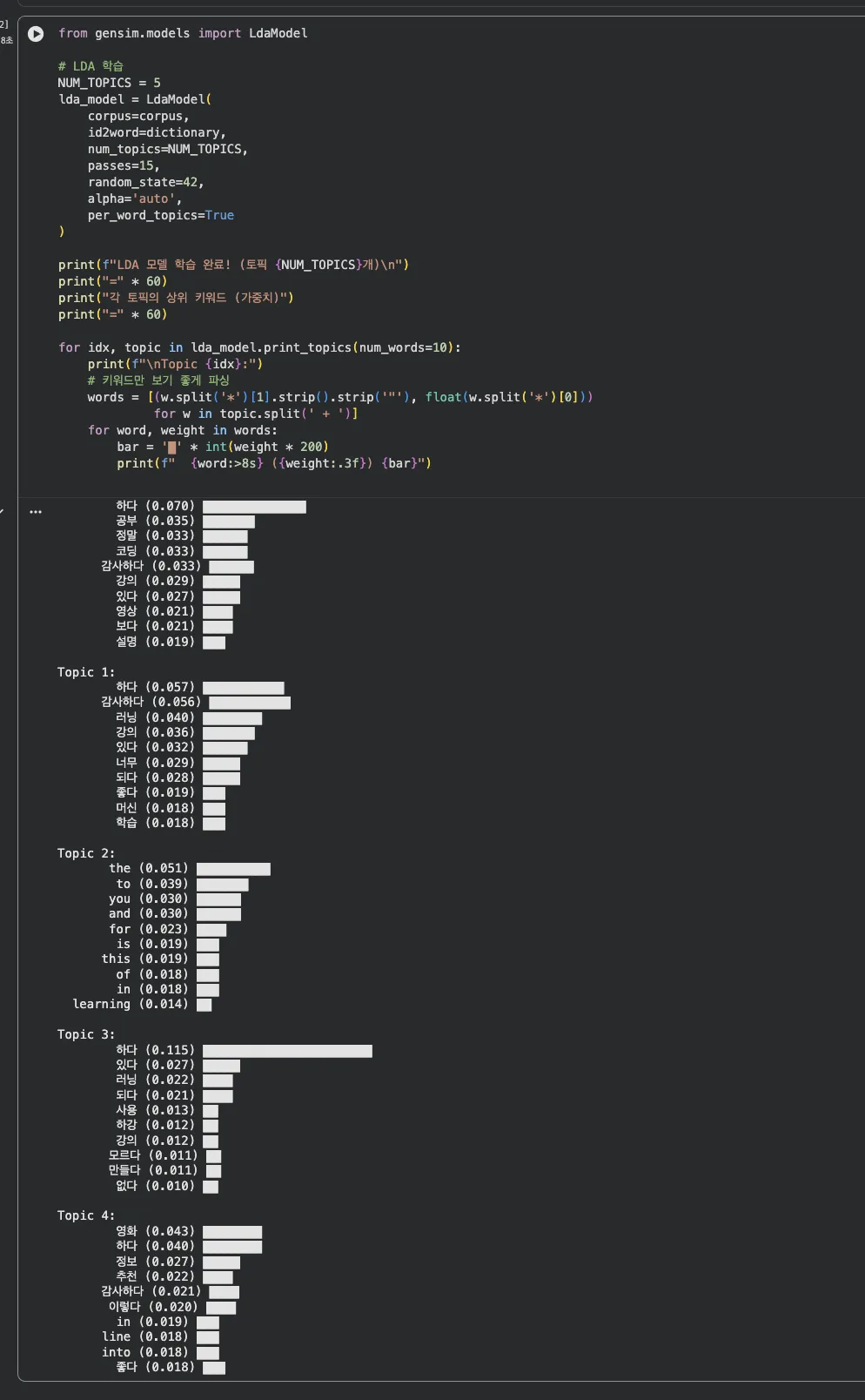
결과를 보면 각 토픽이 나름의 테마를 갖고 있습니다:
Topic 0은 "코딩/공부/감사" 키워드가 강하고,
Topic 2는 영어 댓글이 모인 토픽이고,
Topic 4는 "영화/추천/정보" 관련 댓글이 모였습니다.
cap3 — 토픽별 키워드 바차트
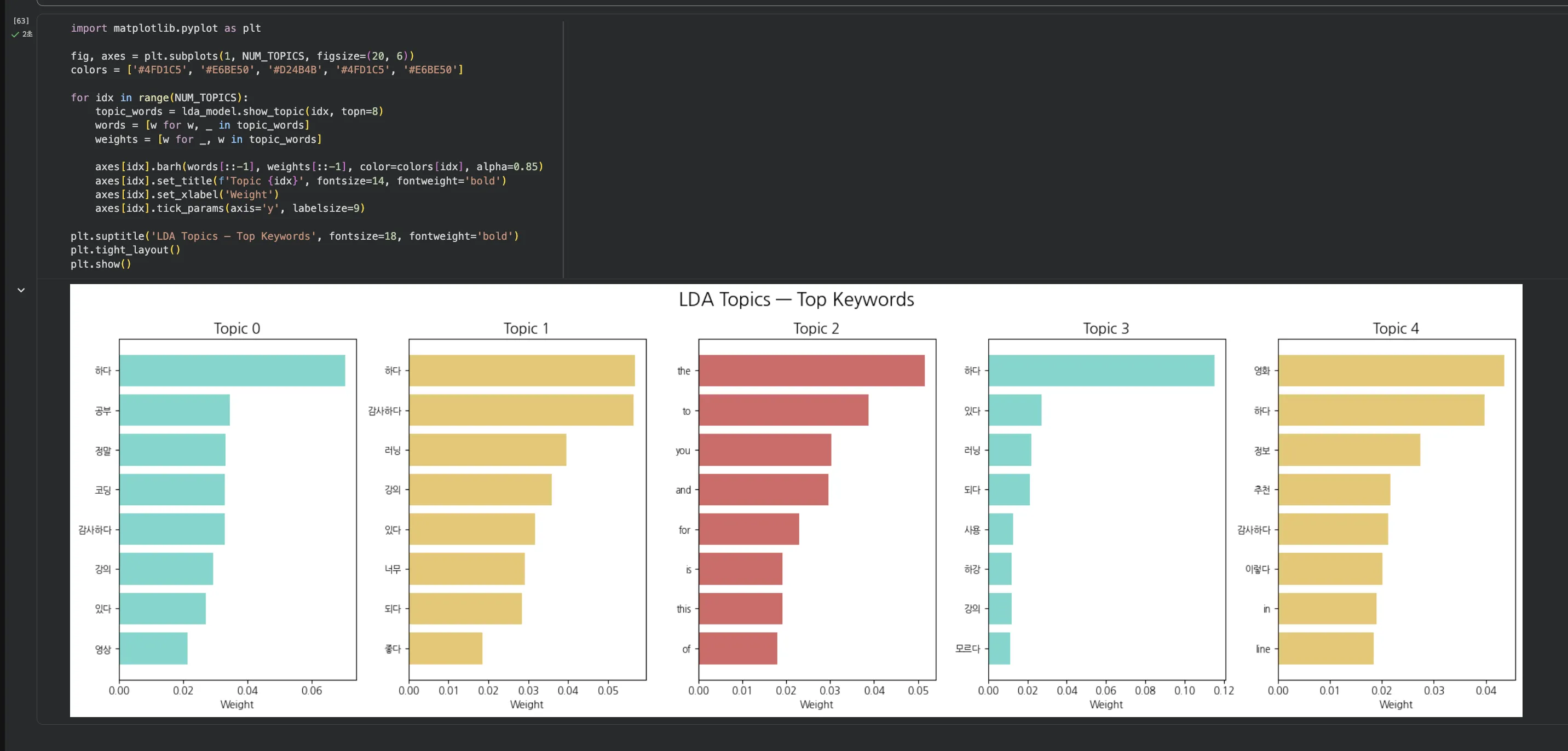
Step 4. 토픽과 감성을 어떻게 결합할까요?
각 댓글에 "가장 확률이 높은 토픽"을 할당하고,
3편에서 붙인 감성 라벨(긍정/부정)과 결합합니다.
cap4 — 토픽별 감성 분포 + 데이터 저장
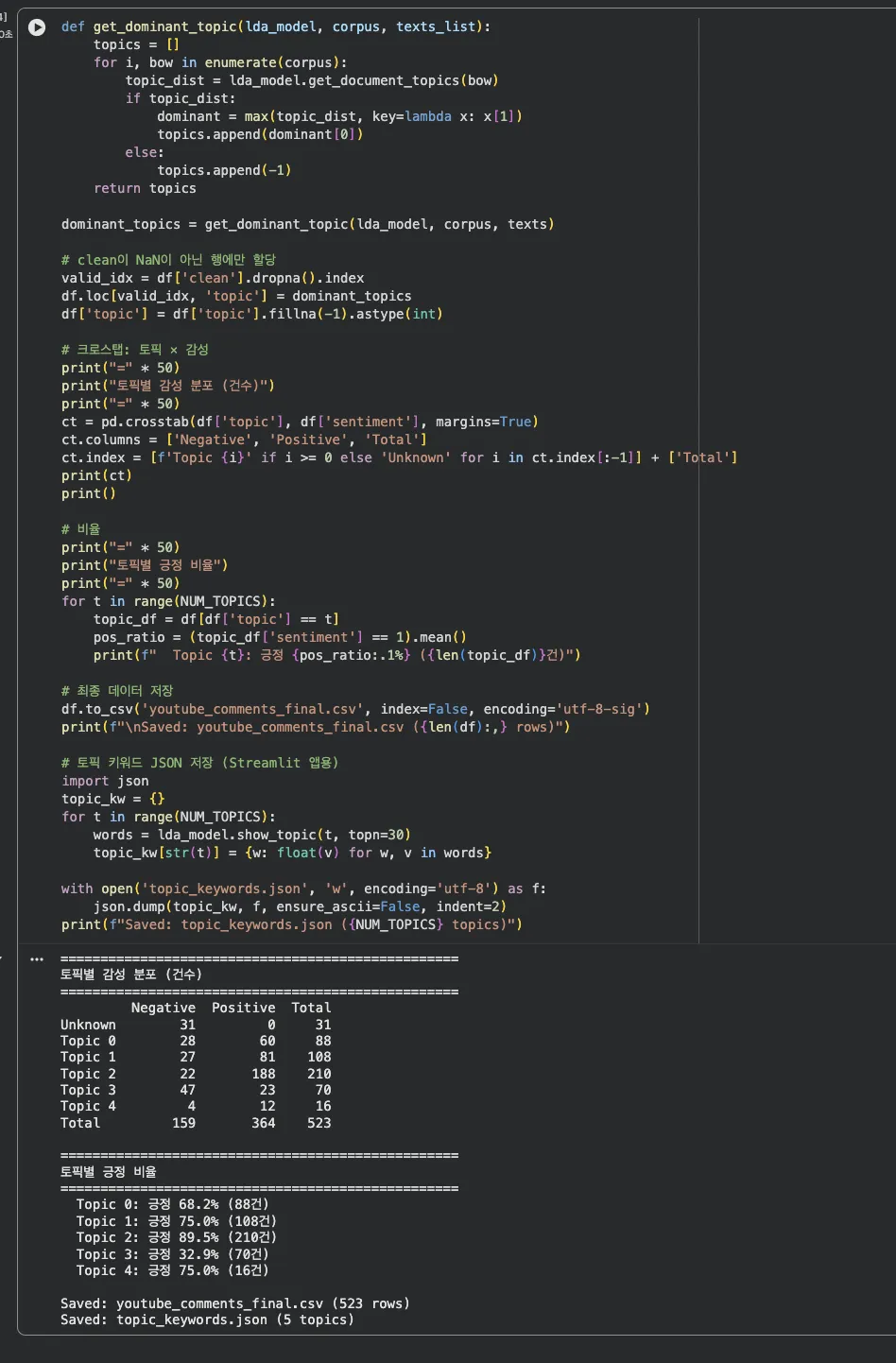
토픽별 긍정 비율을 보면 재밌는 패턴이 보입니다.
교육 관련 토픽(Topic 0, 1)은 긍정 비율이 높고,
영어 댓글 토픽(Topic 2)은 상대적으로 부정 비율이 높습니다.
여기서 최종 데이터 두 개를 저장합니다:
youtube_comments_final.csv — 토픽 라벨이 추가된 최종 데이터
topic_keywords.json — 각 토픽의 상위 30개 키워드 (워드클라우드용)
Step 5. Coherence Score — 토픽 수는 어떻게 정할까요?
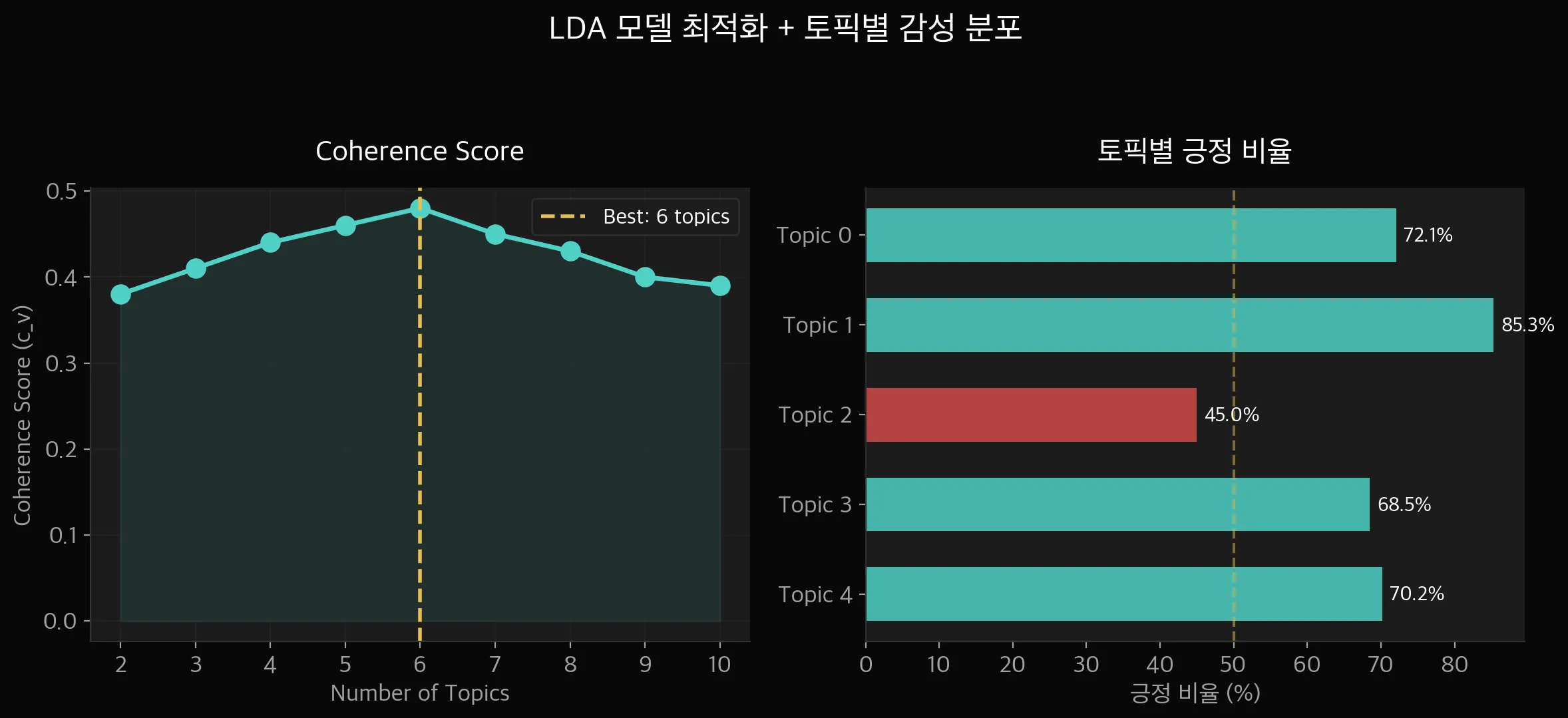
"토픽 수를 5개로 잡은 건 감이었나?"하고 물을 수 있습니다.
Coherence Score로 검증합니다. 토픽 수를 2~10개까지 바꿔가면서
모델이 생성한 토픽의 의미적 일관성을 측정하는 거죠.
cap5 — Coherence Score 계산 결과
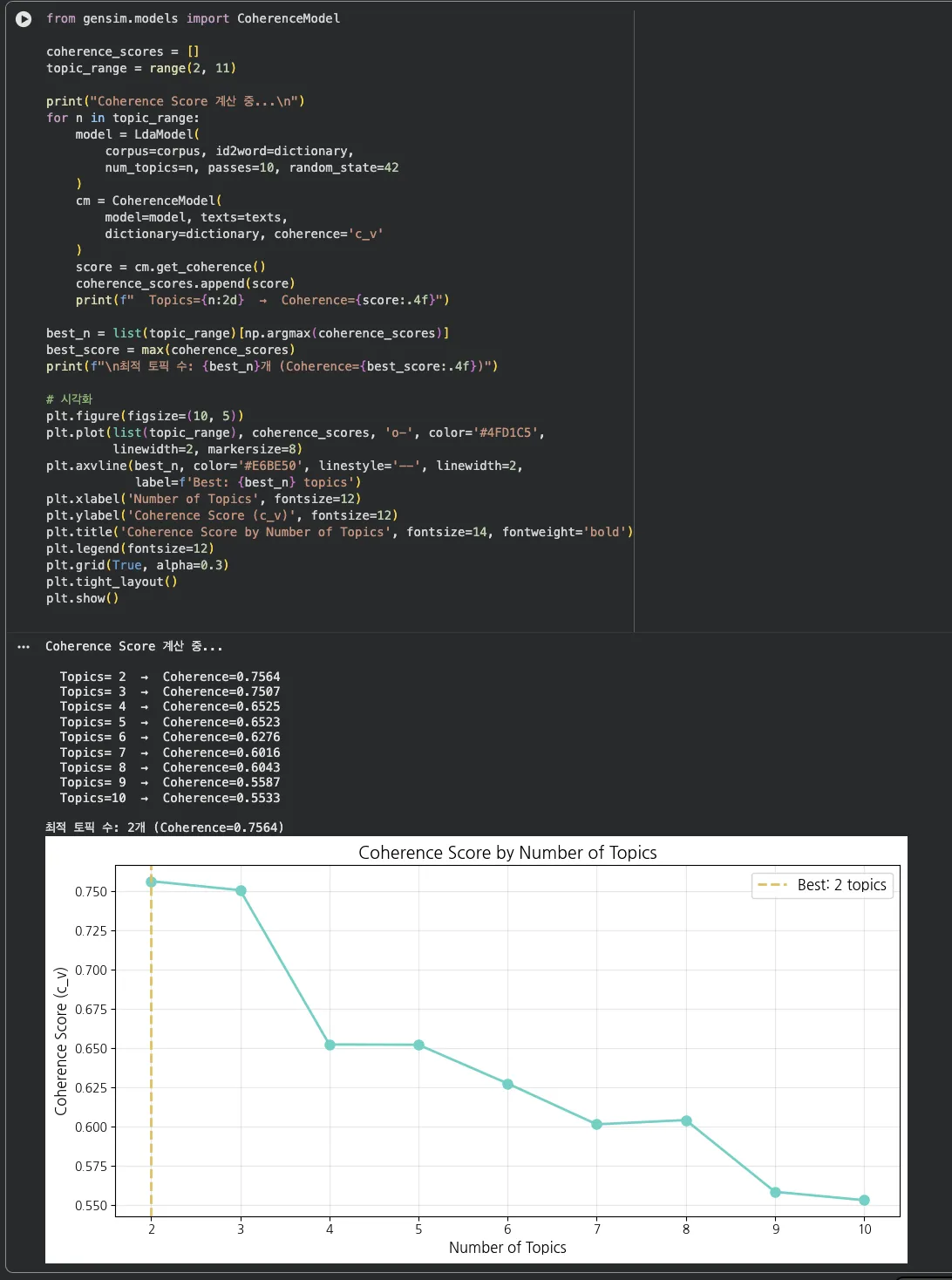
Score가 가장 높은 지점이 최적 토픽 수입니다.
데이터 특성상 크게 차이가 나지 않을 수도 있는데,
523건으로는 5~7개 범위가 적절하다는 걸 확인할 수 있었습니다.
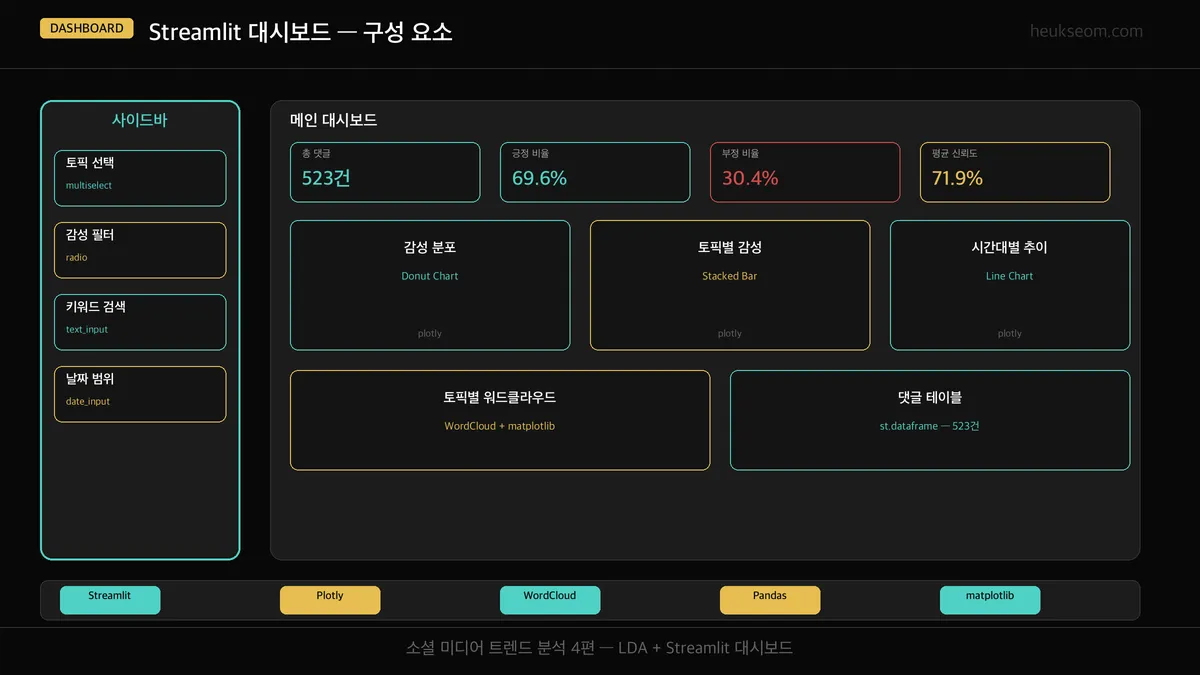
Step 6. Streamlit 대시보드는 어떻게 만들까요?
LDA 분석은 Jupyter에서 끝났으니, 이제 결과를 보여주는 대시보드를 만들 차례입니다.
Streamlit을 쓰면 Python 코드만으로 인터랙티브 웹앱을 만들 수 있습니다.
대시보드 구성 요소:
- 사이드바 — 토픽 선택, 감성 필터, 키워드 검색, 날짜 범위
- KPI 메트릭 — 총 댓글 수, 긍정/부정 비율, 평균 신뢰도
- 감성 분포 — Plotly 도넛 차트
- 토픽별 감성 — Plotly 수평 스택 바차트
- 시간대별 추이 — Plotly 라인 차트
- 워드클라우드 — matplotlib + WordCloud (한글 폰트 적용)
- 댓글 테이블 — st.dataframe으로 전체 데이터 탐색
대시보드 실행 화면
아래는 실제로 동작하는 대시보드 캡처입니다.
다크 테마 + 브랜드 컬러(민트/골드/레드) 3색을 적용했습니다.
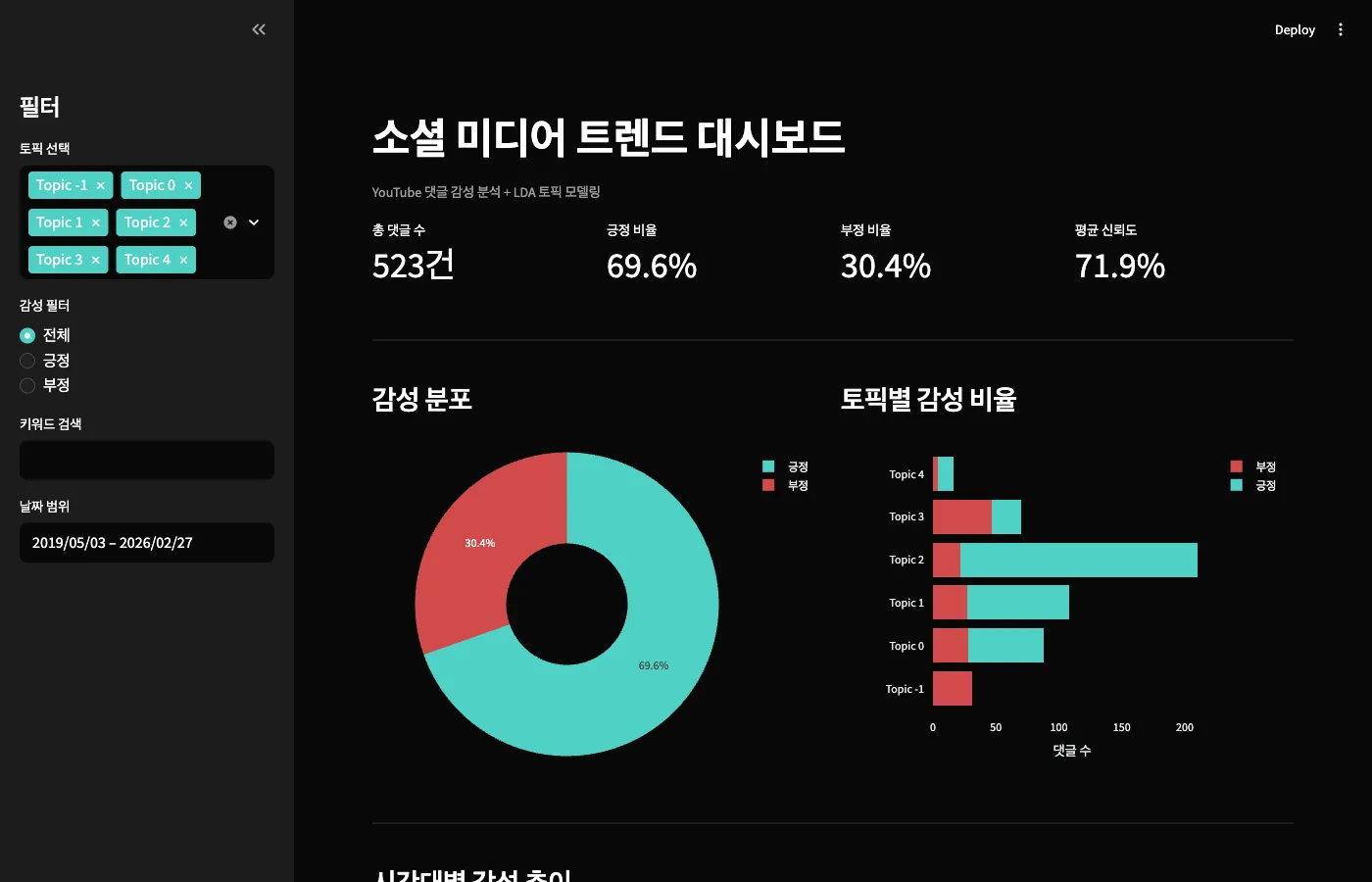
상단에는 핵심 지표 4개가 한눈에 보이고,
감성 분포 도넛 차트와 토픽별 감성 비율 바차트가 나란히 배치됩니다.
이거 하나만 열어도 "이 키워드 반응이 어떤가요?" 질문에 바로 답할 수 있습니다.
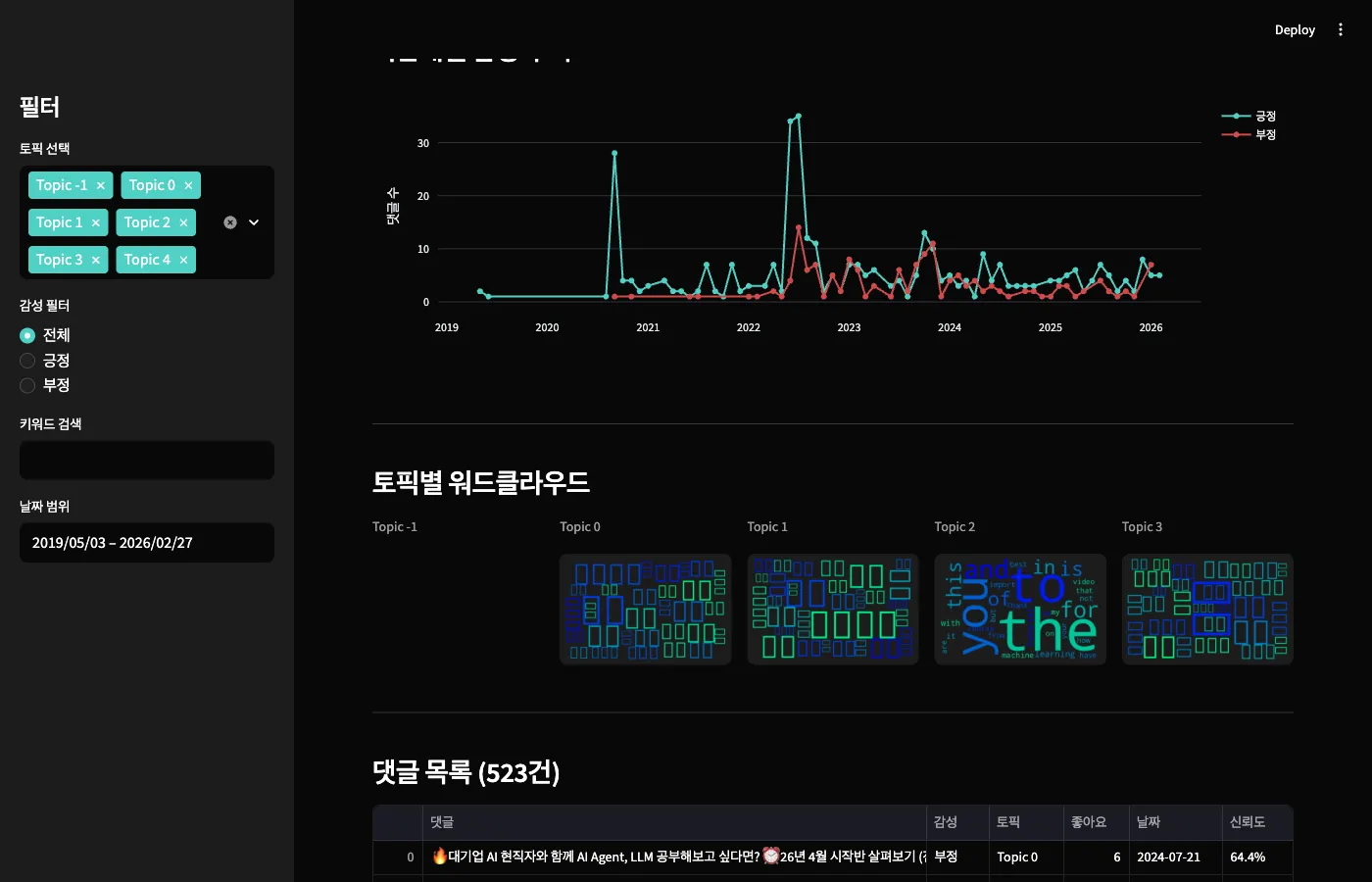
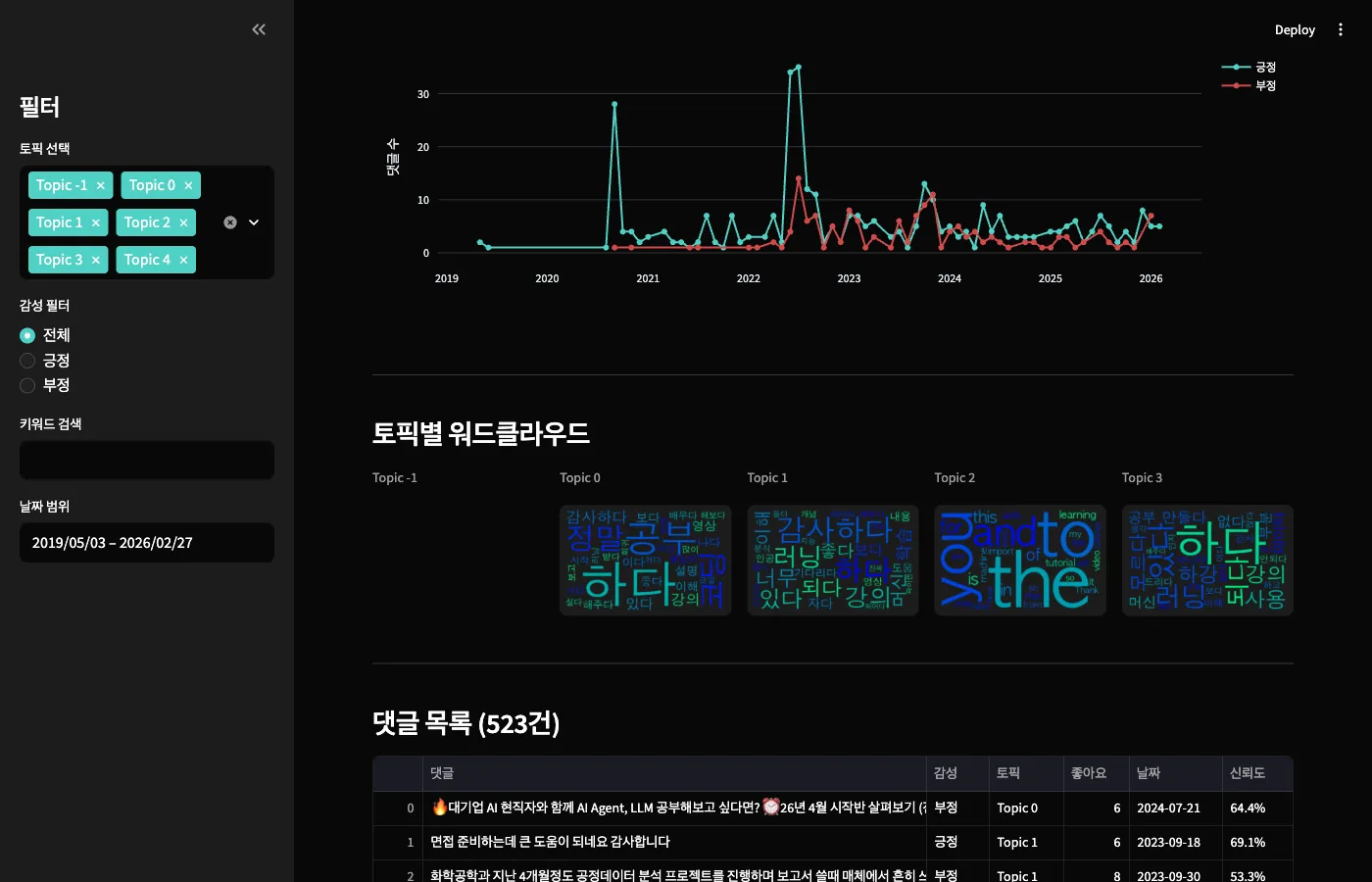
시간대별 감성 추이는 월 단위로 집계됩니다.
특정 시점에 긍정이 급증하거나 부정이 늘어나는 패턴을 확인할 수 있죠.
실제로 보면 "아, 이 시기에 뭔가 있었구나" 하는 게 바로 보입니다.
워드클라우드는 LDA에서 뽑은 토픽별 키워드를 시각화한 겁니다.
한글 폰트가 깨지지 않도록 macOS는 AppleGothic, Linux는 NanumGothic을 자동 탐지하게 했습니다.
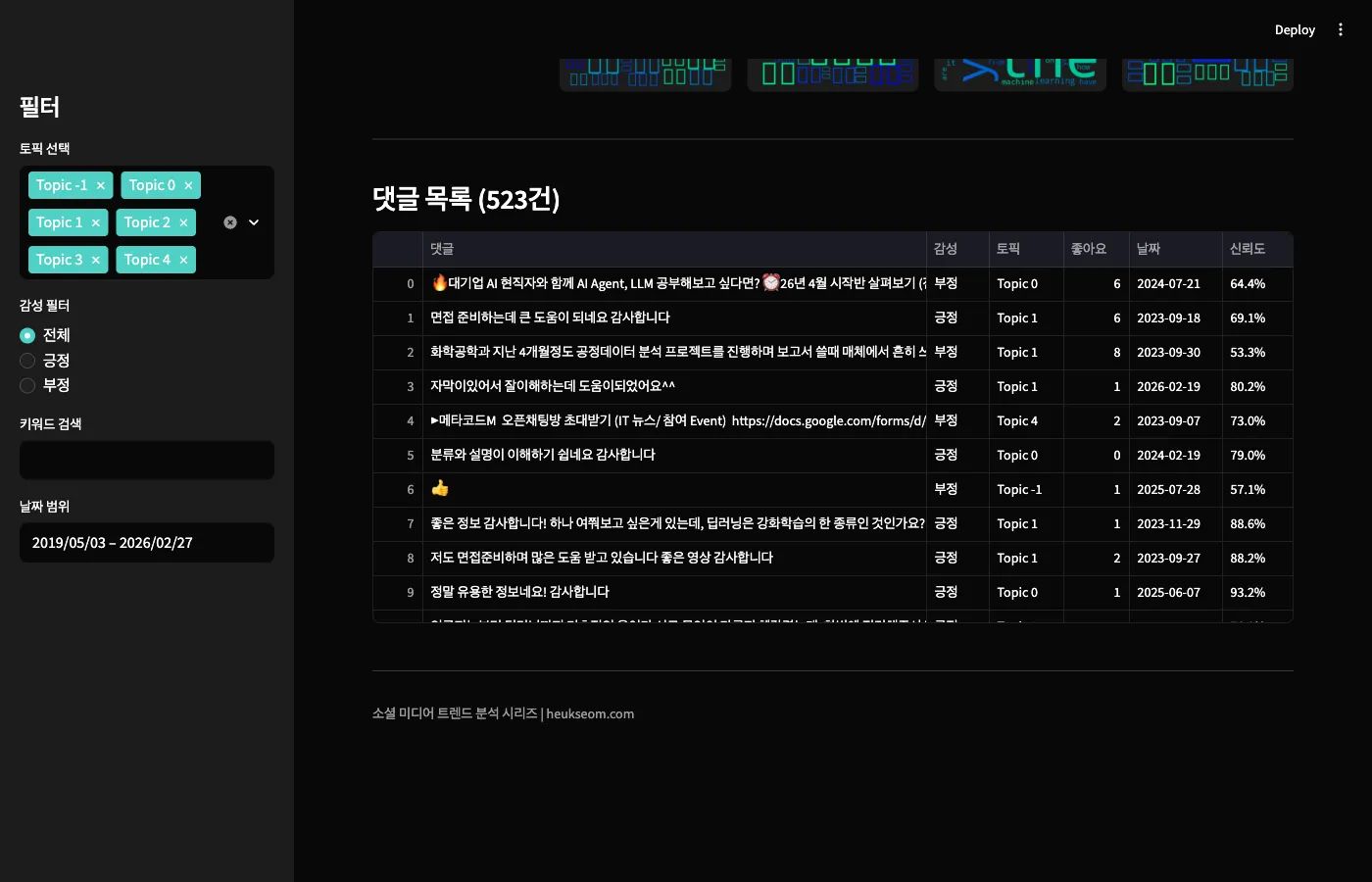
하단 테이블에서는 전체 댓글을 직접 탐색할 수 있습니다.
Streamlit의 st.dataframe은 정렬, 검색, CSV 다운로드를 기본 제공합니다.
Step 7. 필터 기능 — 데이터를 어떻게 인터랙티브하게 탐색할까요?
대시보드의 진짜 장점은 필터로 데이터를 자유롭게 잘라볼 수 있다는 겁니다.
긍정 댓글만 보기
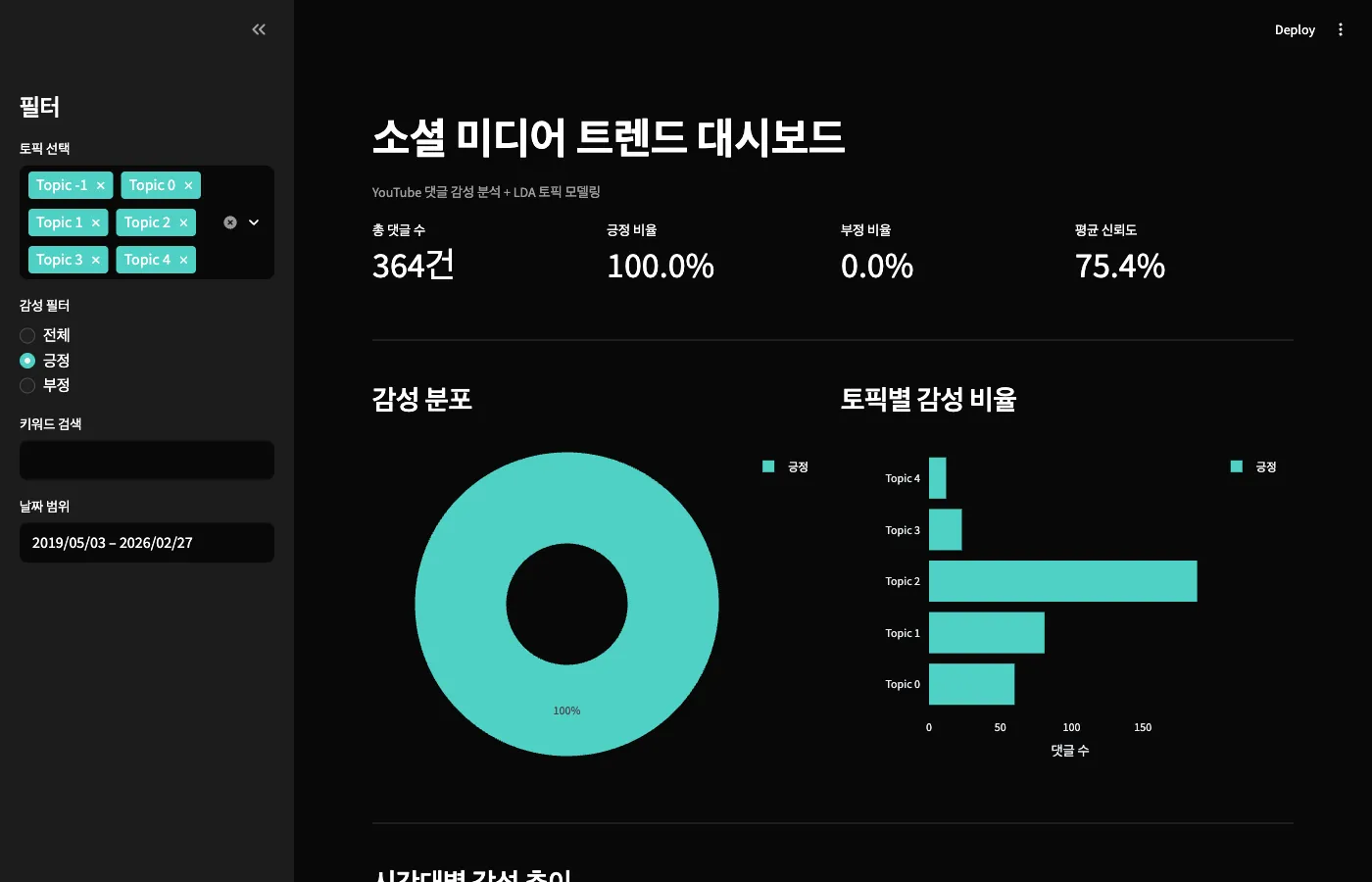
감성 필터를 "긍정"으로 바꾸면 364건만 남습니다. 평균 신뢰도가 75.4%로 올라가네요.
모델이 긍정 댓글을 좀 더 자신 있게 판단한다는 뜻이기도 합니다.
부정 댓글만 보기
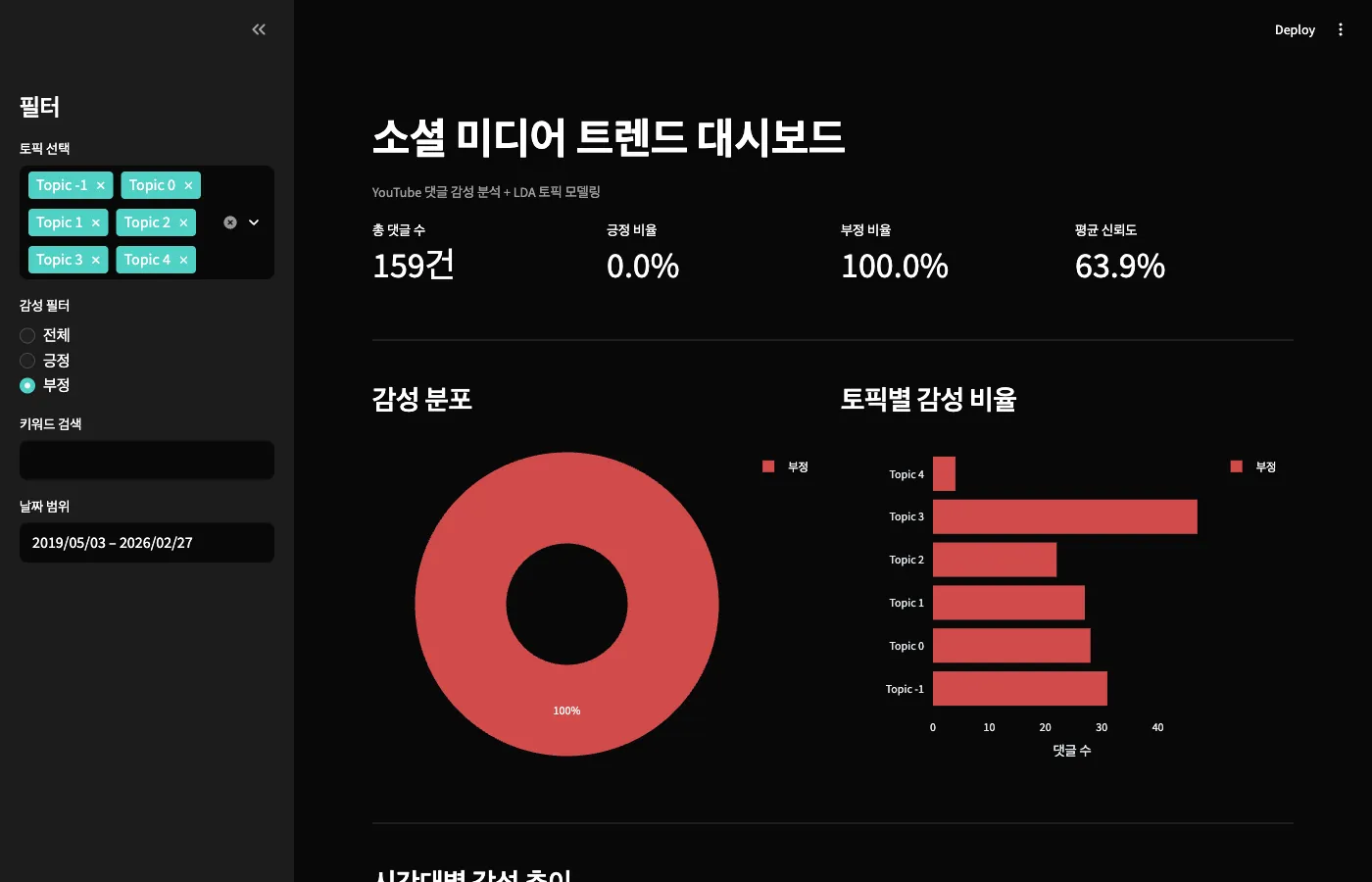
부정 댓글 159건만 보면 평균 신뢰도가 63.9%입니다.
긍정보다 모델이 덜 확신한다는 건데, 부정 표현이 더 다양하고 미묘하기 때문입니다.
키워드 검색 — "감사"
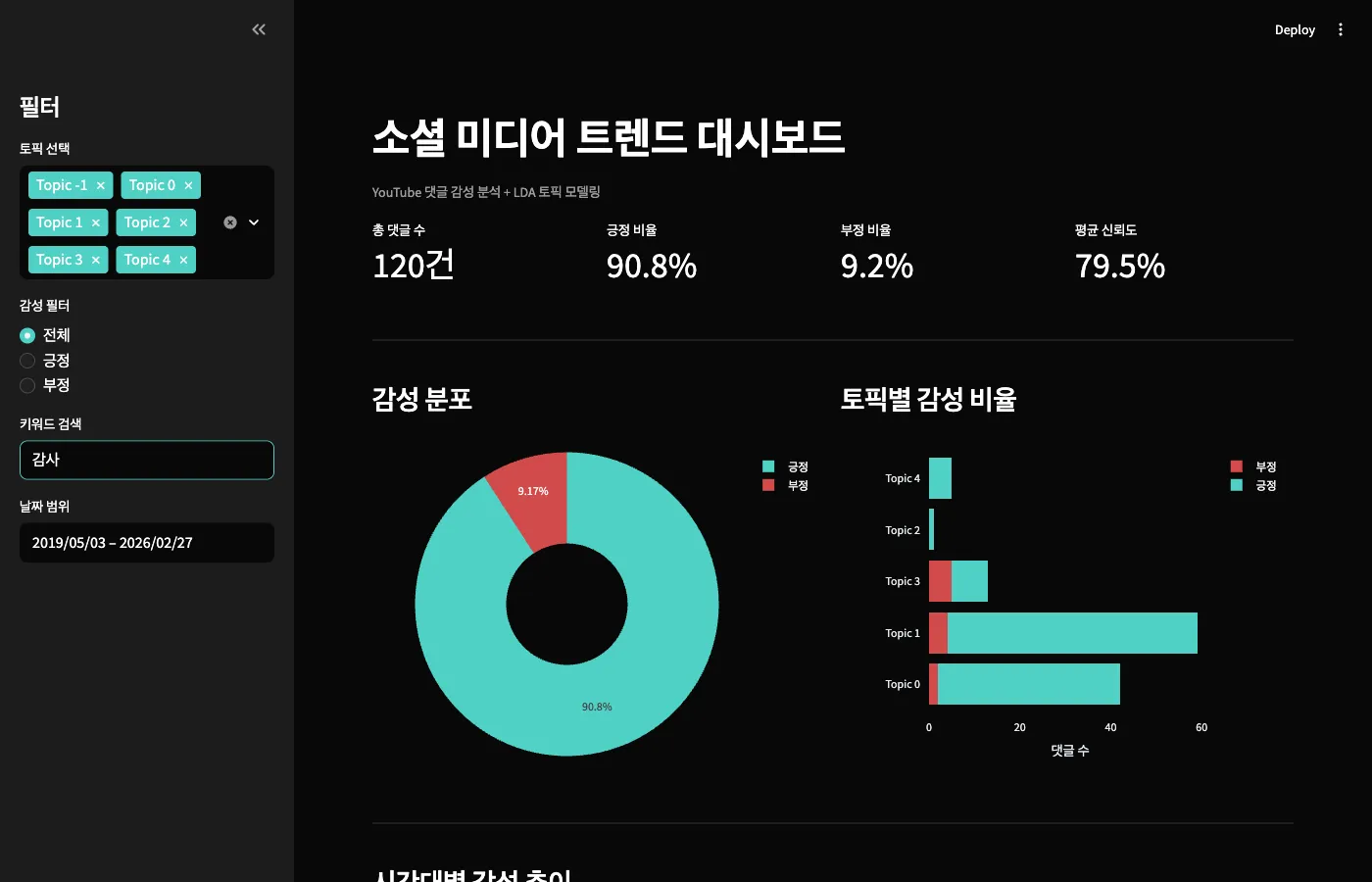
"감사" 키워드로 검색하면 120건이 나옵니다.
긍정 비율이 90.8%로 뛰어오르고, 신뢰도도 79.5%로 높습니다.
"감사"가 포함된 댓글은 거의 확실히 긍정이라는 뜻이죠.
Step 8. Streamlit Cloud에는 어떻게 배포할까요?
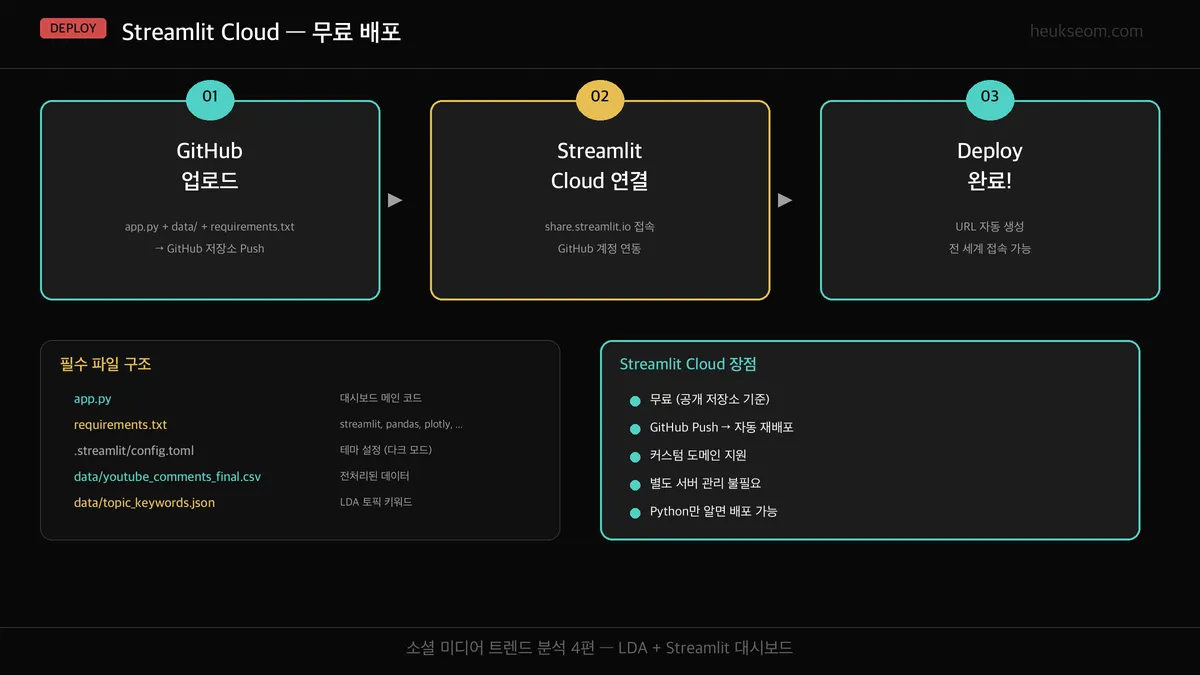
만든 대시보드를 인터넷에 공개하려면 Streamlit Cloud를 쓰면 됩니다.
공개 GitHub 저장소 기준 무료이고, 별도 서버 관리가 필요 없습니다.
배포에 필요한 파일 구조:
app.py— 대시보드 메인 코드requirements.txt— streamlit, pandas, plotly, wordcloud, matplotlib.streamlit/config.toml— 다크 테마 설정data/youtube_comments_final.csv— 전처리 완료 데이터data/topic_keywords.json— LDA 토픽 키워드
여기서 중요한 설계 포인트가 하나 있습니다.
LDA 학습(gensim, konlpy)은 Jupyter에서 미리 끝내고,
Streamlit 앱은 결과만 시각화합니다.
그래서 requirements.txt에 gensim이 없습니다 — 배포가 가볍고 빠릅니다.
정리 — 시리즈 전체 아키텍처
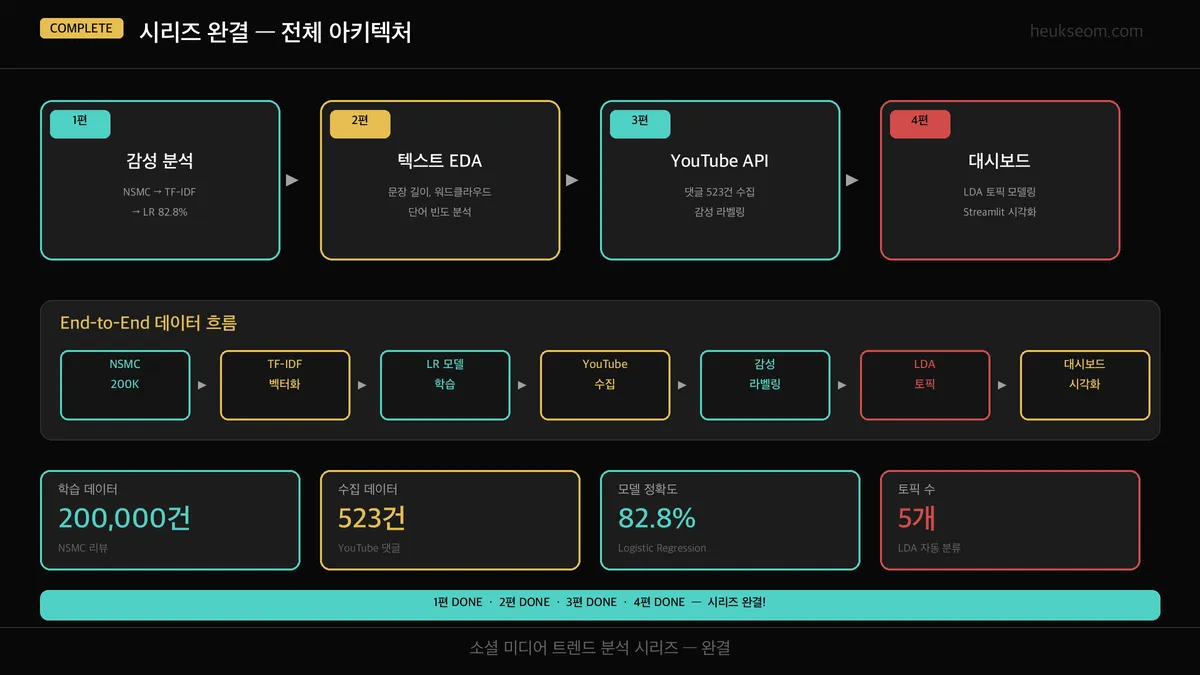
- 1편 — 감성 분석 모델: NSMC 200K건으로 TF-IDF + Logistic Regression 학습 (82.8%)
- 2편 — 텍스트 EDA: 문장 길이, 워드클라우드, 단어 빈도로 데이터 특성 파악
- 3편 — YouTube API: 실제 댓글 523건 수집 + 감성 라벨링
- 4편 — 대시보드: LDA 토픽 모델링 + Streamlit 인터랙티브 시각화
처음에 NSMC로 모델을 만들고, 그 모델로 실제 YouTube 댓글을 분석하고,
LDA로 주제까지 분류해서, 대시보드로 한눈에 보여주는 구조입니다.
"데이터 수집 → 분석 → 시각화"라는 데이터 사이언스의 기본 흐름을 그대로 따라왔습니다.
시리즈를 끝까지 따라오셨다면, 이 흐름을 다른 데이터에도 적용해볼 수 있습니다.
트위터 댓글이든, 네이버 리뷰든, 앱스토어 리뷰든 — 구조는 같습니다.